|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Notatki z wykładów, ściągawki
Ogólna teoria statystyki. Podsumowanie wykładu: krótko, najważniejsze
Katalog / Notatki z wykładów, ściągawki Spis treści
WYKŁAD nr 1. Statystyka jako nauka 1. Przedmiot i metoda statystyki jako nauk społecznych Statystyki - samodzielna nauka społeczna, posiadająca własny przedmiot i metody badań, które powstały z potrzeb życia społecznego. Statystyki jest nauką badającą ilościową stronę wszystkich zjawisk społeczno-gospodarczych. Termin „statystyka” pochodzi od łacińskiego słowa „status”, co oznacza „stanowisko, porządek”. Po raz pierwszy użył go niemiecki naukowiec G. Achenwal (1719-1772). Głównym zadaniem statystyki jest matematyczne poprawne opisanie zebranych informacji. Statystyki można nazwać specjalną sekcją matematyki, która opisuje tę lub inną stronę ludzkiego życia. Statystyka wykorzystuje różnorodne metody i techniki matematyczne, aby dana osoba mogła przeanalizować konkretny problem. Statystyki mogą stanowić nieocenioną pomoc każdemu liderowi w dowolnym przedsiębiorstwie, jeśli wiesz, jak prawidłowo z nich korzystać. Do tej pory termin „statystyka” jest używany w trzech znaczeniach: 1) specjalną gałąź praktycznej działalności osób, której celem jest gromadzenie, przetwarzanie i analizowanie danych charakteryzujących rozwój społeczno-gospodarczy kraju, jego regionów, poszczególnych sektorów gospodarki lub przedsiębiorstw; 2) nauka opracowująca przepisy teoretyczne i metody stosowane w praktyce statystycznej; 3) statystyka - dane statystyczne prezentowane w sprawozdaniach przedsiębiorstw, sektorów gospodarki, a także dane publikowane w zbiorach, różnych katalogach, biuletynach itp. Obiekt statystyk - zjawiska i procesy życia społeczno-gospodarczego społeczeństwa, w których uwidaczniają się i znajdują swój wyraz stosunki społeczno-gospodarcze ludzi. Ogólna teoria statystyki jest podstawą metodologiczną, rdzeniem wszystkich statystyk sektorowych. Rozwija ogólne zasady i metody statystycznego badania zjawisk społecznych i jest najbardziej ogólną kategorią statystyki. Zadania statystyki ekonomicznej to opracowywanie i analiza syntetycznych wskaźników, które odzwierciedlają stan gospodarki narodowej, relacje branż, specyfikę rozkładu sił wytwórczych, dostępność zasobów materialnych, pracy i środków finansowych. Statystyka społeczna opracowuje system wskaźników do scharakteryzowania sposobu życia ludności i różnych aspektów stosunków społecznych. Statystyki - nauki społeczne, które zajmują się zbieraniem informacji o różnym charakterze, ich porządkowaniem, porównywaniem, analizą i interpretacją (wyjaśnienie). Ma następujące charakterystyczne cechy: 1) bada ilościową stronę zjawisk społecznych. Ta strona zjawiska reprezentuje jego wielkość, wielkość, objętość i ma wymiar liczbowy; 2) bada jakościową stronę zjawisk masowych. Podana strona zjawiska wyraża jego specyfikę, wewnętrzną cechę odróżniającą je od innych zjawisk. Jakościowa i ilościowa strona zjawiska zawsze istnieją razem, tworzą jedną całość. Wszystkie zjawiska i wydarzenia społeczne zachodzą w czasie i przestrzeni, a w odniesieniu do każdego z nich zawsze można określić, w jakim czasie powstało i gdzie się rozwija. Statystyka bada więc zjawiska w określonych warunkach miejsca i czasu. Zjawiska i procesy życia społecznego rozumiane przez statystykę podlegają ciągłym zmianom i rozwojowi. Na podstawie gromadzenia, przetwarzania i analizy danych masowych o zmianach w badanych zjawiskach i procesach ujawnia się statystyczna prawidłowość. Prawidłowości statystyczne są wyrazem działania praw społecznych, które warunkują istnienie i rozwój stosunków społeczno-gospodarczych w społeczeństwie. Przedmiot statystyk to badanie zjawisk społecznych, dynamiki i kierunku ich rozwoju. Za pomocą wskaźników statystycznych statystyka ustala ilościową stronę zjawiska społecznego, obserwuje wzorce przejścia ilości w jakość na przykładzie danego zjawiska społecznego. Na podstawie dostarczonych obserwacji statystyka analizuje dane uzyskane w określonych warunkach miejsca i czasu. Statystyka zajmuje się badaniem zjawisk i procesów społeczno-gospodarczych o charakterze masowym, a także bada wiele czynników, które je determinują. Większość nauk społecznych posługuje się statystyką, aby wyprowadzić i potwierdzić swoje prawa teoretyczne. Wnioski wyciągane z badań statystycznych są wykorzystywane przez ekonomię, historię, socjologię, politologię i wiele innych nauk humanistycznych. Statystyka jest również potrzebna naukom społecznym do potwierdzenia ich podstaw teoretycznych, a jej rola praktyczna jest bardzo duża. Ani duże przedsiębiorstwa, ani poważne branże, opracowując strategię rozwoju gospodarczego i społecznego obiektu, nie mogą obejść się bez analizy danych statystycznych. W tym celu w przedsiębiorstwach i branżach organizowane są specjalne działy i usługi analityczne, które przyciągają specjalistów, którzy ukończyli szkolenie zawodowe w tej dziedzinie. Statystyka, jak każda inna nauka, ma pewien zestaw metod badania swojego przedmiotu. Metody statystyczne dobierane są w zależności od badanego zjawiska i konkretnego przedmiotu badań (związków, wzorców lub rozwoju). Metody w statystyce powstają łącznie z opracowanych i stosowanych konkretnych metod i technik badania zjawisk społecznych. Należą do nich obserwacja, podsumowanie i grupowanie danych, obliczanie wskaźników uogólniających w oparciu o specjalne metody (metoda średnich, wskaźników itp.). W związku z tym istnieją trzy etapy pracy z danymi statystycznymi: 1) zbiór jest masową naukowo zorganizowaną obserwacją, dzięki której uzyskuje się pierwotne informacje o poszczególnych faktach (jednostkach) badanego zjawiska. Ta statystyczna rachunkowość dużej liczby lub wszystkich jednostek składających się na badane zjawisko jest bazą informacyjną do uogólnień statystycznych, do wyciągania wniosków na temat badanego zjawiska lub procesu; 2) grupowanie i podsumowanie. Dane te rozumiane są jako rozkład zbioru faktów (jednostek) na jednorodne grupy i podgrupy, ostateczna liczba dla każdej grupy i podgrupy oraz prezentacja wyników w postaci tabeli statystycznej; 3) przetwarzanie i analiza. Analiza statystyczna kończy etap badań statystycznych. Zawiera przetwarzanie danych statystycznych uzyskanych podczas podsumowania, interpretację uzyskanych wyników w celu uzyskania obiektywnych wniosków o stanie badanego zjawiska i wzorcach jego rozwoju. W procesie analizy statystycznej badana jest struktura, dynamika i wzajemne powiązania zjawisk i procesów społecznych. Główne etapy analizy statystycznej to: 1) stwierdzenie faktów i ustalenie ich oceny; 2) identyfikację charakterystycznych cech i przyczyn zjawiska; 3) porównanie zjawiska ze zjawiskami normatywnymi, planowanymi i innymi, które są traktowane jako podstawa porównania; 4) formułowanie wniosków, prognoz, założeń i hipotez; 5) statystyczna weryfikacja proponowanych założeń (hipotez). 2. Podstawy teoretyczne i podstawowe pojęcia statystyki W przypadku metodologii statystycznej podstawą teoretyczną jest dialektyczno-materialistyczne rozumienie praw procesu rozwoju społeczeństwa. W rezultacie statystyki często posługują się takimi kategoriami jak ilość i jakość, konieczność i przypadek, prawidłowość, przyczynowość itp. Główne przepisy statystyki opierają się na prawach teorii społecznej i ekonomicznej, ponieważ uwzględniają wzorce rozwoju zjawisk społecznych, określają ich znaczenie, przyczyny i konsekwencje dla życia społeczeństwa. Z drugiej strony prawa wielu nauk społecznych są tworzone na podstawie statystyk i wzorców zidentyfikowanych za pomocą analizy statystycznej, można więc powiedzieć, że związek między statystyką a innymi naukami społecznymi jest nieskończony i ciągły. Statystyka ustanawia prawa nauk społecznych, a one z kolei korygują przepisy statystyki. Teoretyczne podstawy statystyki są również ściśle związane z matematyką, ponieważ konieczne jest wykorzystanie wskaźników matematycznych, praw i metod do mierzenia, porównywania i analizowania cech ilościowych. Dogłębne zbadanie dynamiki zjawiska, jego zmiany w czasie, a także jego relacji z innymi zjawiskami jest niemożliwe bez zastosowania wyższej matematyki i analizy matematycznej. Bardzo często badanie statystyczne opiera się na opracowanym matematycznym modelu zjawiska. Taki model teoretycznie odzwierciedla proporcje ilościowe badanego zjawiska. Jeśli jest dostępna, zadaniem statystyki jest liczbowe określenie parametrów zawartych w modelu. Przy ocenie kondycji finansowej przedsiębiorstwa często stosuje się model scoringowy A. Altmana, w którym poziom upadłości Z oblicza się według wzoru: Z=1,2x1 + 1,4x2 + 3,3x3 + 0,6x4 + 10,0x5, gdzie x1 - stosunek kapitału zwrotnego do wartości majątku spółki; x2 - stosunek niepodzielonego dochodu do wartości majątku; x3 - stosunek dochodów operacyjnych do wartości aktywów; x4 - stosunek wartości rynkowej akcji spółki do całkowitej kwoty zadłużenia; x5 - stosunek wielkości sprzedaży do wielkości aktywów. Według A. Altmana, jeśli Z < 2,675, firma jest zagrożona bankructwem, a jeśli Z > 2,675, sytuacja finansowa firmy jest nie do obaw. Aby uzyskać to oszacowanie, konieczne jest podstawienie nieznanego x do wzoru1X2X3X4 i x5, które są pewnymi wskaźnikami linii równowagi. Szczególnie rozpowszechnione w naukach statystycznych są takie działy matematyki, jak teoria prawdopodobieństwa i statystyka matematyczna. W statystyce stosuje się operacje, które są obliczane bezpośrednio przy użyciu reguł teorii prawdopodobieństwa. Jest to selektywna metoda obserwacji. Główną z tych reguł jest seria twierdzeń wyrażających prawo wielkich liczb. Istota tego prawa polega na zaniku elementu losowości we wskaźniku sumarycznym, z którym wiążą się poszczególne cechy, gdyż łączy się w nim coraz więcej z nich. Statystyka matematyczna jest również ściśle związana z teorią prawdopodobieństwa. Rozważane w nim zadania można podzielić na trzy kategorie: rozkład (struktura zbioru), powiązania (pomiędzy cechami), dynamika (zmiana w czasie). Szeroko stosowana jest analiza szeregów wariacyjnych, prognozowanie rozwoju zjawisk odbywa się za pomocą ekstrapolacji. Za pomocą analizy korelacji i regresji wprowadza się związki przyczynowe zjawisk i procesów. Wreszcie, nauka statystyczna jest wdzięczna statystyce matematycznej za jej najważniejsze kategorie i pojęcia, takie jak totalność, zmienność, znak, prawidłowość. Całość statystyczna należy do głównych kategorii statystyki i jest przedmiotem badań statystycznych, rozumianych jako systematyczne, poparte naukowo zbieranie informacji o zjawiskach społeczno-gospodarczych życia publicznego oraz analiza uzyskanych danych. Aby przeprowadzić badanie statystyczne, potrzebna jest naukowo uzasadniona baza informacji. Taką bazą informacji jest zbiór statystyczny - zbiór obiektów społeczno-ekonomicznych lub zjawisk życia społecznego, połączonych wspólnym związkiem, podstawą jakościową, ale różniących się od siebie pewnymi cechami (na przykład zbiór gospodarstw domowych, rodzin , firmy itp.). Z punktu widzenia metodologii statystycznej zbiorowość statystyczna to zbiór jednostek, które posiadają takie cechy jak jednorodność, masowość, pewna integralność, występowanie zmienności, współzależność stanu poszczególnych jednostek. Populacja statystyczna składa się więc z poszczególnych jednostek. Jednostką całości może być przedmiot, osoba, fakt, proces. Jednostka populacji jest podstawowym elementem i nośnikiem jej głównych cech. Element populacji, dla którego zbierane są dane niezbędne do badania statystycznego, nazywa się jednostką obserwacji. Liczba jednostek w populacji nazywana jest wielkością populacji. Agregatem statystycznym może być ludność w czasie spisu, przedsiębiorstwa, miasta, pracownicy firmy. Wybór populacji statystycznej i jej jednostek zależy od specyficznych uwarunkowań i charakteru badanego zjawiska lub procesu społeczno-gospodarczego. Masowość jednostek populacji jest ściśle związana z jej kompletnością. Kompletność zapewnia uwzględnienie jednostek badanej populacji statystycznej. Na przykład badacz musi wyciągnąć wnioski dotyczące rozwoju bankowości. Dlatego musi zebrać informacje o wszystkich bankach działających w regionie. Ponieważ każdy zbiór ma dość złożony charakter, przez kompletność należy rozumieć pokrycie zbioru najbardziej zróżnicowanych cech zbioru, które rzetelnie i merytorycznie opisują badane zjawisko. Jeśli np. wyniki finansowe nie są brane pod uwagę w procesie monitorowania banków, to nie można wyciągnąć ostatecznych wniosków na temat rozwoju systemu bankowego. Ponadto kompletność sugeruje badanie cech jednostek populacji przez najdłuższe możliwe okresy. Dość pełne dane są z reguły ogromne i wyczerpujące. Zjawiska społeczno-gospodarcze badane w praktyce są bardzo zróżnicowane, dlatego trudno, a czasem nawet niemożliwe jest ujęcie wszystkich zjawisk. Badacz zmuszony jest zbadać tylko część populacji statystycznej i wyciągnąć wnioski dla całej populacji. W takich sytuacjach najważniejszym wymogiem jest rozsądny dobór tej części populacji, dla której badane są cechy. Ta część powinna ukazywać główne właściwości, zjawiska i być typowa. W rzeczywistości kilka agregatów może oddziaływać jednocześnie w badanych zjawiskach i procesach. W takich sytuacjach obiekt badań znajduje się w taki sposób, aby wyraźnie wyróżnić badane populacje. Znakiem jednostki kruszywa jest jego cecha charakterystyczna, określona właściwość, cecha, jakość, którą można zaobserwować i zmierzyć. Populacja badana w czasie lub przestrzeni musi być porównywalna. W konsekwencji na charakterystykę jednostek populacji nakładane są wymagania ich porównywalności i jednorodności. W tym celu konieczne jest zastosowanie np. jednolitych kosztorysów. W celu jakościowego zbadania całości, badane są najbardziej znaczące lub powiązane ze sobą cechy. Liczba cech charakteryzujących jednostkę populacji nie powinna być nadmierna. To komplikuje zbieranie danych i przetwarzanie wyników. Charakterystyki jednostek populacji statystycznej muszą być połączone tak, aby wzajemnie się uzupełniały i były współzależne. Wymóg jednorodności populacji statystycznej oznacza wybór kryterium, według którego ta lub inna jednostka należy do badanej populacji. Na przykład, jeśli badana jest inicjatywa młodych wyborców, to konieczne jest ustalenie granic wiekowych dla takich wyborców, aby wykluczyć osoby starszego pokolenia. Możliwe jest ograniczenie takiej populacji do przedstawicieli wsi lub np. studentów. Obecność zmienności w jednostkach populacji oznacza, że ich cechy mogą otrzymywać wszelkiego rodzaju wartości lub modyfikacje w niektórych jednostkach populacji. W związku z tym takie znaki nazywane są zmiennymi, a poszczególne wartości lub modyfikacje nazywane są wariantami. Znaki dzielą się na atrybutowe i ilościowe. Znak nazywa się atrybutywnym lub jakościowym, jeśli jest wyrażony przez pojęcie semantyczne, na przykład płeć osoby lub jej przynależność do określonej grupy społecznej. Wewnętrznie dzielą się na nominalne i porządkowe. Atrybut nazywa się ilościowym, jeśli jest wyrażony jako liczba. Zgodnie z naturą zmienności znaki ilościowe dzielą się na dyskretne i ciągłe. Przykładem dyskretnej cechy jest liczba osób w rodzinie. W postaci liczb całkowitych wyrażane są z reguły warianty cech dyskretnych. Cechy ciągłe obejmują na przykład wiek, wynagrodzenie, staż pracy itp. Zgodnie z metodą pomiaru znaki są podzielone na pierwotne (obliczone) i wtórne (obliczone). Pierwotne (rozliczone) wyrażają jednostkę populacji jako całości, tj. wartości bezwzględne. Wtórne (obliczone) nie są bezpośrednio mierzone, ale obliczane (koszt, produktywność). Cechy pierwotne leżą u podstaw obserwacji populacji statystycznej, natomiast cechy wtórne są określane w procesie przetwarzania i analizy danych i reprezentują stosunek cech pierwotnych. W odniesieniu do charakteryzowanego obiektu znaki dzielą się na bezpośrednie i pośrednie. Znaki bezpośrednie to właściwości bezpośrednio związane z charakteryzowanym obiektem (wielkość produkcji, wiek osoby). Znaki pośrednie to właściwości charakterystyczne nie dla samego obiektu, ale dla innych agregatów związanych z obiektem lub w nim zawartych. W odniesieniu do czasu rozróżnia się znaki chwilowe i interwałowe. Chwilowe znaki charakteryzują badany obiekt w pewnym momencie, ustalonym przez plan badań statystycznych. Znaki interwałowe charakteryzują wyniki procesów. Ich wartości mogą występować tylko w przedziale czasowym. Oprócz znaków stan badanego obiektu lub populacji statystycznej charakteryzują wskaźniki. wskaźniki - jedno z głównych pojęć statystyki, które jest uogólnioną ilościową oceną procesów i zjawisk społeczno-gospodarczych. W zależności od funkcji docelowych wskaźniki statystyczne dzielą się na księgowe i ewaluacyjne oraz analityczne. Rachunkowość i wskaźniki szacunkowe - jest to statystyczna charakterystyka wielkości zjawisk społeczno-gospodarczych w ustalonych warunkach miejsca i czasu, tj. odzwierciedlają one wielkość dystrybucji w przestrzeni lub poziomy osiągnięte w określonym czasie. Wskaźniki analityczne służą do analizy danych badanej populacji statystycznej i scharakteryzowania specyfiki rozwoju badanych zjawisk. Jako wskaźniki analityczne w statystyce stosuje się wartości względne, średnie, wskaźniki zmienności i dynamiki, wskaźniki komunikacji. Całość wskaźników statystycznych odzwierciedlających związki zachodzące między zjawiskami tworzy system wskaźników statystycznych. Ogólnie wskaźniki i znaki w pełni charakteryzują i wyczerpująco opisują populację statystyczną, umożliwiając badaczowi przeprowadzenie pełnego badania zjawisk i procesów życia społeczeństwa ludzkiego, co jest jednym z celów nauki statystycznej. Centralną kategorią statystyki jest prawidłowość statystyczna. Prawidłowość jest ogólnie rozumiana jako wykrywalny związek przyczynowy między zjawiskami, sekwencją i powtarzalnością indywidualnych cech charakteryzujących to zjawisko. W statystyce prawidłowość rozumiana jest jako ilościowa prawidłowość zmian w czasie i przestrzeni zjawisk masowych i procesów życia społecznego w wyniku działania obiektywnych praw. W konsekwencji prawidłowość statystyczna jest charakterystyczna nie dla poszczególnych jednostek populacji, ale dla całej populacji jako całości i wyraża się tylko przy wystarczająco dużej liczbie obserwacji. Tak więc prawidłowość statystyczna objawia się jako przeciętna, społeczna, masowa prawidłowość we wzajemnym anulowaniu indywidualnych odchyleń wartości znaków w jednym lub drugim kierunku. Tak więc przejaw statystycznej prawidłowości daje nam możliwość przedstawienia ogólnego obrazu zjawiska, zbadania trendu jego rozwoju, z wyłączeniem przypadkowych, indywidualnych odchyleń. 3. Nowoczesna organizacja statystyki w Federacji Rosyjskiej Statystyka odgrywa ważną rolę w zarządzaniu rozwojem gospodarczym i społecznym kraju, ponieważ poprawność wszelkich wniosków zarządczych w dużej mierze zależy od informacji, na podstawie których jest ona sporządzana. Na wyższych szczeblach zarządzania należy brać pod uwagę tylko dokładne, wiarygodne i prawidłowo przeanalizowane dane. Badanie rozwoju gospodarczego i społecznego kraju, poszczególnych regionów, branż, firm, przedsiębiorstw prowadzone jest przez specjalnie utworzone organy wchodzące w skład służby statystycznej. W Federacji Rosyjskiej funkcje służby statystycznej pełnią resortowe organy statystyczne i państwowe organy statystyczne. Najwyższym organem zarządzającym statystyką jest Państwowy Komitet Statystyczny Federacji Rosyjskiej. Rozwiązuje główne zadania stojące obecnie przed rosyjską statystyką, zapewnia całościową metodologiczną podstawę rachunkowości, konsoliduje i analizuje otrzymane informacje, podsumowuje dane i publikuje wyniki swojej działalności. Państwowy Komitet Statystyczny Federacji Rosyjskiej (Goskomstat Rosji) został powołany zgodnie z dekretem Prezydenta Federacji Rosyjskiej z dnia 6 grudnia 1999 r. Nr 1600 „W sprawie przekształcenia Rosyjskiej Agencji Statystycznej w Państwowy Komitet Federacji Rosyjskiej w sprawie statystyki”. Państwowy Komitet Statystyczny Federacji Rosyjskiej jest federalnym organem wykonawczym odpowiedzialnym za koordynację międzysektorową i regulację funkcjonalną w dziedzinie statystyki państwowej. Państwowy Komitet Statystyczny Federacji Rosyjskiej pełni następujące funkcje: 1) prowadzi gromadzenie, przetwarzanie, ochronę i przechowywanie informacji statystycznych, przestrzeganie tajemnicy państwowej i handlowej, niezbędną poufność danych; 2) zapewnia funkcjonowanie Jednolitego Państwowego Rejestru Przedsiębiorstw i Organizacji (EGRPO) na podstawie rozliczania wszystkich podmiotów gospodarczych na terytorium Federacji Rosyjskiej z przypisaniem im kodów identyfikacyjnych, na podstawie ogólnorosyjskich klasyfikatorów informacje techniczne, gospodarcze i społeczne; 3) opracować naukową metodologię statystyczną, która odpowiada potrzebom społeczeństwa na obecnym etapie, a także standardy międzynarodowe; 4) sprawdza zgodność wszystkich podmiotów prawnych i innych podmiotów gospodarczych z prawem Federacji Rosyjskiej, decyzjami Prezydenta Federacji Rosyjskiej, Rządu Federacji Rosyjskiej w sprawie statystyki; 5) wydaje uchwały i instrukcje w sprawach statystycznych, które są wiążące dla wszystkich podmiotów prawnych i innych podmiotów gospodarczych znajdujących się na terytorium Federacji Rosyjskiej. Zbiór metod wskaźników statystycznych, metod i form zbierania i przetwarzania danych statystycznych przyjęty przez Państwowy Komitet Statystyczny Rosji jest oficjalnymi standardami statystycznymi Federacji Rosyjskiej. Goskomstat Rosji w swojej głównej działalności kieruje się federalnymi programami statystycznymi, które są tworzone z uwzględnieniem propozycji federalnych władz wykonawczych i ustawodawczych, władz państwowych podmiotów Federacji Rosyjskiej, organizacji naukowych i innych i są zatwierdzane przez Goskomstat Rosji w porozumieniu z Rządem Federacji Rosyjskiej. Głównymi zadaniami krajowych organów statystycznych jest zapewnienie jawności i dostępności ogólnych (nie indywidualnych) informacji, a także gwarantowanie rzetelności, prawdziwości i dokładności uwzględnianych danych. Ponadto zadania Państwowego Komitetu Statystycznego Rosji to: 1) przekazywanie oficjalnych informacji statystycznych Prezydentowi Federacji Rosyjskiej, Zgromadzeniu Federalnemu Federacji Rosyjskiej, Rządowi Federacji Rosyjskiej, federalnym organom wykonawczym, opinii publicznej oraz organizacjom międzynarodowym; 2) opracowanie potwierdzonej naukowo metodologii statystycznej, odpowiadającej potrzebom społeczeństwa na obecnym etapie, a także standardom międzynarodowym; 3) koordynowanie działalności statystycznej federalnych władz wykonawczych i władz wykonawczych podmiotów Federacji Rosyjskiej, określanie warunków stosowania przez te władze oficjalnych standardów statystycznych przy prowadzeniu sektorowych (departamentowych) obserwacji statystycznych; 4) opracowywanie i analiza informacji ekonomicznych i statystycznych, przygotowanie niezbędnych obliczeń bilansowych i rachunków narodowych; 5) zagwarantowanie pełnej i naukowo uzasadnionej informacji statystycznej; 6) zapewnienie wszystkim użytkownikom równego dostępu do otwartych informacji statystycznych poprzez rozpowszechnianie oficjalnych raportów o sytuacji społeczno-gospodarczej Federacji Rosyjskiej, podmiotów Federacji Rosyjskiej, branż i sektorów gospodarki, publikowanie zbiorów statystycznych i innych materiałów statystycznych. W wyniku reformy gospodarki Federacji Rosyjskiej zmieniła się również struktura organów statystycznych. Zlikwidowano rejonowe powiatowe rejestry statystyczne i utworzono międzyokręgowe wydziały statystyczne, będące przedstawicielstwami terytorialnych urzędów statystycznych. Organizacja urzędów statystycznych w Rosji znajduje się obecnie na etapie reform. Jak wspomniano powyżej, obecnie nauka statystyczna w Rosji przechodzi pewne zmiany. Można zauważyć główne kierunki, w których należy przeprowadzić reformy: 1) konieczne jest przestrzeganie podstawowej ustawy o rachunkowości statystycznej – jawności i dostępności informacji przy zachowaniu poufności poszczególnych wskaźników (tajemnicy handlowej); 2) konieczne jest zreformowanie podstaw metodologicznych i organizacyjnych statystyki: zmiana ogólnych zadań i zasad zarządzania gospodarczego prowadzi do zmiany teoretycznych zapisów nauki; 3) przejście do statystyki rynkowej rodzi potrzebę doskonalenia systemu zbierania i przetwarzania informacji poprzez wprowadzenie takich form obserwacji jak kwalifikacje, rejestry (rejestry), spisy ludności itp.; 4) konieczna jest zmiana (ulepszenie) metodologii obliczania niektórych wskaźników statystycznych charakteryzujących stan gospodarki Federacji Rosyjskiej, biorąc pod uwagę międzynarodowe standardy, zagraniczne doświadczenia w rachunkowości statystycznej, konieczne jest usystematyzowanie wszystkich wskaźników i uporządkować je zgodnie z aktualnymi problemami i wymogami, z uwzględnieniem systemu rachunków narodowych (SNA); 5) konieczne jest zapewnienie relacji wskaźników statystycznych charakteryzujących poziom rozwoju życia publicznego kraju; 6) należy uwzględnić trendy w informatyzacji. W toku reformy nauki statystycznej należy stworzyć ujednoliconą bazę (system) informacyjną, która obejmie bazy informacyjne wszystkich organów statystycznych znajdujących się na niższym poziomie hierarchicznej drabiny organizacji statystyki państwowej. W związku z tym w Rosji wciąż zachodzą zmiany strukturalne, które wpływają na wszystkie sfery życia publicznego kraju. Ponieważ statystyki odnoszą się bezpośrednio do prawie wszystkich tych obszarów, proces reform również ich nie ominął. Obecnie włożono dużo pracy w organizację pracy organów statystycznych, ale nie została ona jeszcze zakończona, a wiele uwagi należy poświęcić doskonaleniu tej bardzo istotnej dla państwa instytucji informacyjnej. Obok państwowych służb statystycznych istnieje statystyka resortowa, która jest prowadzona w ministerstwach, departamentach, przedsiębiorstwach, stowarzyszeniach i firmach różnych sektorów gospodarki. Statystyka wydziałowa zajmuje się gromadzeniem, przetwarzaniem i analizą informacji statystycznych. Informacje te są niezbędne kierownictwu do podejmowania decyzji zarządczych, planowania działań organizacji lub władzy. W małych firmach praca ta jest zwykle wykonywana albo przez głównego księgowego, albo bezpośrednio przez samego kierownika. W dużych przedsiębiorstwach, które mają własną rozgałęzioną strukturę regionalną lub mają dużą liczbę pracowników, w przetwarzanie i analizę informacji statystycznych zaangażowane są całe działy lub działy. W prace takie angażują się specjaliści z dziedziny statystyki, matematyki, rachunkowości i analiz ekonomicznych, menedżerowie i technolodzy. Taki zespół, uzbrojony w nowoczesną technologię komputerową, oparty na metodologii proponowanej przez teorię statystyki i wykorzystujący nowoczesne metody analizy, pomaga budować skuteczne strategie rozwoju przedsiębiorstw, a także skutecznie kształtować działania władz publicznych. Zarządzanie złożonymi systemami społeczno-gospodarczymi jest niemożliwe bez pełnych, wiarygodnych i aktualnych informacji statystycznych. Organy statystyki państwowej i resortowej stoją zatem przed bardzo istotnym zadaniem teoretycznego uzasadnienia objętości i składu informacji statystycznych, odpowiadającego współczesnym warunkom rozwoju gospodarczego, przyczyniającego się do racjonalizacji systemu rachunkowości i statystyki oraz minimalizacji kosztów wykonywania tę funkcję. WYKŁAD nr 2. Obserwacja statystyczna 1. Pojęcie obserwacji statystycznej, etapy jej realizacji Dogłębne, kompleksowe badanie dowolnego procesu gospodarczego lub społecznego obejmuje pomiar jego ilościowej strony i scharakteryzowanie jego jakościowej istoty, miejsca, roli i relacji w ogólnym systemie stosunków społecznych. Zanim zaczniesz stosować statystyczne metody badania zjawisk i procesów życia społecznego, musisz mieć do dyspozycji wyczerpującą bazę informacyjną, która w pełni i rzetelnie opisuje przedmiot badań. Proces badań statystycznych obejmuje następujące etapy: 1) zbieranie informacji o statystyce (obserwacja statystyczna) i ich pierwotne przetwarzanie; 2) grupowanie i późniejsze przetwarzanie danych uzyskanych w wyniku obserwacji statystycznych, na podstawie ich podsumowania i grupowania; 3) uogólnienie i analiza wyników opracowania materiałów statystycznych, formułowanie wniosków i rekomendacji na podstawie wyników całego badania statystycznego. Dlatego obserwacja statystyczna jest pierwsza oraz początkowy etap badania statystycznego. Obserwacja statystyczna - proces zbierania danych pierwotnych o różnych zjawiskach życia społecznego i gospodarczego. Oznacza to, że obserwacje statystyczne powinny być zorganizowane zgodnie z planem, masowe i systematyczne. Prawidłowość obserwacji statystycznych polega na tym, że jest ona prowadzona według specjalnie opracowanego planu, który zawiera zagadnienia związane z organizacją i techniką zbierania informacji statystycznych, kontrolowaniem jej wiarygodności i jakości oraz prezentacją materiałów końcowych. Masowy charakter obserwacji statystycznych zapewnia najpełniejszy zakres wszystkich przypadków manifestacji badanego zjawiska lub procesu, tj. cechy ilościowe i jakościowe są mierzone i rejestrowane nie przez poszczególne jednostki badanej populacji, ale przez całą masa jednostek populacji w procesie obserwacji statystycznej. Systematyczny charakter obserwacji statystycznych nie powinien być spontaniczny. Prace związane z takim monitorowaniem powinny być prowadzone w sposób ciągły lub regularnie, w regularnych odstępach czasu. Proces przygotowania obserwacji statystycznej polega na ustaleniu celu i przedmiotu obserwacji, wyborze jednostki obserwacji, składu cech, które mają być rejestrowane. Do zbierania danych niezbędne jest opracowanie formularzy dokumentów oraz dobór środków i metod ich pozyskiwania. W konsekwencji obserwacja statystyczna jest pracochłonną i żmudną pracą, wymagającą zaangażowania wykwalifikowanego personelu, jej kompleksowej organizacji, planowania, przygotowania i wdrożenia. 2. Rodzaje i metody obserwacji statystycznych Obserwacja statystyczna to proces, który z punktu widzenia swojej organizacji może mieć różnorodne metody, formy i rodzaje postępowania. Zadaniem ogólnej teorii statystyki jest określenie istoty metod, form i rodzajów obserwacji w celu podjęcia decyzji gdzie, kiedy i jakie metody obserwacji będą stosowane. Obserwacje statystyczne dzielą się na dwie główne grupy: 1) pokrycie jednostek ludności; 2) czas rejestracji faktów. Ze względu na stopień pokrycia badanej populacji obserwację statystyczną dzieli się na dwa typy: ciągłą i nieciągłą. Obserwacja ciągła (pełna) dotyczy pokrycia wszystkich jednostek badanej populacji. Ciągła obserwacja zapewnia kompletność informacji o badanych zjawiskach i procesach. Ten rodzaj obserwacji wiąże się z wysokimi kosztami pracy i zasobów materialnych. Zbieranie i przetwarzanie całej ilości niezbędnych informacji wymaga znacznego czasu, więc potrzeba informacji operacyjnych nie jest zaspokojona. Często ciągła obserwacja jest w ogóle niemożliwa (np. gdy badana populacja jest zbyt duża lub nie ma możliwości uzyskania informacji o wszystkich jednostkach populacji). W rezultacie dokonywane są obserwacje nieciągłe. Pod obserwacją nieciągłą rozumie się tylko pokrycie pewnej części badanej populacji. Prowadząc obserwację nieciągłą należy z góry określić, jaka część badanej populacji zostanie poddana obserwacji i jakie kryterium będzie podstawą dla próby. Zaletą organizacji obserwacji nieciągłej jest to, że jest ona przeprowadzana w krótkim czasie, wiąże się z najniższymi kosztami robocizny i materiałów, a uzyskane informacje mają charakter operacyjny. Istnieje kilka rodzajów obserwacji nieciągłych: selektywna; obserwacja głównej tablicy; monograficzny. Selektywna obserwacja rozumiana jest jako część jednostek badanej populacji, wyselekcjonowana metodą doboru losowego. Przy odpowiedniej organizacji obserwacja próby daje dość dokładne wyniki, które można rozszerzyć z prawdopodobieństwem warunkowym na całą populację. Metoda obserwacji chwilowych nazywana jest obserwacją selektywną, która polega na selekcji nie tylko jednostek badanej populacji (próbkowanie w przestrzeni), ale także punktów w czasie, w których dokonywana jest rejestracja znaków (próbkowanie w czasie). Obserwacja głównego układu polega na objęciu badaniem niektórych, najbardziej znaczących cech jednostek populacji. Przy takiej obserwacji brane są pod uwagę największe jednostki populacji i rejestrowane są najważniejsze cechy dla tego badania. Na przykład ankietowanych jest 15-20% dużych instytucji kredytowych, a zawartość ich portfeli inwestycyjnych jest rejestrowana. Obserwacja monograficzna charakteryzuje się kompleksowym i kompletnym badaniem tylko niektórych jednostek populacji, które mają pewne szczególne cechy lub reprezentują jakieś nowe zjawisko. Celem takiej obserwacji jest identyfikacja istniejących lub dopiero pojawiających się trendów rozwoju danego procesu lub zjawiska. W badaniu monograficznym szczegółowemu badaniu poddawane są poszczególne jednostki populacji, co pozwala odnotować bardzo ważne zależności i proporcje, których nie możemy znaleźć przy innych, mniej szczegółowych obserwacjach. Badania statystyczno-monograficzne są często wykorzystywane w medycynie, przy badaniu budżetów rodzinnych itp. Należy zauważyć, że badania monograficzne są ściśle powiązane z badaniami ciągłymi i wybiórczymi. Po pierwsze, potrzebne są dane z badań masowych, aby wybrać kryterium doboru jednostek populacji do obserwacji nieciągłych i monograficznych. Po drugie, obserwacja monograficzna pozwala zidentyfikować charakterystyczne cechy i istotne cechy przedmiotu badań, wyjaśnić strukturę badanej populacji. Wyniki mogą posłużyć jako podstawa do zorganizowania nowego badania masowego. W zależności od czasu rejestracji faktów obserwacja może być ciągła i nieciągła. Z kolei monitorowanie nieciągłe obejmuje okresowe i jednorazowe. Obserwacja ciągła (bieżąca) realizowana jest poprzez ciągłą rejestrację faktów w miarę ich udostępniania. Dzięki takiej obserwacji śledzone są wszystkie zmiany w badanych procesach i zjawiskach, co umożliwia monitorowanie ich dynamiki. Na przykład urzędy stanu cywilnego rejestrują w sposób ciągły zgony, urodzenia i małżeństwa. Przedsiębiorstwa prowadzą bieżącą ewidencję wydań materiałów z magazynu, produkcji itp. Obserwację nieciągłą prowadzi się albo systematycznie, w stałych odstępach czasu (obserwacja okresowa), albo jednorazowo i nieregularnie w miarę potrzeb (obserwacja jednorazowa). Obserwacje okresowe opierają się zwykle na podobnym programie i narzędziach, aby wyniki takich badań były porównywalne. Przykładami obserwacji okresowych mogą być spis ludności prowadzony w dość długich odstępach czasu oraz wszelkie formy obserwacji statystycznych, które są roczne, półroczne, kwartalne, miesięczne. Specyfika obserwacji jednorazowej polega na tym, że fakty są rejestrowane nie w związku z ich wystąpieniem, ale według ich stanu lub obecności w określonym momencie lub w okresie czasu. Pomiar ilościowy oznak zjawiska lub procesu ma miejsce w czasie badania, a ponowna rejestracja znaków może w ogóle nie zostać przeprowadzona lub termin jej wdrożenia nie jest z góry określony. Przykładem jednorazowej obserwacji jest jednorazowe badanie stanu budownictwa mieszkaniowego, które zostało przeprowadzone w 2000 roku. Wraz z rodzajami obserwacji statystycznych ogólna teoria statystyki uwzględnia metody pozyskiwania informacji statystycznych, z których najważniejsze to dokumentacyjna metoda obserwacji; metoda bezpośredniej obserwacji; wywiad. Obserwacja dokumentacyjna opiera się na wykorzystaniu jako źródła informacji danych z różnych dokumentów, takich jak rejestry księgowe. Biorąc pod uwagę, że z reguły wypełnianiu takich dokumentów stawiane są wysokie wymagania, odzwierciedlone w nich dane mają najbardziej wiarygodny charakter i mogą służyć jako wysokiej jakości materiał źródłowy do analizy. Obserwację bezpośrednią prowadzi się poprzez rejestrację faktów osobiście ustalonych przez rejestratorów w wyniku oględzin, pomiarów i liczenia oznak badanego zjawiska. W ten sposób rejestrowane są ceny towarów i usług, dokonywane są pomiary czasu pracy, inwentaryzacja stanów magazynowych itp. Badanie opiera się na pozyskaniu danych od respondentów (uczestników badania). Ankietę stosuje się w przypadkach, gdy nie można przeprowadzić obserwacji innymi metodami. Ten rodzaj obserwacji jest typowy dla prowadzenia różnych badań socjologicznych i sondaży opinii publicznej. Informacje statystyczne można uzyskać za pomocą różnych rodzajów badań: ekspedycyjnych; korespondent; kwestionariusz; sekret. Badanie ekspedycyjne (ustne) realizowane jest przez specjalnie przeszkolonych pracowników (rejestratorów), którzy odnotowują odpowiedzi respondentów w formularzach obserwacyjnych. Formularz jest formą dokumentu, w którym należy wypełnić pola odpowiedzi. Metoda korespondencyjna zakłada, że personel respondenta na zasadzie dobrowolności przekazuje informacje bezpośrednio do organu monitorującego. Wadą tej metody jest trudność w weryfikacji poprawności otrzymanych informacji. W metodzie ankietowej respondenci wypełniają ankiety (kwestionariusze) dobrowolnie iw większości anonimowo. Ponieważ ta metoda pozyskiwania informacji nie jest wiarygodna, jest stosowana w tych badaniach, w których nie jest wymagana wysoka dokładność wyników. W niektórych sytuacjach wystarczą przybliżone wyniki, które oddają jedynie trend i rejestrują pojawianie się nowych faktów i zjawisk. Tajna metoda polega na przekazywaniu informacji organom prowadzącym monitoring, w tajemnicy. W ten sposób rejestrowane są akty stanu cywilnego – małżeństwa, rozwody, zgony, narodziny itp. Poza rodzajami i metodami obserwacji statystycznej teoria statystyki uwzględnia również formy obserwacji statystycznej: sprawozdawczość; specjalnie zorganizowana obserwacja statystyczna; rejestry. Raportowanie statystyczne - główna forma obserwacji statystycznej, która charakteryzuje się tym, że urzędy statystyczne otrzymują informacje o badanych zjawiskach w formie specjalnych dokumentów składanych przez przedsiębiorstwa i organizacje w określonych ramach czasowych i w określonej formie. Same formy sprawozdawczości statystycznej, metody zbierania i przetwarzania danych statystycznych, metodologia wskaźników statystycznych ustanowionych przez Państwowy Komitet Statystyczny Rosji są oficjalnymi standardami statystycznymi Federacji Rosyjskiej i są obowiązkowe dla wszystkich podmiotów public relations. Raportowanie statystyczne dzieli się na specjalistyczne i standardowe. Skład wskaźników raportowania standardowego jest taki sam dla wszystkich przedsiębiorstw i organizacji, natomiast skład wskaźników raportowania specjalistycznego zależy od specyfiki poszczególnych sektorów gospodarki i obszarów działalności. W zależności od terminu składania raportów, sprawozdawczość statystyczna jest dzienna, tygodniowa, dziesięciodniowa, dwutygodniowa, miesięczna, kwartalna, półroczna i roczna. Sprawozdawczość statystyczna może być przekazywana telefonicznie, kanałami komunikacji, na nośnikach elektronicznych z obowiązkowym późniejszym przedłożeniem na papierze, poświadczonym podpisem osób odpowiedzialnych. Specjalnie zorganizowana obserwacja statystyczna to zbiór informacji organizowany przez urzędy statystyczne, albo w celu badania zjawisk nieobjętych raportowaniem, albo w celu dokładniejszego zbadania raportowanych danych, ich weryfikacji i udoskonalenia. Różnego rodzaju spisy, jednorazowe ankiety to specjalnie zorganizowane obserwacje. Rejestry - to forma obserwacji, w której na bieżąco rejestrowane są fakty dotyczące stanu poszczególnych jednostek populacji. Obserwując jednostkę populacji przyjmuje się, że zachodzące tam procesy mają początek, długotrwałą kontynuację i koniec. W rejestrze każda jednostka obserwacji charakteryzuje się zestawem wskaźników. Wszystkie wskaźniki są przechowywane do momentu, gdy jednostka obserwowana znajdzie się w rejestrze i nie zakończyła swojego istnienia. Niektóre wskaźniki pozostają niezmienione, dopóki jednostka obserwacji jest w rejestrze, inne mogą się od czasu do czasu zmieniać. Przykładem takiego rejestru jest ujednolicony państwowy rejestr przedsiębiorstw i organizacji (USRE). Wszystkie prace związane z jego utrzymaniem wykonuje Państwowy Komitet Statystyczny Rosji. Tak więc wybór rodzajów, metod i form obserwacji statystycznych zależy od wielu czynników, z których głównymi są cele i zadania obserwacji, specyfika obserwowanego obiektu, pilność przedstawienia wyników, dostępność przeszkolonego personelu , możliwość korzystania z technicznych środków gromadzenia i przetwarzania danych. 3. Zagadnienia programowe i metodologiczne obserwacji statystycznej Jednym z najważniejszych zadań, które należy rozwiązać przygotowując obserwację statystyczną, jest określenie celu, przedmiotu i jednostki obserwacji. Celem niemal każdej obserwacji statystycznej jest uzyskanie rzetelnych informacji o zjawiskach i procesach życia społecznego w celu identyfikacji wzajemnych relacji czynników, oceny skali zjawiska i wzorców jego rozwoju. Wychodząc z zadań obserwacji ustala się jej program i formy organizacji. Oprócz celu konieczne jest ustalenie przedmiotu obserwacji, czyli ustalenie, co dokładnie ma być obserwowane. Przedmiotem obserwacji jest całokształt zjawisk lub procesów społecznych, które należy badać. Przedmiotem obserwacji może być zbiór instytucji (kredytowych, edukacyjnych itp.), ludność, fizyczne obiekty budynku, transport, wyposażenie). Przy ustalaniu przedmiotu obserwacji ważne jest ścisłe i dokładne określenie granic badanej populacji. W tym celu konieczne jest jasne ustalenie zasadniczych cech, na podstawie których ustala się, czy obiekt należy włączyć do agregatu, czy nie. Na przykład przed przeprowadzeniem badania placówek medycznych w celu zapewnienia nowoczesnego sprzętu konieczne jest określenie kategorii, przynależności departamentalnej i terytorialnej badanych klinik. Przy definiowaniu przedmiotu obserwacji konieczne jest określenie jednostki obserwacji oraz jednostki populacji. Jednostka obserwacji jest elementem składowym przedmiotu obserwacji, który jest źródłem informacji. W zależności od konkretnych zadań obserwacji statystycznej jednostkami obserwacji może być gospodarstwo domowe lub osoba, np. student, przedsiębiorstwo rolne lub fabryka. Jednostka populacji - jest to tzw. element składowy przedmiotu obserwacji, z którego uzyskuje się informację o jednostce obserwacji, czyli stanowi podstawę liczenia i posiada cechy podlegające rejestracji w procesie obserwacji. Np. w spisie plantacji leśnych jednostką populacji będzie drzewo, gdyż posiada cechy podlegające rejestracji (wiek, skład gatunkowy itp.), natomiast samo leśnictwo, w którym prowadzone jest badanie , działa jako jednostka obserwacji. Jednostki obserwacyjne nazywane są jednostkami sprawozdawczymi, jeśli przekazują sprawozdania statystyczne organom statystycznym. Każde zjawisko czy proces życia społecznego ma wiele cech, które je charakteryzują. Nie jest możliwe uzyskanie informacji o wszystkich cechach i nie wszystkie z nich interesują badacza. Przygotowując obserwację należy zdecydować, które znaki będą podlegały rejestracji zgodnie z celami i założeniami obserwacji. Aby określić skład zarejestrowanych cech, opracowywany jest program obserwacyjny. Program obserwacji statystycznej to zestaw pytań, na które odpowiedzi w procesie obserwacji powinny stanowić informację statystyczną. Opracowanie programu obserwacji jest bardzo ważnym i odpowiedzialnym zadaniem, a powodzenie obserwacji zależy od tego, jak poprawnie zostanie przeprowadzona. Opracowując program obserwacji, należy wziąć pod uwagę szereg wymagań. Wymieniamy główne. 1. Program powinien w miarę możliwości zawierać tylko te cechy, które są niezbędne i których wartości będą wykorzystywane do dalszej analizy lub do celów kontrolnych. Dążąc do kompletności informacji, która zapewnia otrzymanie łagodnych materiałów, nadal konieczne jest ograniczanie ilości gromadzonych informacji w celu uzyskania, aczkolwiek niewielkiego, ale wiarygodnego materiału do analizy. 2. Pytania programu powinny być sformułowane dość jasno, niezwykle jasno, aby wykluczyć ich błędną interpretację i zapobiec zniekształceniu znaczenia gromadzonych informacji. 3. Opracowując program obserwacji, pożądane jest zbudowanie logicznej sekwencji pytań. Pytania tego samego typu lub znaki, które charakteryzują dowolną stronę zjawiska, należy połączyć w jedną sekcję. 4. Ważne jest, aby program monitorowania zawierał pytania kontrolne do sprawdzania i korygowania zarejestrowanych informacji. Do przeprowadzenia obserwacji potrzebne są własne narzędzia – formularze i instrukcje. formularz statystyczny - Jest to specjalny dokument pojedynczej próbki, w którym zapisywane są odpowiedzi na pytania programu. W zależności od konkretnej treści prowadzonej obserwacji formularz można nazwać formą sprawozdawczości statystycznej, spisem lub kwestionariuszem, mapą, kartą, kwestionariuszem lub formularzem. Istnieją dwa rodzaje formularzy – karta i lista. Formularz karty (lub formularz indywidualny) ma odzwierciedlać informacje o jednej jednostce populacji statystycznej, a formularz listy zawiera informacje o kilku jednostkach populacji. Integralnymi i obowiązkowymi elementami formularza statystycznego są tytuł, adres i treść. W części tytułowej wskazano nazwę obserwacji statystycznej i organ, który zatwierdził ten formularz, warunki składania formularza i inne informacje. Część adresowa zawiera dane jednostki sprawozdawczej obserwacji. Główna, merytoryczna część formularza jest zwykle sporządzona w formie tabeli, która w wygodnej formie zawiera nazwy, kody i wartości wskaźników. Formularz statystyczny wypełniany jest zgodnie z instrukcją. Instrukcja zawiera instrukcje dotyczące trybu prowadzenia obserwacji oraz instrukcje metodyczne i wyjaśnienia dotyczące wypełniania formularza. W zależności od złożoności programu nadzoru, instrukcja jest publikowana w formie broszury lub umieszczana na odwrocie formularza. Ponadto w celu uzyskania niezbędnych wyjaśnień możesz skontaktować się ze specjalistami odpowiedzialnymi za prowadzenie obserwacji, organami ją prowadzącymi. Organizując obserwację statystyczną konieczne jest rozstrzygnięcie kwestii czasu obserwacji i miejsca jej prowadzenia. Wybór miejsca obserwacji zależy od celu obserwacji. Wybór czasu obserwacji wiąże się z wyznaczeniem momentu krytycznego (daty) lub przedziału czasowego oraz określeniem okresu (okresu) obserwacji. Momentem krytycznym obserwacji statystycznej jest moment, do którego trafiają informacje zarejestrowane w procesie obserwacji. Okres obserwacji określa okres, w którym należy dokonać rejestracji informacji o badanym zjawisku, czyli przedział czasu, w którym formularze są wypełniane. Zazwyczaj okres obserwacji nie powinien być zbyt odległy od krytycznego momentu obserwacji, aby odtworzyć stan obiektu w tym momencie. 4. Zagadnienia wsparcia organizacyjnego, przygotowania i prowadzenia obserwacji statystycznych Aby pomyślnie przygotować i przeprowadzić obserwację statystyczną, należy również rozwiązać kwestie jej wsparcia organizacyjnego. Odbywa się to podczas sporządzania planu monitorowania organizacji. Plan odzwierciedla cele i zadania obserwacji, przedmiot obserwacji, miejsce, czas, czas obserwacji, krąg osób odpowiedzialnych za prowadzenie obserwacji. Obowiązkowym elementem planu organizacyjnego jest wskazanie organu monitorującego. Określony jest również krąg organizacji powołanych do pomocy w monitoringu. Mogą to być organy spraw wewnętrznych, inspektoraty podatkowe, ministerstwa liniowe, organizacje publiczne, osoby fizyczne, wolontariusze itp. Działania przygotowawcze obejmują: 1) opracowywanie form obserwacji statystycznych, powielanie dokumentacji samego badania; 2) opracowanie aparatu metodycznego do analizy i prezentacji wyników obserwacji; 3) rozwój oprogramowania do przetwarzania danych, zakup sprzętu komputerowego i biurowego; 4) zakup niezbędnych materiałów, w tym artykułów papierniczych; 5) szkolenie wykwalifikowanego personelu, szkolenie personelu, prowadzenie różnego rodzaju odpraw itp.; 6) prowadzenie masowych prac wyjaśniających wśród ludności i uczestników obserwacji (wykłady, rozmowy, wystąpienia w prasie, radiu i telewizji); 7) koordynacja działań wszystkich służb i organizacji zaangażowanych we wspólne działania; 8) wyposażenie miejsca gromadzenia i przetwarzania danych; 9) przygotowanie kanałów przekazu informacji i środków komunikacji; 10) rozstrzyganie spraw związanych z finansowaniem obserwacji statystycznych. Tak więc plan obserwacji zawiera szereg środków, a także charakteryzujące je okoliczności miejsca i czasu, mające na celu pomyślne zakończenie prac nad rejestracją niezbędnych informacji. 5. Dokładność obserwacji i metody walidacji danych Każdy konkretny pomiar wielkości danych, dokonywany w procesie obserwacji, daje z reguły przybliżoną wartość wielkości zjawiska, która różni się w pewnym stopniu od rzeczywistej wartości tej wielkości. Dokładność obserwacji statystycznych nazywany stopniem zgodności dowolnego wskaźnika lub cechy, obliczony na podstawie materiałów obserwacyjnych, z jego rzeczywistą wartością. Rozbieżność między wynikiem obserwacji a rzeczywistą wartością wielkości obserwowanego zjawiska nazywa się błąd obserwacji. W zależności od charakteru, stadium i przyczyn występowania rozróżnia się kilka rodzajów błędów obserwacji. Ze swej natury błędy dzielą się na losowe i systematyczne. Losowe błędy - Są to błędy, których wystąpienie wynika z działania czynników losowych. Należą do nich zastrzeżenia i błędy drukarskie ze strony rozmówcy. Mogą być skierowane na zmniejszenie lub zwiększenie wartości atrybutu. Z reguły nie mają one odzwierciedlenia w ostatecznym wyniku, ponieważ znoszą się wzajemnie podczas sumarycznego przetwarzania wyników obserwacji. Błędy systematyczne mają taką samą tendencję do zmniejszania lub zwiększania wartości charakterystycznego wskaźnika. Wynika to z faktu, że pomiary są dokonywane na przykład wadliwym urządzeniem pomiarowym lub błędy są wynikiem niejasnego sformułowania kwestii programu obserwacyjnego itp. Błędy systematyczne są bardzo niebezpieczne, ponieważ znacznie zniekształcają wyniki obserwacji. W zależności od etapu wystąpienia występują: błędy rejestracji; błędy, które pojawiają się podczas przygotowywania danych do przetwarzania maszynowego; błędy pojawiające się w procesie przetwarzania w technologii komputerowej. К błędy rejestracji obejmują te nieścisłości, które występują podczas rejestrowania danych w formie statystycznej (dokument pierwotny, formularz, raport, formularz spisu powszechnego) lub podczas wprowadzania danych do komputerów, zniekształcenie danych podczas przesyłania za pośrednictwem linii komunikacyjnych (telefon, e-mail). Często błędy rejestracyjne występują z powodu niezgodności z formą formularza, tj. wpis nie jest dokonywany w ustalonym wierszu lub kolumnie dokumentu. Dochodzi też do celowego zniekształcenia wartości poszczególnych wskaźników. Błędy w przygotowaniu danych do obróbki maszynowej lub w samym procesie przetwarzania występują w centrach komputerowych lub centrach przygotowania danych. Występowanie takich błędów wiąże się z niedbałym, nieprawidłowym, rozmytym wypełnianiem danych w formularzach, z fizyczną wadą nośnika danych, z utratą części danych z powodu niezgodności z technologią przechowywania baz informacji. Czasami błędy są spowodowane awarią sprzętu. Znając rodzaje i przyczyny błędów obserwacji, można znacznie zmniejszyć odsetek takich zniekształceń informacji. Istnieje kilka rodzajów błędów: 1) błędy pomiarowe związane z pewnymi błędami, które powstają podczas jednorazowej statystycznej obserwacji zjawiska i procesów życia społecznego; 2) błędy reprezentatywności powstałe w toku obserwacji nieciągłej i związane z tym, że sama próba nie jest reprezentatywna, a wyników uzyskanych na jej podstawie nie można rozszerzyć na całą populację; 3) celowych błędów wynikających z celowego zniekształcenia danych w różnych celach, w tym chęci upiększenia rzeczywistego stanu przedmiotu obserwacji lub odwrotnie, pokazania niezadowalającego stanu przedmiotu itp. Należy zauważyć, że takie zniekształcenie informacji jest naruszeniem prawa; 4) błędy niezamierzone, co do zasady o charakterze przypadkowym i związane z niskimi kwalifikacjami pracowników, ich nieuwagą lub niedbalstwem. Często takie błędy są związane z czynnikami subiektywnymi, gdy ludzie podają nieprawdziwe informacje o swoim wieku, stanie cywilnym, wykształceniu, przynależności do grupy społecznej itp. lub po prostu zapominają o niektórych faktach, przekazując rejestratorowi informacje, które właśnie przyszły do pamięci. Pożądane jest przeprowadzenie pewnych działań, które pomogą zapobiegać, identyfikować i korygować błędy obserwacyjne. Działania te obejmują: 1) dobór wykwalifikowanego personelu oraz wysokiej jakości przeszkolenie personelu związane z prowadzeniem dozoru; 2) organizacja kontroli kontrolnych prawidłowości wypełniania dokumentów metodą ciągłą lub wybiórczą; 3) arytmetyczna i logiczna kontrola otrzymanych danych po zakończeniu zbierania materiałów obserwacyjnych. Główne typy kontroli wiarygodności danych to syntaktyczna, logiczna i arytmetyczna. 1. Kontrola składniowa oznacza sprawdzenie poprawności struktury dokumentu, obecności niezbędnych i obowiązkowych szczegółów, kompletności wypełnienia wierszy formularza zgodnie z ustalonymi zasadami. Znaczenie i konieczność kontroli składniowej tłumaczy się wykorzystaniem technologii komputerowej, skanerów do przetwarzania danych, które nakładają surowe wymagania na przestrzeganie zasad wypełniania formularzy. 2. Kontrola logiczna sprawdza poprawność zapisu kodów, zgodność z ich nazwami i wartościami wskaźników. Sprawdzane są niezbędne relacje między wskaźnikami, porównywane są odpowiedzi na różne pytania i identyfikowane są niekompatybilne kombinacje. Aby poprawić błędy wykryte podczas kontroli logicznej, powracają do oryginalnych dokumentów i dokonują poprawek. 3. Podczas kontroli arytmetycznej uzyskane sumy są porównywane z wcześniej obliczonymi sumami kontrolnymi dla wierszy i kolumn. Dość często kontrola arytmetyczna opiera się na zależności jednego wskaźnika od dwóch lub więcej innych (na przykład jest iloczynem innych wskaźników). Jeżeli kontrola arytmetyczna wskaźników końcowych wykaże, że ta zależność nie jest obserwowana, będzie to wskazywać na niedokładność danych. Tym samym kontrola wiarygodności informacji statystycznych prowadzona jest na wszystkich etapach obserwacji statystycznej – od zebrania informacji pierwotnych do etapu uzyskiwania wyników. WYKŁAD nr 3. Zestawienie statystyczne i grupowanie 1. Podsumowanie zadań i treści Zorganizowane naukowo przetwarzanie statystycznych materiałów obserwacyjnych według opracowanego wcześniej programu obejmuje, oprócz kontroli danych, systematyzację, grupowanie danych, zestawianie, uzyskiwanie wyników i wskaźników pochodnych (wartości średnie i względne) itp. Materiał zebrany w procesie obserwacja statystyczna to rozproszone pierwotne informacje o poszczególnych jednostkach badanego zjawiska. W tej formie materiał nie charakteryzuje jeszcze zjawiska jako całości: nie daje wyobrażenia ani o wielkości (liczbie) zjawiska, ani o jego składzie, ani o wielkości cech charakterystycznych, ani o powiązania tego zjawiska z innymi zjawiskami itp. Istnieje potrzeba specjalnego opracowania danych statystycznych - zestawień materiałów obserwacyjnych. Podsumowanie to zestaw sekwencyjnych działań mających na celu uogólnienie określonych pojedynczych danych, które tworzą zestaw w celu wykrycia typowych cech i wzorców nieodłącznie związanych z badanym zjawiskiem jako całością. Podsumowanie statystyczne w wąskim znaczeniu tego słowa (proste podsumowanie) jest operacją obliczania łącznych danych podsumowujących (podsumowań) dla zbioru jednostek obserwacji. Podsumowanie statystyczne w szerokim tego słowa znaczeniu (kompleksowe podsumowanie) obejmuje również grupowanie danych obserwacyjnych, obliczanie sum ogólnych i grupowych, uzyskiwanie systemu powiązanych ze sobą wskaźników, prezentowanie wyników grupowania i podsumowań w postaci tabel statystycznych. Prawidłowe, uporządkowane naukowo podsumowanie, oparte na wstępnej głębokiej analizie teoretycznej, pozwala uzyskać wszystkie wyniki statystyczne, które odzwierciedlają najważniejsze, charakterystyczne cechy przedmiotu badań, zmierzyć wpływ różnych czynników na wynik i wziąć to wszystko uwzględniać w pracy praktycznej, przy sporządzaniu planów bieżących i długoterminowych. W konsekwencji zadaniem podsumowania jest scharakteryzowanie przedmiotu badań za pomocą systemów wskaźników statystycznych, zidentyfikowanie i zmierzenie w ten sposób jego istotnych cech i cech. To zadanie rozwiązuje się w trzech etapach: 1) definicja grup i podgrup; 2) określenie systemu wskaźników; 3) określenie rodzajów tabel. W pierwszym etapie przeprowadzana jest systematyzacja, grupowanie materiałów zebranych podczas obserwacji. W drugim etapie określa się system wskaźników przewidzianych w planie, za pomocą którego określa się ilościowo właściwości i cechy badanego przedmiotu. Na trzecim etapie obliczane są same wskaźniki, a uogólnione dane są prezentowane w tabelach, seriach statystycznych, wykresach i diagramach dla przejrzystości i wygody. Wymienione etapy podsumowania, jeszcze przed rozpoczęciem jego realizacji, znajdują odzwierciedlenie w specjalnie skompilowanym programie. Program zestawień statystycznych zawiera listę grup, na które wskazane jest podzielenie populacji, ich granice zgodnie z charakterystyką grupowania; system wskaźników charakteryzujących całość oraz sposób ich obliczania; system układów tablic rozwojowych, w których prezentowane będą wyniki obliczeń. Wraz z programem jest plan zbiorczy, który przewiduje jego organizację. Plan przeprowadzenia podsumowania powinien zawierać instrukcje dotyczące kolejności i harmonogramu wdrażania poszczególnych jego części, osób odpowiedzialnych za jego wdrożenie, procedury przedstawiania wyników, a także przewidywać koordynację prac wszystkich zaangażowanych organizacji w jego realizacji. 2. Główne zadania i rodzaje grup Przedmiot badań statystycznych – zjawiska masowe i procesy życia społecznego – ma wiele cech i właściwości. Uogólnienie danych statystycznych, ujawnienie najistotniejszych cech, form rozwoju zjawiska masowego jako całości i jego poszczególnych składowych jest niemożliwe bez pewnych naukowych zasad przetwarzania danych. Nie przezwyciężając indywidualnej różnorodności obiektów obserwacji statystycznej, ogólne wzorce rozwoju zjawiska lub procesu jako całości gubią się w szczegółach i drobiazgach, które odróżniają każdy obiekt od siebie, a ostateczne uogólnienie pociąga za sobą zniekształconą ideę rzeczywistość. Aby podzielić zbiór jednostek na grupy tego samego typu, statystyka wykorzystuje metodę grupowania. Grupy statystyczne - pierwszy etap zestawienia statystycznego, który umożliwia wyodrębnienie z masy wyjściowego materiału statystycznego jednorodnych grup jednostek, wykazujących ogólne podobieństwo jakościowe i ilościowe. Ważne jest, aby zrozumieć, że grupowanie nie jest subiektywną techniką dzielenia populacji na części, ale naukowo opartym procesem dzielenia zestawu jednostek populacji według określonego atrybutu. Podstawową zasadą stosowania metody grupowania jest wszechstronna, dogłębna analiza istoty i natury badanego zjawiska, pozwalająca określić jego typowe właściwości i różnice wewnętrzne. Każdy zbiór ogólny jest zespołem zbiorów szczegółowych, z których każdy łączy zjawiska szczególnego typu, o tej samej jakości pod pewnym względem. Każdy typ (grupa) ma określony system cech z odpowiednim poziomem ich wartości ilościowych. Aby określić, do jakiego typu, do jakiej populacji należy przypisać zgrupowane jednostki całej populacji, możliwie na podstawie poprawnej, jasnej definicji zasadniczych cech, według których należy przeprowadzić grupowanie. Jest to drugi ważny wymóg grupowania opartego na naukach. Trzeci wymóg grupowania opiera się na obiektywnym, rozsądnym ustaleniu granic grup, pod warunkiem, że tworzące się grupy muszą łączyć jednorodne elementy populacji, a same grupy (jedna w stosunku do drugiej) muszą się znacznie różnić. W przeciwnym razie grupowanie jest bez znaczenia. W ten sposób, na podstawie zastosowania metody grupowania, grupy wyznacza się zgodnie z zasadą podobieństwa i różnicy jednostek populacji. Podobieństwo to jednorodność jednostek w pewnych granicach (grupy); różnica polega na ich znacznej rozbieżności w grupach. W ten sposób grupowanie - rozczłonkowanie całej populacji jednostek według jednej lub kilku cech zasadniczych na grupy jednorodne, różniące się jakościowo i ilościowo, umożliwiające wyodrębnienie typów społeczno-ekonomicznych, badanie struktury populacji lub analizę związków między poszczególnymi cechami. Różnorodność zjawisk społecznych i celów ich badań pozwala na wykorzystanie dużej liczby statystycznych grup zjawisk i na tej podstawie rozwiązywanie szerokiej gamy specyficznych problemów. Główne zadania rozwiązywane za pomocą grupowań w statystykach to: 1) alokację w całości badanych zjawisk ich typów społeczno-ekonomicznych; 2) badanie struktury zjawisk społecznych; 3) identyfikacja powiązań i zależności między zjawiskami społecznymi. Wszystkie ugrupowania związane z alokacją w całości badanych zjawisk ich typów społeczno-ekonomicznych zajmują centralne miejsce w statystyce. Zadanie to dotyczy najważniejszych, decydujących aspektów życia publicznego, np. grupowania ludności według statusu społecznego, płci, wieku, poziomu wykształcenia, grupowania przedsiębiorstw i organizacji według własności, przynależności branżowej. Budowa takich ugrupowań w długich okresach pozwala prześledzić proces rozwoju stosunków społeczno-gospodarczych. Zadanie podziału ogółu zjawisk społecznych według ich typów społeczno-ekonomicznych rozwiązuje konstruowanie grupowań typologicznych. Tak więc, grupowanie typologiczne - jest to podział jakościowo niejednorodnej populacji badanej na jednorodne grupy jednostek zgodnie z typami społeczno-ekonomicznymi. Wyjątkowo duże znaczenie przywiązuje się do badania struktury zjawisk społecznych, czyli do badania różnic w składzie poszczególnych typów zjawisk (korelacja między częściami składowymi zjawiska, zmiany tych korelacji w pewnym okresie czas). W ten sposób, grupowanie strukturalne nazywana zgrupowaniem, w którym jednorodna populacja jest podzielona na grupy, które charakteryzują jej strukturę według jakiejś różnej cechy. Do grupowania strukturalnego zalicza się grupowanie ludności według płci, wieku, poziomu wykształcenia, grupowanie przedsiębiorstw według liczby zatrudnionych, poziomu płac, wielkości pracy itp. Zmiany w strukturze zjawisk społecznych odzwierciedlają najważniejsze wzorce ich rozwoju. Na przykład w latach 1959-1994 Populacja miejska stale rośnie, podczas gdy ludność wiejska spada, ale w latach 1994-2002 stosunek tych grup ludności nie uległ zmianie. Zastosowanie grupowań strukturalnych pozwala nie tylko ujawnić strukturę populacji, ale także przeanalizować badane procesy, ich intensywność, zmiany w przestrzeni, a grupowania strukturalne przejmowane w kilku przedziałach czasowych ujawniają wzorce zmian w składzie populacji. populacja w czasie. Grupowanie strukturalne może opierać się na jednej lub kilku cechach atrybutowych lub ilościowych. O ich wyborze decydują cele danego badania oraz charakter badanej populacji. Powyższe grupowanie jest zbudowane na podstawie atrybutów. W przypadku grupowania strukturalnego według atrybutu ilościowego konieczne staje się określenie liczby grup i ich granic. Kwestia ta została rozwiązana zgodnie z celami badania. Jeden i ten sam materiał statystyczny można podzielić na grupy w różny sposób, w zależności od celów i zadań badania. Najważniejsze jest dążenie do tego, aby w procesie grupowania cechy badanego zjawiska były wyraźnie odzwierciedlone i stworzono przesłanki do konkretnych wniosków i rekomendacji. Należy zauważyć, że technicznie wygodniejsze jest zajmowanie się równymi przedziałami, ale nie zawsze jest to możliwe ze względu na właściwości badanych zjawisk i cech. W gospodarce coraz częściej konieczne jest stosowanie nierównych, stopniowo rosnących przedziałów, co wynika z samej natury zjawisk ekonomicznych. Stosowanie nierównych przedziałów tłumaczy się głównie tym, że bezwzględna zmiana cechy grupowania o tę samą wartość jest daleka od tej samej wartości dla grup o dużej i małej wartości cechy. Na przykład między dwoma przedsiębiorstwami zatrudniającymi do 300 pracowników różnica 100 pracowników jest bardziej znacząca niż w przypadku przedsiębiorstw zatrudniających ponad 10 000 pracowników. Przedziały grupowe można zamknąć, gdy określono dolną i górną granicę, i otworzyć, gdy określono tylko jedną z granic grupy. Interwały otwarte dotyczą tylko grup ekstremalnych. W przypadku grupowania w nierównych odstępach pożądane jest tworzenie grup o zamkniętych odstępach. Przyczynia się to do dokładności obliczeń statystycznych. Jednym z celów obserwacji statystycznych jest identyfikacja powiązań i zależności między zjawiskami społecznymi. Ważnym zadaniem analizy statystycznej prowadzonej na podstawie grupowania typologicznego, tj. w ramach agregatów jednojakościowych, jest badanie i pomiar relacji między poszczególnymi cechami. Grupowanie analityczne umożliwia ustalenie istnienia takiego połączenia. Grupowanie analityczne - powszechna metoda statystycznego badania relacji, które można znaleźć przez równoległe porównanie uogólnionych wartości cech według grup. Istnieją znaki zależne, których wartości zmieniają się pod wpływem innych znaków (zwykle nazywane są one skutecznymi w statystyce) oraz znaki czynnikowe, które wpływają na inne. Zwykle podstawą grupowania analitycznego jest czynnik znakowy, a zgodnie z efektywnymi znakami obliczane są średnie grupowe, których zmiana wartości decyduje o obecności związku między znakami. Tak więc takie grupowania można nazwać analitycznymi, które pozwalają ustalić i zbadać związek między cechami produkcyjnymi i czynnikowymi jednostek tego samego typu populacji. Ważnym problemem grupowań analitycznych jest prawidłowy dobór liczby grup i określenie ich granic, co w dalszej kolejności zapewnia obiektywność cech połączenia. Ponieważ analiza prowadzona jest w zestawach o tej samej jakości, nie ma teoretycznych podstaw do podziału pewnego typu. W związku z tym dopuszczalny jest podział populacji na dowolną liczbę grup spełniających określone wymagania i warunki danej analizy. W procesie grupowania analitycznego należy przestrzegać ogólnych zasad grupowania, tj. jednostki w tworzonych grupach powinny być znacząco różne, liczba jednostek w grupach powinna być wystarczająca do obliczenia wiarygodnych charakterystyk statystycznych. Ponadto średnie grupowe muszą mieć pewien wzór: konsekwentnie rosnąć lub maleć. Bezpośrednie grupowanie danych z obserwacji statystycznych jest grupowaniem podstawowym. Grupowanie wtórne to przegrupowanie wcześniej pogrupowanych danych. Potrzeba wtórnego grupowania pojawia się w dwóch przypadkach: 1) jeżeli wcześniej utworzone zgrupowanie nie spełnia celów badania w stosunku do liczby grup; 2) porównanie danych dotyczących różnych okresów lub różnych terytoriów, jeżeli grupowanie pierwotne zostało przeprowadzone według różnych cech grupowania lub w różnych odstępach czasu. Istnieją dwa sposoby grupowania wtórnego: 1) łączenie małych grup w większe; 2) przydział określonej proporcji jednostek ludności. W naukowo uzasadnionym grupowaniu zjawisk społecznych konieczne jest uwzględnienie współzależności zjawisk i możliwości przejścia stopniowych zmian ilościowych zjawisk do fundamentalnych zmian jakościowych. Grupowanie może mieć charakter naukowy tylko wtedy, gdy zostaną zdefiniowane nie tylko poznawcze cele grupowania, ale także odpowiednio dobrana podstawa grupowania - atrybut grupowania. Jeśli grupowanie jest rozkładem na jednorodne grupy według jakiegoś atrybutu, połączeniem poszczególnych jednostek populacji w grupy, które są jednorodne według jakiegoś atrybutu, to atrybut grupowania jest znakiem, za pomocą którego poszczególne jednostki populacji są łączone w oddzielne grupy. Przy wyborze atrybutu grupującego ważny jest nie sposób wyrażenia atrybutu, ale jego znaczenie dla badanego zjawiska. Z tego punktu widzenia do grupowania należy przyjąć podstawowe cechy, które wyrażają najbardziej charakterystyczne cechy badanego zjawiska. Najprostszym grupowaniem jest szereg dystrybucyjny. Rzędy dystrybucji ciągi liczb (cyfr) nazywane są, charakteryzującymi skład lub strukturę zjawiska po zgrupowaniu danych statystycznych o tym zjawisku. Szereg rozkładu to zgrupowanie, w którym do scharakteryzowania grup stosuje się jeden wskaźnik – wielkość grupy, czyli jest to szereg liczb pokazujący, w jaki sposób jednostki populacji rozkładają się według badanej cechy. Wiersze zbudowane na podstawie atrybutów nazywane są linie atrybutów. Powyższy szereg rozkładów zawiera trzy elementy: odmiany atrybutu (mężczyźni, kobiety); liczba jednostek w każdej grupie, zwana częstościami szeregu rozdzielczego; liczba grup, wyrażona jako udziały (procenty) łącznej liczby jednostek, zwana częstotliwości. Suma częstości wynosi 1, jeśli są wyrażone jako ułamek jeden, i 100%, jeśli są wyrażone w procentach. Szeregi dystrybucji zbudowane na podstawie ilościowej nazywane są szeregami zmienności. Wartości liczbowe atrybutu ilościowego w serii rozkładu wariacyjnego nazywane są wariantami i są ułożone w określonej kolejności. Warianty można wyrażać liczbami dodatnimi i ujemnymi, bezwzględnymi i względnymi. Szeregi wariacyjne dzielą się na dyskretne i interwałowe. Dyskretne szeregi wariacyjne charakteryzują rozkład jednostek populacji zgodnie z atrybutem dyskretnym (nieciągłym), tj. takim, który przyjmuje wartości całkowite. Przy konstruowaniu szeregu rozkładów z dyskretną zmiennością cechy wszystkie opcje są wypisywane w porządku rosnącym ich wartości, oblicza się, ile razy powtarza się ta sama wartość opcji, tj. częstość, i jest zapisywana w jednym wierszu z odpowiednią wartość opcji (na przykład podział rodzin według liczby dzieci). Częstotliwości w dyskretnych szeregach wariacji, jak również w szeregach atrybutów, można zastąpić częstotliwościami. W przypadku ciągłej zmienności wartość atrybutu może przybierać dowolne wartości w pewnym przedziale, na przykład rozkład pracowników firmy według poziomu dochodów. Przy konstruowaniu serii zmienności interwałowej konieczne jest wybranie optymalnej liczby grup (interwałów znakowych) oraz ustalenie długości interwału. Optymalną liczbę grup dobiera się tak, aby odzwierciedlić zróżnicowanie wartości cech w populacji. Najczęściej liczbę grup określa wzór: k = 1 + 3,32 lg N = 1,441 lg N + 1 gdzie k jest liczbą grup; N - wielkość populacji. Załóżmy na przykład, że konieczne jest zbudowanie serii wariacyjnej przedsiębiorstw rolnych według plonów zbóż. Liczba przedsiębiorstw rolnych 143. Jak określić liczbę grup? k = 1 + 3,321lg N = 1 + 3,321lg143 = 8,16 Liczba grup może być tylko liczbą całkowitą, w tym przypadku 8 lub 9. Jeśli wynikowe grupowanie nie spełnia wymagań analizy, możesz przegrupować. Nie należy dążyć do bardzo dużej liczby grup, gdyż w takim zgrupowaniu często zanikają różnice między grupami. Należy również unikać tworzenia się zbyt małych grup, w tym kilku jednostek populacji, ponieważ w takich grupach przestaje działać prawo dużych liczb i możliwa jest losowość. Gdy nie jest możliwe natychmiastowe zidentyfikowanie ewentualnych grup, zebrany materiał najpierw dzieli się na znaczną liczbę grup, a następnie powiększa się, zmniejszając liczbę grup i tworząc grupy jakościowo jednorodne. Dlatego we wszystkich przypadkach ugrupowania powinny być konstruowane w taki sposób, aby utworzone w nich grupy jak najpełniej odpowiadały rzeczywistości, różnice między grupami byłyby widoczne, a zjawiska znacznie różniące się od siebie nie byłyby łączone w jedno. Grupa. 3. Tabele statystyczne Po zebraniu, a nawet pogrupowaniu danych z obserwacji statystycznych, trudno je dostrzec i przeanalizować bez pewnej wizualnej systematyzacji. Wyniki zestawień statystycznych i grupowań prezentowane są w postaci tabel statystycznych. Tabela statystyczna - tabela, która daje ilościowy opis populacji statystycznej i jest formą wizualnej prezentacji otrzymanego podsumowania statystycznego i grupowania danych liczbowych (liczbowych). Z wyglądu jest to połączenie linii pionowych i poziomych. Musi mieć wspólne nagłówki boczne i górne. Kolejną cechą tabeli statystycznej jest obecność w niej podmiotu (charakterystyka zbiorowości statystycznej) oraz predykatu (wskaźnik charakteryzujący zbiorowość). Tabele statystyczne są formą najbardziej racjonalnej prezentacji wyników podsumowania lub grupowania. Temat tabeli reprezentuje populację statystyczną, o której mowa w tabeli, tj. wykaz poszczególnych lub wszystkich jednostek populacji lub ich grup. Najczęściej temat umieszczany jest po lewej stronie tabeli i zawiera listę ciągów. Predykat tabeli - są to wskaźniki charakteryzujące zjawisko przedstawione w tabeli. Temat i orzeczenie tabeli można ułożyć w różny sposób. Jest to kwestia techniczna, najważniejsze jest to, że tabela jest czytelna, zwarta i łatwa do zrozumienia. W praktyce statystycznej i pracach badawczych stosuje się tablice o różnym stopniu złożoności. Zależy to od charakteru badanej populacji, ilości dostępnych informacji oraz zadań analizy. Jeżeli temat tabeli zawiera prostą listę dowolnych obiektów lub jednostek terytorialnych, tabela nazywana jest prostą. Temat prostej tabeli nie zawiera żadnych grupowań danych statystycznych. Proste tabele mają najszersze zastosowanie w praktyce statystycznej. Charakterystykę miast Federacji Rosyjskiej pod względem liczby ludności, średniej pensji itp. przedstawia prosta tabela. Jeśli temat prostej tabeli zawiera listę terytoriów (na przykład regiony, terytoria, regiony autonomiczne, republiki itp.), wówczas taka tabela nazywa się terytorialną. Prosta tabela zawiera tylko informacje opisowe, jej możliwości analityczne są ograniczone. Głęboka analiza badanej populacji, związek znaków polega na konstruowaniu bardziej złożonych tablic - grupowych i kombinacyjnych. Tabele grupowe, w przeciwieństwie do prostych, zawierają w temacie nie prostą listę jednostek przedmiotu obserwacji, ale ich pogrupowanie według jednego istotnego atrybutu. Najprostszym typem tabeli grupowej są tabele, w których prezentowane są szeregi rozkładów. Tabela grup może być bardziej złożona, jeśli orzeczenie zawiera nie tylko liczbę jednostek w każdej grupie, ale także szereg innych ważnych wskaźników, które ilościowo i jakościowo charakteryzują grupy tematyczne. Takie tabele są często używane do porównywania wskaźników sumarycznych w różnych grupach, co pozwala na wyciągnięcie pewnych praktycznych wniosków. Tabele kombinowane mają szersze możliwości analityczne. Tabele kombinowane nazywane są tabelami statystycznymi, w których grupy jednostek utworzone według jednego atrybutu są podzielone na podgrupy według jednego lub więcej atrybutów. W przeciwieństwie do tabel prostych i grupowych, tabele kombinacyjne pozwalają prześledzić zależność wskaźników predykatów od kilku cech, które stanowiły podstawę kombinacyjnego grupowania w temacie. Oprócz tabel wymienionych powyżej w praktyce statystycznej stosuje się tabele kontyngencji (lub tabele częstości). Podstawą konstrukcji takich tabel jest grupowanie jednostek populacji według dwóch lub więcej cech, które nazywane są poziomami. Na przykład populację dzieli się według płci (mężczyzna, kobieta) itp. Zatem cecha A ma n stopni (lub poziomów) A1 A2,n (w przykładzie n = 2). Następnie badamy interakcję cechy A z inną cechą - B, która jest podzielona na k stopni (czynników) B1, B2, Bк. W naszym przykładzie atrybut B należy do zawodu, a atrybut B1, B2,.,Bk przyjmuj określone wartości (lekarz, kierowca, nauczyciel, budowniczy itp.). Grupowanie według dwóch lub więcej cech służy do oceny związku między cechami A i B. W postaci „złożonej” wyniki obserwacji mogą być reprezentowane przez tabelę kontyngencji składającą się z n wierszy i k kolumn, w komórkach których wskazane są częstości zdarzeń nij, czyli liczba obiektów próbki, które mają kombinację poziomów Ai i Bj. Jeżeli między zmiennymi A i B istnieje bezpośrednia lub zwrotna zależność funkcjonalna jeden do jednego, to wszystkie częstotliwości nij są skoncentrowane wzdłuż jednej z przekątnych tabeli. Gdy połączenie nie jest tak silne, pewna liczba obserwacji również przypada na elementy poza przekątną. W tych warunkach badacz staje przed zadaniem ustalenia, na ile dokładnie można przewidzieć wartość jednej cechy od wartości innej. Mówi się, że tablica częstości jest jednowymiarowa, jeśli zestawiono w niej tylko jedną zmienną. Tabela oparta na grupowaniu według dwóch cech (poziomów), które są zestawione według dwóch cech (czynników) jest nazywana tabelą z dwoma danymi wejściowymi. Tabele liczności, w których zestawione są wartości dwóch lub więcej cech, nazywane są tablicami kontyngencji. Spośród wszystkich typów tabel statystycznych najszerzej stosowane są tabele proste, rzadziej tabele statystyczne grupowe, a zwłaszcza łączone, a tabele kontyngencji są budowane dla specjalnych rodzajów analiz. Tabele statystyczne służą jako jeden z ważnych sposobów wyrażania i badania masowych zjawisk społecznych, ale tylko wtedy, gdy są poprawnie skonstruowane. Forma każdej tabeli statystycznej powinna najlepiej odpowiadać istocie wyrażanego przez nią zjawiska i celom jej badania. Osiąga się to poprzez odpowiednie rozwinięcie tematu i predykatu tabeli. Zewnętrznie tabela powinna być mała i zwarta, posiadać tytuł, wskazanie jednostek miary, a także czas i miejsce, do którego odnosi się informacja. Nagłówki wierszy i kolumn w tabeli podane są zwięźle, ale precyzyjnie i przejrzyście. Nadmierny bałagan na stole z danymi cyfrowymi, niechlujna konstrukcja utrudnia jej odczytywanie i analizowanie. Wymieniamy podstawowe zasady konstruowania tabel statystycznych. 1. Tabela statystyczna powinna być zwarta i odzwierciedlać tylko te dane wyjściowe, które bezpośrednio odzwierciedlają badane zjawisko społeczno-gospodarcze w statyce i dynamice. 2. Tytuł tabeli statystycznej oraz tytuł kolumn i wierszy powinien być jasny, zwięzły, zwięzły. Tytuł powinien odzwierciedlać przedmiot, znak, czas i miejsce wydarzenia. 3. Kolumny i wiersze należy ponumerować. 4. Kolumny i wiersze muszą zawierać jednostki miary, dla których istnieją ogólnie przyjęte skróty. 5. Porównywane podczas analizy informacje najlepiej umieścić w sąsiednich kolumnach (lub jedna pod drugą). Ułatwia to proces porównania. 6. Dla ułatwienia czytania i pracy liczby w tabeli statystycznej należy umieścić na środku kolumny, ściśle jedna pod drugą: jednostki pod jednostkami, przecinek pod przecinkiem. 7. Wskazane jest zaokrąglanie liczb z tym samym stopniem dokładności (do całego znaku, do jednej dziesiątej). 8. Brak danych oznaczany jest mnożnikiem „h”, jeżeli pozycja ta nie ma być wypełniona, brak informacji oznaczany jest wielokropkiem (...) lub n. d. lub n. Św., w przypadku braku zjawiska, wstawia się myślnik (-). 9. Aby wyświetlić bardzo małe liczby, użyj notacji 0.0 lub 0.00. 10. Jeżeli liczbę uzyskuje się na podstawie obliczeń warunkowych, to jest ona ujęta w nawiasy, numerom wątpliwym towarzyszy znak zapytania, a wstępnym - znak „!”. Tam, gdzie potrzebne są dodatkowe informacje, tabelom statystycznym towarzyszą przypisy i uwagi wyjaśniające na przykład charakter konkretnego wskaźnika, zastosowaną metodologię itp. Przypisy są używane do wskazania okoliczności ograniczających, które należy wziąć pod uwagę podczas czytania tabeli. Przy przestrzeganiu tych zasad tabela statystyczna staje się głównym środkiem prezentowania, przetwarzania i podsumowywania informacji statystycznych o stanie i rozwoju badanych zjawisk społeczno-gospodarczych. 4. Graficzne reprezentacje informacji statystycznych Wskaźniki liczbowe uzyskane w wyniku podsumowania lub analizy statystycznej jako całość można przedstawić nie tylko w formie tabelarycznej, ale także graficznej. Wykorzystanie wykresów do prezentacji informacji statystycznych umożliwia nadanie wizualizacji i wyrazistości danych statystycznych, ułatwienie ich percepcji, aw wielu przypadkach analizy. Różnorodność graficznych reprezentacji wskaźników statystycznych daje ogromne możliwości najbardziej wyrazistego zademonstrowania zjawiska lub procesu. Wykresy w statystyce nazywane są obrazy warunkowe wartości liczbowych i ich stosunków w postaci różnych obrazów geometrycznych - punktów, linii, płaskich figur itp. Wykres statystyczny pozwala na natychmiastową ocenę charakteru badanego zjawiska, jego nieodłącznych wzorców i cech, trendów rozwojowych oraz relacji charakteryzujących je wskaźników. Każdy wykres składa się z obrazu graficznego i elementów pomocniczych. Obraz graficzny to zbiór punktów, linii i kształtów reprezentujących dane statystyczne. Elementy pomocnicze wykresu to nazwa pospolita wykresu, osie współrzędnych, skale, siatki liczbowe oraz dane liczbowe, które uzupełniają i udoskonalają wyświetlane wskaźniki. Elementy pomocnicze ułatwiają odczytanie wykresu i jego interpretację. Tytuł wykresu powinien zwięźle i dokładnie opisywać jego zawartość. Teksty objaśniające mogą być umieszczone w obrazie graficznym lub obok niego, lub umieszczone poza nim. Osie współrzędnych z nadrukowanymi skalami i siatkami numerycznymi są niezbędne do kreślenia i używania go. Skale mogą być prostoliniowe lub krzywoliniowe (kołowe), jednorodne (liniowe) i nierówne. Często wskazane jest stosowanie tzw. skal sprzężonych zbudowanych na jednej lub dwóch równoległych liniach. Najczęściej jedna ze skal sprzężonych służy do odczytu wartości bezwzględnych, a druga - odpowiednich względnych. Liczby na szalach układane są równomiernie, przy czym ostatnia liczba musi przekraczać maksymalny poziom wskaźnika, którego wartość mierzona jest na tej skali. Siatka liczbowa z reguły powinna mieć linię bazową, której rolę pełni zwykle oś x. Wykresy statystyczne można klasyfikować według różnych kryteriów: przeznaczenia (treści), sposobu budowy i charakteru obrazu graficznego. W zależności od treści lub celu możemy wyróżnić: 1) wykresy porównania w przestrzeni; 2) wykresy różnych wartości względnych (struktury, dynamika itp.); 3) wykresy szeregów wariacyjnych; 4) harmonogramy praktyk według terytoriów; 5) wykresy powiązanych ze sobą wskaźników itp. Ze względu na sposób konstruowania grafik można je podzielić na wykresy i mapy statystyczne. Wykresy są najczęstszym sposobem reprezentacji graficznej. Są to wykresy zależności ilościowych. Rodzaje i metody ich budowy są zróżnicowane. Diagramy służą do wizualnego porównywania w różnych aspektach (przestrzennych, czasowych itp.) niezależnych od siebie wartości: terytoriów, populacji itp. W tym przypadku porównanie badanych populacji odbywa się według pewnych istotnych różnic atrybut. Mapy statystyczne - wykresy rozkładu ilościowego na powierzchni. W swoim głównym celu ściśle przylegają do diagramów i są specyficzne tylko w tym sensie, że są warunkowymi reprezentacjami danych statystycznych na konturowej mapie geograficznej, to znaczy pokazują przestrzenny rozkład lub przestrzenny rozkład danych statystycznych. W zależności od charakteru obrazu graficznego wyróżnia się wykresy kropkowe, liniowe, płaskie (kolumnowe, paskowe, kwadratowe, kołowe, sektorowe, kręcone) oraz wolumetryczne. Podczas konstruowania diagramów rozrzutu zestawy punktów są używane jako obrazy graficzne, podczas gdy podczas konstruowania diagramów liniowych używane są linie. Podstawową zasadą konstruowania wszystkich diagramów planarnych jest przedstawienie wielkości statystycznych w postaci figur geometrycznych. Zgodnie z obrazem graficznym mapy statystyczne dzielą się na kartogramy i kartogramy. W zależności od zakresu zadań do rozwiązania wyróżnia się diagramy porównawcze, diagramy strukturalne i diagramy dynamiki. Najczęściej spotykanymi wykresami porównawczymi są wykresy słupkowe, których zasadą budowy jest wyświetlanie wskaźników statystycznych w postaci pionowo ułożonych prostokątów – słupków. Każdy słupek obrazuje wartość odrębnego poziomu badanego szeregu statystycznego. Porównanie wskaźników statystycznych jest więc możliwe, ponieważ wszystkie porównywane wskaźniki wyrażone są w jednej jednostce miary. Podczas konstruowania wykresów słupkowych konieczne jest narysowanie układu współrzędnych prostokątnych, w których znajdują się słupki. Podstawy kolumn znajdują się na osi poziomej, wielkość podstawy jest ustalana arbitralnie, ale jest ustawiona tak samo dla wszystkich. Skala określająca skalę wysokości kolumn znajduje się wzdłuż osi pionowej. Pionowy rozmiar każdego słupka odpowiada rozmiarowi statystyki wyświetlanej na wykresie. Zatem dla wszystkich słupków tworzących wykres tylko jeden wymiar jest zmienną. Rozmieszczenie kolumn w polu wykresu może być różne: 1) w tej samej odległości od siebie; 2) blisko siebie; 3) w prywatnych nakładach na siebie. Zasady konstruowania wykresów słupkowych pozwalają na jednoczesne umieszczanie obrazów kilku wskaźników na tej samej osi poziomej. W tym przypadku kolumny są ułożone w grupy, z których dla każdego można przyjąć inny wymiar o różnych cechach. Odmiany wykresów słupkowych składają się na tzw. wykresy paskowe (lub paskowe). Ich różnica polega na tym, że podziałka umieszczona jest poziomo u góry i określa rozmiar pasków na całej długości. Zakres wykresów słupkowych i paskowych jest taki sam, ponieważ zasady ich budowy są identyczne. Jednowymiarowość wyświetlanych wskaźników statystycznych oraz ich jednolitość skali dla różnych kolumn i pasków wymaga spełnienia jednego warunku: zachowania proporcjonalności (kolumny - w wysokości, paski - w długości) i proporcjonalności do wyświetlanych wartości. Aby spełnić to wymaganie, konieczne jest: po pierwsze, aby skala, na której ustawiony jest rozmiar słupka (paska), zaczynała się od zera; po drugie, skala ta musi być ciągła, tj. obejmować wszystkie liczby danego szeregu statystycznego; przerwanie skali i odpowiednio kolumn (pasm) jest niedozwolone. Nieprzestrzeganie tych zasad prowadzi do zniekształcenia graficznego przedstawienia analizowanego materiału statystycznego. Wykresy słupkowe i słupkowe jako metoda graficznej reprezentacji danych statystycznych są zasadniczo wymienne, tj. rozważane wskaźniki statystyczne mogą być równie dobrze reprezentowane zarówno przez słupki, jak i słupki. W obu przypadkach do zobrazowania wielkości zjawiska posługuje się jednym pomiarem każdego prostokąta – wysokością słupa lub długością paska. Dlatego zakres tych dwóch diagramów jest zasadniczo taki sam. Różne wykresy kolumnowe (wstążkowe) to wykresy kierunkowe. Różnią się one od zwykłego dwustronnego układu kolumn lub pasów i mają początek skali w środku. Zazwyczaj takie diagramy służą do wyświetlania wartości o przeciwnej wartości jakościowej. Porównanie między kolumnami (pasmami) skierowanymi w różnych kierunkach jest mniej efektywne niż te, które znajdują się obok siebie w tym samym kierunku. Mimo to analiza wykresów kierunkowych pozwala na wyciągnięcie sensownych wniosków, gdyż specjalny układ daje wykresowi jasny obraz. Dwustronna grupa obejmuje diagramy czystych odchyleń. W nich paski są skierowane w obu kierunkach od pionowej linii zerowej: w prawo - dla wzrostu, w lewo - dla spadku. Za pomocą takich diagramów wygodnie jest przedstawić odchylenia od planu lub pewien poziom przyjęty jako podstawa porównania. Istotną zaletą rozważanych wykresów jest możliwość zobaczenia zakresu fluktuacji badanej cechy statystycznej, co samo w sobie ma duże znaczenie dla analizy. Do prostego porównania niezależnych od siebie wskaźników można również wykorzystać diagramy, których zasada budowy polega na tym, że porównywane wielkości są przedstawiane jako regularne figury geometryczne, które są zbudowane w taki sposób, że ich obszary są odniesione do siebie tak, jak przedstawione wielkości przez te liczby. Innymi słowy, diagramy te wyrażają wielkość przedstawionego zjawiska poprzez wielkość ich obszaru. Aby uzyskać diagramy tego typu, stosuje się różne kształty geometryczne - kwadrat, koło, rzadziej prostokąt. Wiadomo, że pole kwadratu jest równe kwadratowi jego boku, a pole koła określa się proporcjonalnie do kwadratu jego promienia. Dlatego, aby zbudować diagramy, należy najpierw wyciągnąć pierwiastek z porównywanych wartości, a następnie na podstawie uzyskanych wyników określić bok kwadratu lub promień koła, zgodnie z przyjętą skalą. Najbardziej wyrazista i łatwo dostrzegalna jest metoda konstruowania diagramów porównawczych w postaci znaków figuralnych. W tym przypadku agregaty statystyczne są reprezentowane nie przez figury geometryczne, ale przez symbole lub znaki. Zaletą tej metody reprezentacji graficznej jest wysoki stopień przejrzystości, w uzyskaniu podobnego obrazu, który odzwierciedla zawartość porównywanych populacji. Najważniejszą cechą każdego diagramu jest skala. Dlatego, aby poprawnie zbudować wykres kręcony, konieczne jest określenie jednostki rozliczeniowej. Jako ta ostatnia pobierana jest osobna cyfra (symbol), której warunkowo przypisuje się określoną wartość liczbową. Badana wartość statystyczna jest reprezentowana przez oddzielną liczbę figur o tym samym rozmiarze, kolejno umieszczonych na rysunku. Jednak w większości przypadków nie jest możliwe przedstawienie statystyki z pełną liczbą cyfr. Ostatnią z nich trzeba podzielić na części, gdyż pod względem skali jeden znak jest zbyt dużą jednostką miary. Zwykle ta część jest określana przez oko. Trudność jego dokładnego zdefiniowania jest wadą kręconych diagramów. Nie dąży się jednak do większej dokładności prezentacji danych statystycznych, a wyniki są dość zadowalające. Z reguły wykresy figurowe są powszechnie wykorzystywane do popularyzacji statystyki i reklamy. Główną strukturą diagramów strukturalnych jest graficzne przedstawienie składu agregatów statystycznych, scharakteryzowanego jako stosunek różnych części każdego z agregatów. Skład populacji statystycznej można przedstawić graficznie za pomocą wskaźników bezwzględnych i względnych. W pierwszym przypadku nie tylko rozmiar części, ale także rozmiar wykresu jako całości są określane przez wartości statystyczne i zmieniają się zgodnie ze zmianami w tym drugim. W drugim nie zmienia się rozmiar całego wykresu (bo suma wszystkich części dowolnego zestawu wynosi 100%), ale zmieniają się tylko rozmiary poszczególnych jego części. Graficzne przedstawienie składu populacji w ujęciu bezwzględnym i względnym wskaźników przyczynia się do głębszej analizy i pozwala na porównania międzynarodowe oraz porównania zjawisk społeczno-gospodarczych. Najpopularniejszym sposobem graficznego przedstawienia struktury populacji statystycznych jest wykres kołowy, który jest uważany za główną formę wykresu do tego celu. Wynika to z faktu, że ideę całości bardzo dobrze i wyraźnie wyraża okrąg, który reprezentuje całość. Ciężar właściwy każdej części populacji na wykresie kołowym charakteryzuje się wartością kąta środkowego (kąt między promieniami koła). Suma wszystkich kątów koła, równa 360°, równa się 100%, a zatem przyjmuje się, że 1% jest równy 3,6°. Zastosowanie wykresów kołowych pozwala nie tylko graficznie zobrazować strukturę populacji i jej zmiany, ale także pokazać dynamikę liczebności tej populacji. W tym celu budowane są koła proporcjonalne do objętości badanej cechy, a następnie poszczególne jej części są rozróżniane według sektorów. Rozważana metoda graficznego przedstawienia struktury populacji ma zarówno zalety, jak i wady. Tak więc wykres kołowy zachowuje widoczność i wyrazistość tylko w przypadku niewielkiej liczby części populacji, w przeciwnym razie jego użycie jest nieskuteczne. Dodatkowo widoczność wykresu kołowego maleje przy niewielkich zmianach w strukturze przedstawionych populacji: jest tym większa, im różnice w porównywanych strukturach są bardziej znaczące. Zaletą diagramów strukturalnych słupkowych (wstążkowych) w porównaniu z wykresami kołowymi jest ich duża pojemność, możliwość odzwierciedlenia większej ilości przydatnych informacji. Jednak wykresy te są bardziej efektywne w przypadku niewielkich różnic w strukturze badanej populacji. Dynamiczne diagramy są budowane, aby przedstawiać i oceniać rozwój zjawiska w czasie. Do wizualnej reprezentacji zjawisk w ciągu dynamicznym stosuje się wykresy słupkowe, paskowe, kwadratowe, kołowe, liniowe, promieniowe itp. Wybór rodzaju wykresów zależy głównie od cech danych wyjściowych, celu badania. Na przykład, jeśli istnieje seria dynamiki z kilkoma nierówno rozmieszczonymi poziomami w czasie (1914, 1049, 1980, 1985, 1996, 2003), to dla przejrzystości często stosuje się wykresy słupkowe, kwadratowe lub kołowe. Są imponujące wizualnie, dobrze zapadają w pamięć, ale nie nadają się do przedstawiania dużej liczby poziomów, ponieważ są nieporęczne. Gdy liczba poziomów w ciągu dynamiki jest duża, wskazane jest stosowanie wykresów liniowych, które odwzorowują ciągłość procesu rozwoju w postaci ciągłej linii łamanej. Ponadto wykresy liniowe są wygodne w użyciu: 1) jeżeli celem opracowania jest zobrazowanie ogólnej tendencji i charakteru rozwoju zjawiska; 2) gdy konieczne jest wyświetlenie kilku szeregów czasowych na jednym wykresie w celu ich porównania; 3) jeśli najistotniejsze jest porównanie tempa wzrostu, a nie poziomów. Do budowy wykresów liniowych używany jest układ współrzędnych prostokątnych. Zazwyczaj na osi odciętych wykreślany jest czas (lata, miesiące itp.), a na osi rzędnych wymiary przedstawianych zjawisk lub procesów. Skale są stosowane na osi Y. Szczególną uwagę należy zwrócić na ich wybór, ponieważ od tego zależy ogólny wygląd wykresu. Zapewnienie równowagi, proporcjonalności między osiami współrzędnych jest konieczne na wykresie ze względu na to, że nierównowaga między osiami współrzędnych daje błędny obraz rozwoju zjawiska. Jeśli skala dla skali na osi odciętych jest bardzo rozciągnięta w porównaniu ze skalą na osi rzędnych, to wahania dynamiki zjawisk są mało widoczne i odwrotnie, wzrost skali wzdłuż osi rzędnych w porównaniu ze skalą na osi odciętych daje ostre fluktuacje. Równe okresy czasu i rozmiary poziomów powinny odpowiadać równym segmentom skali. W praktyce statystycznej najczęściej stosuje się obrazy graficzne o jednolitych skalach. Wzdłuż odciętych są one pobierane proporcjonalnie do liczby okresów, a wzdłuż rzędnej proporcjonalnie do samych poziomów. Skala jednolitej skali będzie długością odcinka traktowaną jako jednostka. Często jeden wykres liniowy zawiera kilka krzywych, które dają porównawczy opis dynamiki różnych wskaźników lub tego samego wskaźnika. Jednak nie należy umieszczać więcej niż 3-4 krzywych na jednym wykresie, ponieważ duża ich liczba nieuchronnie komplikuje rysunek, a wykres liniowy traci przejrzystość. W niektórych przypadkach narysowanie dwóch krzywych na jednym wykresie umożliwia jednoczesne zobrazowanie dynamiki trzeciego wskaźnika, jeśli jest to różnica między dwoma pierwszymi. Na przykład, przedstawiając dynamikę dzietności i śmiertelności, obszar między dwiema krzywymi pokazuje wielkość naturalnego przyrostu lub naturalnego spadku populacji. Czasami konieczne jest porównanie dynamiki dwóch wskaźników z różnymi jednostkami miary na wykresie. W takich przypadkach będziesz potrzebować nie jednej, ale dwóch łusek. Jeden z nich umieszczony jest po prawej stronie, drugi po lewej. Jednak takie porównanie krzywych nie daje wystarczająco pełnego obrazu dynamiki tych wskaźników, gdyż skale są arbitralne. Dlatego też porównanie dynamiki poziomu dwóch heterogenicznych wskaźników należy przeprowadzić na zasadzie wykorzystania jednej skali po przeliczeniu wartości bezwzględnych na względne. Wykresy liniowe ze skalą liniową mają jedną wadę, która zmniejsza ich wartość poznawczą: jednolita skala pozwala mierzyć i porównywać tylko bezwzględne wzrosty lub spadki wskaźników odzwierciedlonych na wykresie w okresie badania. Jednak badając dynamikę, ważna jest znajomość względnych zmian badanych wskaźników w stosunku do osiągniętego poziomu lub tempa ich zmiany. To względne zmiany ekonomicznych wskaźników dynamiki są zniekształcone, gdy są przedstawiane na wykresie współrzędnych z jednolitą skalą pionową. Ponadto w konwencjonalnych współrzędnych traci wszelką klarowność, a nawet staje się niemożliwe do wyświetlenia dla szeregów czasowych o gwałtownie zmieniających się poziomach, które zwykle występują w szeregach czasowych przez długi okres czasu. W takich przypadkach należy zrezygnować ze skali jednolitej i wykresu opartego na systemie półlogarytmicznym. Główną ideą systemu półlogarytmicznego jest to, że równe segmenty liniowe odpowiadają równym wartościom logarytmów liczb. Zaletą tego podejścia jest możliwość zmniejszenia rozmiaru dużych liczb poprzez ich odpowiedniki logarytmiczne. Jednak przy skali skali w postaci logarytmów wykres jest trudny do zrozumienia. Obok logarytmów wskazanych na skali skali należy wpisać same liczby, charakteryzujące poziomy wyświetlanych szeregów dynamiki, które odpowiadają wskazanym liczbom logarytmów. Grafy tego rodzaju nazywane są grafami na siatce półlogarytmicznej. Siatka semilogarytmiczna to siatka, w której skala liniowa jest wykreślona na jednej osi, a logarytmiczna na drugiej. Dynamika jest również przedstawiana za pomocą diagramów promieniowych wykreślonych we współrzędnych biegunowych. Diagramy promieniowe mają na celu wizualną reprezentację pewnego rytmicznego ruchu w czasie. Najczęściej wykresy te służą do zilustrowania wahań sezonowych. Diagramy promieniowe dzielą się na zamknięte i spiralne. Zgodnie z techniką konstrukcyjną diagramy promieniowe różnią się od siebie w zależności od tego, co przyjmuje się za punkt odniesienia - środek okręgu lub okrąg. Zamknięte diagramy odzwierciedlają śródroczny cykl dynamiki dowolnego roku. Wykresy spiralne przedstawiają roczny cykl dynamiki na przestrzeni kilku lat. Konstrukcja zamkniętych diagramów sprowadza się do następującego: narysowany jest okrąg, średnia miesięczna jest zrównana z promieniem tego koła. Następnie cały okrąg dzieli się na 12 promieni, które są pokazane na wykresie w postaci cienkich linii. Każdy promień oznacza miesiąc, a położenie miesięcy jest podobne jak na tarczy zegara: styczeń - w miejscu, gdzie zegar wskazuje 1, luty - gdzie jest 2, itd. Na każdym promieniu w określonym miejscu robiony jest znak według do skali opartej na danych dla odpowiedniego miesiąca. Jeśli dane przekraczają średnią roczną, znak jest umieszczany poza okręgiem na przedłużeniu promienia. Następnie znaki różnych miesięcy są połączone segmentami. Jeżeli jednak za podstawę raportu przyjmiemy nie środek koła, lecz okrąg, to takie diagramy nazywamy diagramami spiralnymi. Konstrukcja wykresów spiralnych różni się od zamkniętych tym, że w nich grudzień jednego roku łączy się nie ze styczniem tego samego roku, ale ze styczniem roku następnego. Umożliwia to zobrazowanie całej serii dynamiki w formie spirali. Taki wykres jest szczególnie obrazowy, gdy wraz ze zmianami sezonowymi następuje stały wzrost z roku na rok. Mapy statystyczne to rodzaj graficznej reprezentacji danych statystycznych na schematycznej mapie geograficznej, która charakteryzuje poziom lub stopień rozmieszczenia określonego zjawiska na określonym obszarze. Sposobami przedstawiania rozmieszczenia terytorialnego są kreskowanie, kolorowanie tła lub kształty geometryczne. Istnieją kartogramy i kartogramy. Kartogramy - jest to schematyczna mapa geograficzna, na której kreskowanie o różnej gęstości, kropki lub zabarwienie o określonym stopniu nasycenia pokazuje porównawcze natężenie dowolnego wskaźnika w obrębie każdej jednostki podziału terytorialnego naniesionej na mapę (np. gęstość zaludnienia według regionu lub republiki, podział regionów według plonów itp.). Kartogramy podzielone są na tło i punkt. Kartogram tło - rodzaj kartogramu, na którym cieniowanie o różnej gęstości lub zabarwieniu o określonym stopniu nasycenia pokazuje intensywność wskaźnika w obrębie jednostki terytorialnej. Kartogram punktowy - rodzaj kartogramu, w którym za pomocą kropek obrazowany jest poziom wybranego zjawiska. Kropka przedstawia jedną jednostkę w agregacie lub pewną ich liczbę, pokazując na mapie geograficznej gęstość lub częstotliwość występowania określonej cechy. Kartogramy tła z reguły służą do wyświetlania wskaźników średnich lub względnych, kropka - dla wskaźników wolumetrycznych (ilościowych) (takich jak populacja, zwierzęta gospodarskie itp.). Drugą dużą grupę map statystycznych stanowią diagramy wykresowe, będące połączeniem diagramów z mapą geograficzną. Liczby wykresów (słupki, kwadraty, koła, figury, paski) służą jako znaki graficzne w kartogramach, które umieszcza się na konturze mapy geograficznej. Kartogramy umożliwiają odzwierciedlenie geograficznie bardziej złożonych konstrukcji statystycznych i geograficznych niż kartogramy. Wśród kartodigramów należy wyróżnić karodiaki prostego porównania, wykresy przestrzennego przemieszczenia, izolinie. Na diagramie kartograficznym prostego porównania, w przeciwieństwie do diagramu konwencjonalnego, wykresy przedstawiające wartości badanego wskaźnika nie są ułożone w rzędzie, jak na schemacie konwencjonalnym, ale są rozłożone na mapie zgodnie z regionem, regionem lub krajem, który reprezentują. Elementy najprostszego schematu kartograficznego można znaleźć na mapie politycznej, na której miasta wyróżniają się różnymi kształtami geometrycznymi w zależności od liczby mieszkańców. Kontury - są to linie o jednakowej wartości wielkości w jej rozmieszczeniu na powierzchni, w szczególności na mapie geograficznej lub grafie. Izolinia odzwierciedla ciągłą zmianę badanej wielkości w zależności od dwóch innych zmiennych i jest wykorzystywana do mapowania zjawisk przyrodniczych i społeczno-gospodarczych. Izolinie służą do uzyskania charakterystyk ilościowych badanych wielkości oraz do analizy korelacji między nimi. WYKŁAD nr 4. Wartości statystyczne i wskaźniki 1. Cel i rodzaje wskaźników i wartości statystycznych Charakter i treść wskaźników statystycznych odpowiadają tym zjawiskom i procesom gospodarczym i społecznym, które je odzwierciedlają. Wszystkie kategorie lub pojęcia ekonomiczne i społeczne mają charakter abstrakcyjny, odzwierciedlają najważniejsze cechy, ogólne powiązania zjawisk. A aby zmierzyć wielkość i korelację zjawisk lub procesów, czyli nadać im odpowiednią charakterystykę ilościową, opracowują wskaźniki ekonomiczne i społeczne odpowiadające każdej kategorii (pojęciu). To właśnie zgodność wskaźników istoty kategorii ekonomicznych zapewnia jedność cech ilościowych i jakościowych zjawisk i procesów gospodarczych i społecznych. Istnieją dwa rodzaje wskaźników rozwoju gospodarczego i społecznego społeczeństwa: planowe (prognoza) i sprawozdawcze (statystyczne). Planowane wskaźniki to pewne konkretne wartości wskaźników, których osiągnięcie przewidywane jest w przyszłych okresach. Wskaźniki sprawozdawcze charakteryzują rzeczywiste warunki rozwoju gospodarczego i społecznego, poziom faktycznie osiągnięty w określonym okresie. Wskaźnik statystyczny (sprawozdawczy) - jest to obiektywna cecha ilościowa (miara) zjawiska lub procesu społecznego w jego jakościowej pewności w określonych warunkach miejsca i czasu. Każdy wskaźnik statystyczny ma jakościową treść społeczno-ekonomiczną i związaną z nim metodologię pomiaru. Wskaźnik statystyczny ma również taką lub inną formę statystyczną (strukturę). Wskaźnik może wyrażać całkowitą liczbę jednostek populacji, całkowitą sumę wartości atrybutu ilościowego tych jednostek, średnią wartość atrybutu, wartość tego atrybutu w stosunku do wartości innego itp. Wskaźnik statystyczny ma również pewną wartość ilościową lub wyrażenie liczbowe. Ta wartość liczbowa wskaźnika statystycznego, wyrażona w określonych jednostkach miary, nazywana jest jego wartością. Wartość wskaźnika zwykle zmienia się w przestrzeni i zmienia się w czasie. Dlatego obowiązkowym atrybutem wskaźnika statystycznego jest również wskazanie terytorium oraz momentu lub przedziału czasu. Wskaźniki statystyczne można warunkowo podzielić na pierwotne (wolumetryczne, ilościowe, ekstensywne) i wtórne (pochodne, jakościowe, intensywne). Podstawowe charakteryzują albo całkowitą liczbę jednostek populacji, albo sumę wartości dowolnego z ich atrybutów. Ujęte w dynamice, w zmianach w czasie, charakteryzują rozległą ścieżkę rozwoju gospodarki jako całości lub konkretnego przedsiębiorstwa w konkretnym przypadku. Zgodnie z formą statystyczną wskaźniki te są całkowitymi wartościami statystycznymi. Wskaźniki wtórne (pochodne) wyrażane są zwykle jako wartości średnie i względne, a w ujęciu dynamicznym zazwyczaj charakteryzują ścieżkę intensywnego rozwoju. Wskaźniki charakteryzujące wielkość złożonego zestawu zjawisk i procesów społeczno-gospodarczych są często nazywane syntetycznymi (PKB, dochód narodowy, społeczna wydajność pracy, koszyk konsumentów itp.). W zależności od zastosowanych jednostek miary istnieją wskaźniki naturalne, kosztów i robocizny (w roboczogodzinach, standardowych godzinach). W zależności od zakresu rozróżnia się wskaźniki obliczane na poziomie regionalnym, sektorowym itp. W zależności od dokładności odbitego zjawiska rozróżnia się wartości oczekiwane, wstępne i końcowe wskaźników. W zależności od wielkości i zawartości przedmiotu badań statystycznych rozróżnia się wskaźniki indywidualne (charakteryzujące poszczególne jednostki populacji) i sumaryczne (uogólniające). Tak więc wartości statystyczne charakteryzujące masy lub zbiory jednostek nazywane są uogólniającymi wskaźnikami statystycznymi (wartościami). Wskaźniki podsumowujące odgrywają bardzo ważną rolę w badaniach statystycznych ze względu na następujące cechy wyróżniające: 1) podać zwięzły (zwięzły) opis agregatów jednostek badanych zjawisk społecznych; 2) wyrażać powiązania i zależności istniejące między zjawiskami, a tym samym zapewniać wzajemnie powiązane badanie zjawisk; 3) scharakteryzować zmiany zachodzące w zjawiskach, wyłaniające się wzorce ich rozwoju i inne, tj. dokonać analizy ekonomicznej i statystycznej rozważanych zjawisk, w tym na podstawie dekompozycji samych wielkości uogólniających na ich części składowe, czynniki determinujące itp. Obiektywne i rzetelne badanie złożonych kategorii ekonomicznych i społecznych jest możliwe tylko w oparciu o system wskaźników statystycznych, które w jedności i wzajemnych powiązaniach charakteryzują różne aspekty i aspekty stanu i dynamiki rozwoju tych kategorii. Wskaźniki statystyczne, obiektywnie odzwierciedlające jedność i współzależności zjawisk i procesów gospodarczych i społecznych, nie są naciąganymi, arbitralnie skonstruowanymi dogmatami, ustanowionymi raz na zawsze. Wręcz przeciwnie, dynamiczny rozwój społeczeństwa, nauki, informatyki, doskonalenie metodologii statystycznej powoduje, że przestarzałe wskaźniki, które straciły na wartości zmieniają się lub znikają i pojawiają się nowe, bardziej zaawansowane wskaźniki, które obiektywnie i rzetelnie odzwierciedlają obecne warunki rozwoju społecznego. Zatem konstrukcja i doskonalenie wskaźników statystycznych powinno opierać się na przestrzeganiu dwóch podstawowych zasad: 1) obiektywność i rzeczywistość (wskaźniki muszą wiernie i adekwatnie odzwierciedlać istotę odpowiednich kategorii (koncepcji) ekonomicznych i społecznych); 2) wszechstronną trafność teoretyczną i metodologiczną (określenie wartości wskaźnika, jego mierzalności i porównywalności w dynamice musi być naukowo uzasadnione, jasno i zrozumiale sformułowane oraz jednoznacznie możliwe do zastosowania w jednolitej interpretacji). Ponadto wartości wskaźników muszą być poprawnie skwantyfikowane, biorąc pod uwagę poziom, skalę i jakościowe oznaki stanu lub rozwoju odpowiedniego zjawiska gospodarczego lub społecznego (poziom przemysłowy i regionalny, indywidualne przedsiębiorstwo lub pracownika itp. ). Jednocześnie konstrukcja wskaźników powinna mieć charakter przekrojowy, pozwalający nie tylko na podsumowanie odpowiednich wskaźników, ale także na zapewnienie ich jakościowej jednorodności w grupach i agregatach, przechodzenie od jednego wskaźnika do drugiego w celu pełnego scharakteryzować objętość i strukturę bardziej złożonej kategorii lub zjawiska. Wreszcie konstrukcja wskaźnika statystycznego, jego struktura i istota powinna przewidywać możliwość kompleksowej analizy badanego zjawiska lub procesu, scharakteryzowania cech jego rozwoju oraz określenia czynników na niego wpływających. Obliczanie wielkości statystycznych i analiza danych o badanych zjawiskach to trzeci i ostatni etap badań statystycznych. W statystyce bierze się pod uwagę kilka rodzajów wielkości statystycznych: wartości bezwzględne, względne i średnie. Generalizujące wskaźniki statystyczne obejmują również wskaźniki analityczne szeregów czasowych, indeksy itp. 2. Statystyki bezwzględne Obserwacja statystyczna, niezależnie od jej zakresu i celów, zawsze dostarcza informacji o pewnych zjawiskach i procesach społeczno-gospodarczych w postaci wskaźników bezwzględnych, tj. wskaźników będących ilościową charakterystyką zjawisk i procesów społeczno-gospodarczych w warunkach jakościowej pewności. Jakościowa pewność wskaźników absolutnych polega na tym, że są one bezpośrednio związane z konkretną treścią badanego zjawiska lub procesu, z jego istotą. W związku z tym wskaźniki bezwzględne i wartości bezwzględne powinny mieć określone jednostki miary, które najpełniej i najdokładniej odzwierciedlają ich istotę (treść). Wskaźniki bezwzględne są ilościowym wyrazem znaków zjawisk statystycznych. Na przykład wysokość jest cechą, a jej wartość jest miarą wzrostu. Wskaźnik bezwzględny powinien charakteryzować wielkość zjawiska lub procesu badanego w danym miejscu i czasie, powinien być „powiązany” z jakimś obiektem lub terytorium i może charakteryzować albo odrębną jednostkę populacji (odrębny obiekt) - przedsiębiorstwo, pracownik lub zespół jednostek reprezentujący część populacji statystycznej lub całość populacji statystycznej (np. ludność w kraju) itp. W pierwszym przypadku mówimy o poszczególne wskaźniki bezwzględne, aw drugim – o sumarycznych wskaźnikach bezwzględnych. Indywidualne wartości - wartości bezwzględne charakteryzujące wielkość poszczególnych jednostek populacji (na przykład liczba części wyprodukowanych przez jednego pracownika na zmianę, liczba dzieci w oddzielnej rodzinie). Pozyskiwane są bezpośrednio w procesie obserwacji statystycznej i są rejestrowane w pierwotnych dokumentach księgowych. Poszczególne wskaźniki uzyskuje się w procesie statystycznej obserwacji określonych zjawisk i procesów w wyniku oceny, obliczenia, pomiaru ustalonej ilościowej cechy zainteresowania. sumaryczne wartości - wartości bezwzględne uzyskuje się z reguły sumując poszczególne wartości indywidualne. Sumaryczne wskaźniki bezwzględne uzyskuje się w wyniku podsumowania i pogrupowania wartości poszczególnych wskaźników bezwzględnych. I tak np. w procesie spisu ludności państwowe organy statystyczne otrzymują ostateczne dane bezwzględne o liczbie ludności kraju, jej rozkładzie według regionu, płci, wieku itp. Wskaźniki bezwzględne mogą również obejmować wskaźniki, które uzyskuje się nie w wyniku obserwacji statystycznych, ale w wyniku dowolnych obliczeń. Z reguły wskaźniki te mają charakter różnicowy i są określane jako różnica między dwoma wskaźnikami bezwzględnymi. Na przykład przyrost naturalny (ubytek) populacji określa się jako różnicę między liczbą urodzeń a liczbą zgonów w pewnym okresie czasu; wzrost produkcji za rok określa się jako różnicę między wielkością produkcji na koniec roku a wielkością produkcji na początku roku. Podczas opracowywania długoterminowych prognoz rozwoju gospodarki kraju obliczane są szacunkowe dane dotyczące zasobów materialnych, pracy i zasobów finansowych. Jak widać na przykładach, wskaźniki te będą bezwzględne, ponieważ mają bezwzględne jednostki miary. Wartości bezwzględne odzwierciedlają naturalne podstawy zjawisk. Wyrażają one albo liczbę jednostek badanej populacji, jej poszczególnych składowych, albo ich bezwzględną wielkość w jednostkach naturalnych wynikających z ich właściwości fizycznych (takich jak waga, długość itp.) lub w jednostkach miary wynikających z ich właściwości ekonomicznych (to jest koszt, koszty pracy). Dlatego wartości bezwzględne zawsze mają pewien wymiar. Ponadto bezwzględne wskaźniki statystyczne są zawsze nazywane liczbami, tj. w zależności od charakteru opisywanych przez nie procesów i zjawisk wyrażane są w jednostkach miary fizycznych, kosztów i pracy. Liczniki naturalne charakteryzują zjawiska w ich naturalnej postaci i wyrażane są w postaci długości, masy, objętości itp. lub liczby jednostek, liczby zdarzeń. Jednostki naturalne obejmują takie jednostki miary jak tony, kilogramy, metry itp. W niektórych przypadkach stosuje się połączone jednostki miary, które są iloczynem dwóch wielkości wyrażonych w różnych wymiarach. Na przykład produkcja energii elektrycznej jest mierzona w kilowatogodzinach, praca przewozowa jest mierzona w tonokilometrach itp. Do grupy naturalnych jednostek miar zalicza się również tzw. warunkowo naturalne jednostki miar. Służą do uzyskania sumarycznych wartości bezwzględnych w przypadku, gdy poszczególne wartości charakteryzują poszczególne rodzaje produktów, które są podobne w swoich właściwościach konsumenckich, ale różnią się np. zawartością tłuszczu, alkoholu, kalorii itp. przypadku jeden z rodzajów produktów jest traktowany jako warunkowy miernik naturalny, a za pomocą współczynników konwersji wyrażających stosunek właściwości konsumenckich (czasami pracochłonność, koszt itp.) Poszczególnych odmian podaje się wszystkie odmiany tego produktu. Jednostki miary pracy służą do scharakteryzowania wskaźników, które pozwalają oszacować koszty pracy, odzwierciedlając dostępność, dystrybucję i wykorzystanie zasobów pracy (na przykład pracochłonność pracy wykonywanej w osobodniach). Liczniki naturalne, a czasem pracy, nie pozwalają na uzyskanie zbiorczych wskaźników bezwzględnych w zakresie produktów heterogenicznych. Pod tym względem jednostki miary kosztów są uniwersalne, które dają kosztową (pieniężną) ocenę zjawisk społeczno-gospodarczych, charakteryzują koszt określonego produktu lub ilość wykonanej pracy. Na przykład tak ważne wskaźniki dla gospodarki kraju, jak dochód narodowy, produkt krajowy brutto, są wyrażone w kategoriach pieniężnych, a na poziomie przedsiębiorstwa - zysk, środki własne i pożyczone. W statystyce największą preferencję mają jednostki kosztów, ponieważ rachunek kosztów jest uniwersalny, ale nie zawsze może być akceptowany. Wskaźniki bezwzględne można obliczyć w czasie i przestrzeni. Na przykład dynamika populacji Federacji Rosyjskiej w latach 1991-2004 odzwierciedla czynnik czasu, a poziom cen wyrobów piekarniczych w regionach Federacji Rosyjskiej w 2004 r. charakteryzuje się porównaniem przestrzennym. Biorąc pod uwagę bezwzględne wskaźniki w czasie (w dynamice), ich rejestrację można przeprowadzić w określonym dniu, tj. W dowolnym momencie (wartość środków trwałych przedsiębiorstwa na początek roku) i dla dowolnego okres czasu (liczba urodzeń w ciągu roku). W pierwszym przypadku wskaźniki są natychmiastowe, w drugim - interwał. Z punktu widzenia pewności przestrzennej wskaźniki bezwzględne dzielą się na: ogólnoterytorialne, regionalne i lokalne. Na przykład wielkość PKB (produkt krajowy brutto) jest ogólnym wskaźnikiem terytorialnym, wielkość GRP (produkt regionalny brutto) jest cechą regionalną, liczba osób zatrudnionych w mieście jest cechą lokalną. W konsekwencji pierwsza grupa wskaźników charakteryzuje kraj jako całość, regionalny – określony region, lokalny – odrębne miasto, osadę itp. Wskaźniki bezwzględne nie odpowiadają na pytanie, jaki udział ma ta lub inna część w ogólnej populacji, nie mogą scharakteryzować poziomów planowanego zadania, stopnia realizacji planu, intensywności tego lub innego zjawiska, ponieważ nie są zawsze nadają się do porównania i dlatego są często używane tylko do obliczania wartości względnych. 3. Statystyki względne Obok wartości bezwzględnych jedną z najważniejszych form uogólniania wskaźników w statystyce są wartości względne. We współczesnym życiu często stajemy przed koniecznością porównywania i kontrastowania dowolnych faktów. Nie tylko dlatego, że istnieje powiedzenie: „Wszystko jest znane w porównaniu”. Wyniki wszelkich porównań są wyrażone za pomocą wartości względnych. Wartości względne są wskaźnikami uogólniającymi, które wyrażają miarę stosunków ilościowych związanych z określonymi zjawiskami lub obiektami statystycznymi. Przy obliczaniu wartości względnej bierze się stosunek dwóch powiązanych ze sobą wartości (w większości bezwzględnych), tj. mierzony jest ich stosunek, co jest bardzo ważne w analizie statystycznej. Wartości względne są szeroko stosowane w badaniach statystycznych, ponieważ pozwalają na porównanie różnych wskaźników i czynią takie porównanie czytelnym. Wartości względne są obliczane jako stosunek dwóch liczb. W tym przypadku licznik jest nazywany porównywaną wartością, a mianownik jest podstawą porównania względnego. W zależności od charakteru badanego zjawiska i celów badania wartość podstawowa może przybierać różne wartości, co prowadzi do różnych form wyrażania wartości względnych. Wielkości względne można zmierzyć: 1) we współczynnikach; jeśli jako podstawę porównania przyjmuje się 1, to wartość względna jest wyrażona jako liczba całkowita lub ułamkowa, pokazująca ile razy jedna wartość jest większa od drugiej lub jaka jest jej część; 2) procentowo, jeżeli jako podstawę porównania przyjmuje się 100; 3) w ppm, jeżeli za podstawę porównania przyjmuje się 1000; 4) w decymilach, jeżeli za podstawę porównania przyjmuje się 10 000; 5) w nazwanych liczbach (km, kg, ha) itp. W każdym konkretnym przypadku wybór takiej lub innej formy względnej wartości jest określony przez cele badania i istotę społeczno-ekonomiczną, której miarą jest pożądany wskaźnik względny. Zgodnie z ich treścią względne wartości dzielą się na następujące typy: wypełnienie zobowiązań umownych; dynamika; Struktury; koordynacja; intensywność; porównania. Względna wartość zobowiązań umownych to stosunek faktycznego wykonania umowy do poziomu określonego w umowie: Wartość ta odzwierciedla stopień, w jakim przedsiębiorstwo wypełniło swoje zobowiązania umowne i może być wyrażona jako liczba (całkowita lub ułamkowa) lub w procentach. W takim przypadku konieczne jest, aby licznik i mianownik pierwotnego stosunku odpowiadał temu samemu obowiązkowi umownemu. Względne wartości dynamiki - stopy wzrostu - nazywane są wskaźnikami charakteryzującymi zmianę wielkości zjawisk społecznych w czasie. Względna wielkość dynamiki pokazuje zmianę tego samego typu zjawisk w pewnym okresie czasu. Wartość ta jest obliczana przez porównanie każdego kolejnego okresu z początkowym lub poprzednim. W pierwszym przypadku uzyskujemy podstawowe wartości dynamiki, a w drugim wartości łańcuchowe dynamiki. Zarówno te, jak i inne wartości są wyrażone jako współczynniki lub procenty. Należy zwrócić szczególną uwagę na wybór podstawy porównania przy obliczaniu względnych wartości dynamiki, a także innych względnych wskaźników, ponieważ praktyczna wartość uzyskanego wyniku w dużej mierze zależy od tego. Względne wartości struktury charakteryzują części składowe badanej populacji. Względną wartość populacji oblicza się według wzoru:  Względne wartości konstrukcji, zwane potocznie ciężarem właściwym, oblicza się dzieląc pewną część całości przez sumę, przyjmowaną jako 100%. Ta wartość ma jedną cechę - suma wartości względnych badanej populacji jest zawsze równa 100% lub 1 (w zależności od tego, jak jest wyrażona). Względne wartości struktury są wykorzystywane do badania złożonych zjawisk, które dzielą się na kilka grup lub części, w celu scharakteryzowania ciężaru właściwego (udziału) każdej grupy w ogólnej sumie. Względne wartości koordynacji charakteryzują stosunek poszczególnych części populacji do jednej z nich, przyjęty jako podstawa do porównania. Przy określaniu tej wartości jako podstawę do porównania przyjmuje się jedną z części całości. Dzięki tej wartości możesz obserwować proporcje między składnikami populacji. Wskaźnikami koordynacji są na przykład liczba mieszkańców miast na 100 wsi; liczba kobiet na 100 mężczyzn; Ponieważ licznik i mianownik względnych wartości koordynacji mają tę samą jednostkę miary, wartości te są wyrażane nie w nazwach liczb, ale w procentach, ppm lub wielokrotnych stosunkach. Wartości natężenia względnego to wskaźniki, które określają występowanie danego zjawiska w dowolnym środowisku. Oblicza się je jako stosunek wartości bezwzględnej danego zjawiska do wielkości środowiska, w którym się ono rozwija. Wartości względnej intensywności są szeroko stosowane w praktyce statystycznej. Przykładami tej wartości mogą być stosunek liczby ludności do obszaru, na którym zamieszkuje, produktywność kapitału, zapewnienie ludności opieki medycznej (liczba lekarzy na 10 000 ludności), poziom wydajności pracy (produkcja na pracownika lub na jednostkę czasu pracy) itp. . Zatem względne wartości intensywności charakteryzują efektywność wykorzystania różnego rodzaju zasobów (materialnych, finansowych, pracy), społeczny i kulturowy poziom życia ludności kraju oraz wiele innych aspektów życia publicznego. Wartości intensywności względnej są obliczane przez porównanie przeciwnie nazwanych wartości bezwzględnych, które są ze sobą w określonej relacji i w przeciwieństwie do innych typów wartości względnych są zwykle nazywane liczbami i mają wymiar tych wartości bezwzględnych, których stosunek wyrażają. Niemniej jednak w niektórych przypadkach, gdy otrzymane wyniki obliczeń są zbyt małe, mnoży się je dla przejrzystości przez 1000 lub 10 000, uzyskując charakterystykę w ppm i decymilu. Szczególnie interesujące są różne wartości intensywności względnej - produkt krajowy brutto na mieszkańca. Rozwijając ten wskaźnik w kontekście branż lub określonych rodzajów produktów, można uzyskać następujące wartości względnej intensywności: produkcji energii elektrycznej, paliw, maszyn, urządzeń, usług, towarów i innych na jednego mieszkańca. Względne wartości porównawcze to względne wskaźniki wynikające z porównania poziomów o tej samej nazwie związanych z różnymi obiektami lub terytoriami, ujętych w tym samym okresie lub w jednym momencie. Są one również obliczane we współczynnikach lub procentach i pokazują, ile razy jedna porównywalna wartość jest większa lub mniejsza od innej. Względne wartości porównawcze są szeroko stosowane w ocenie porównawczej różnych wskaźników efektywności poszczególnych przedsiębiorstw, miast, regionów, krajów. W tym przypadku na przykład wyniki pracy konkretnego przedsiębiorstwa są traktowane jako podstawa do porównania i są konsekwentnie skorelowane z wynikami podobnych przedsiębiorstw w innych branżach, regionach, krajach itp. W statystycznym badaniu zjawisk społecznych wartości bezwzględne i względne uzupełniają się nawzajem. Jeśli wartości bezwzględne charakteryzują niejako statykę zjawisk, to wartości względne umożliwiają badanie stopnia, dynamiki i intensywności rozwoju zjawisk. Do prawidłowego zastosowania i wykorzystania wartości bezwzględnych i względnych w analizie ekonomicznej i statystycznej niezbędne jest: 1) uwzględniać specyfikę zjawisk przy wyborze i obliczaniu jednego lub drugiego rodzaju wartości bezwzględnych i względnych (ponieważ ilościowa strona zjawisk charakteryzujących się tymi wartościami jest nierozerwalnie związana z ich stroną jakościową); 2) zapewnienie porównywalności porównywanej i podstawowej wartości bezwzględnej pod względem wielkości i składu zjawisk, które reprezentują, poprawności metod uzyskiwania samych wartości bezwzględnych; 3) kompleksowo wykorzystywać wartości względne i bezwzględne w procesie analizy i nie oddzielać ich od siebie (ponieważ zastosowanie samych wartości względnych w oderwaniu od bezwzględnych może prowadzić do niedokładnych, a nawet błędnych wniosków). WYKŁAD №5. Średnie wartości i wskaźniki zmienności 1. Wartości średnie i ogólne zasady ich obliczania Wartości średnie odnoszą się do uogólniających wskaźników statystycznych, które dają sumaryczną (końcową) charakterystykę masowych zjawisk społecznych, ponieważ są budowane na podstawie dużej liczby indywidualnych wartości o różnym atrybucie. Aby wyjaśnić istotę wartości średniej, należy wziąć pod uwagę cechy kształtowania się wartości znaków tych zjawisk, zgodnie z którymi obliczana jest wartość średnia. Wiadomo, że jednostki każdego zjawiska masowego mają wiele cech. Niezależnie od tego, który z tych znaków zostanie przyjęty, jego wartości dla poszczególnych jednostek będą różne, zmieniają się lub, jak mówią statystyki, różnią się w zależności od jednostki. Na przykład wynagrodzenie pracownika zależy od jego kwalifikacji, charakteru pracy, stażu pracy i szeregu innych czynników, a zatem zmienia się w bardzo szerokim zakresie. Skumulowany wpływ wszystkich czynników determinuje wysokość zarobków każdego pracownika. Niemniej jednak możemy mówić o przeciętnych miesięcznych zarobkach pracowników w różnych sektorach gospodarki. Tutaj operujemy typową, charakterystyczną wartością atrybutu zmiennego, odniesionego do jednostki dużej populacji. Średnia wartość odzwierciedla ogólne, charakterystyczne dla wszystkich jednostek badanej populacji. Równocześnie równoważy wpływ wszystkich czynników działających na wielkość atrybutu poszczególnych jednostek populacji, jakby wzajemnie je znosząc. Poziom (lub rozmiar) dowolnego zjawiska społecznego jest określony przez działanie dwóch grup czynników. Niektóre z nich mają charakter ogólny i główny, stale funkcjonujący, ściśle związany z charakterem badanego zjawiska lub procesu i tworzą typowy dla wszystkich jednostek badanej populacji, co znajduje odzwierciedlenie w wartości średniej. Inne są indywidualne, ich działanie jest mniej wyraźne i epizodyczne, przypadkowe. Działają w przeciwnym kierunku, powodują różnice między cechami ilościowymi poszczególnych jednostek populacji, dążąc do zmiany stałej wartości badanych cech. Działanie poszczególnych znaków jest wygaszane w wartości średniej. W skumulowanym wpływie czynników typowych i jednostkowych, które są zrównoważone i wzajemnie znoszone w charakterystyce uogólniającej, w postaci ogólnej przejawia się fundamentalne prawo wielkich liczb znane ze statystyki matematycznej. W sumie poszczególne wartości znaków łączą się we wspólną masę i niejako rozpuszczają się. Stąd średnia działa jako wartość „bezosobowa”, która może odbiegać od indywidualnych wartości cech, nie pokrywając się ilościowo z żadną z nich. Średnia odzwierciedla zatem ogólną, charakterystyczną i typową dla całej populacji ze względu na wzajemne znoszenie w niej przypadkowych, nietypowych różnic między znakami jej poszczególnych jednostek, ponieważ jej wartość jest określona niejako przez wspólną wypadkową wszystkie przyczyny. Aby jednak średnia odzwierciedlała najbardziej typową wartość cechy, nie należy jej wyznaczać dla żadnych populacji, a jedynie dla populacji składających się z jednostek jakościowo jednorodnych. Wymóg ten jest głównym warunkiem naukowego stosowania średnich i implikuje ścisły związek między metodą średnich a metodą grupowań w analizie zjawisk społeczno-gospodarczych. W związku z tym, Średnia wartość - jest to ogólny wskaźnik charakteryzujący typowy poziom zmiennej cechy na jednostkę jednorodnej populacji w określonych warunkach miejsca i czasu. Definiując w ten sposób istotę średnich, należy podkreślić, że prawidłowe obliczenie dowolnej średniej implikuje spełnienie następujących wymagań: 1) jednorodność jakościowa populacji, dla której oblicza się średnią. Obliczenie średniej dla zjawisk różnej jakości (różnych typów) jest sprzeczne z samą istotą średniej, ponieważ rozwój takich zjawisk podlega innym, a nie ogólnym prawom i przyczynom. Oznacza to, że obliczanie wartości średnich powinno opierać się na metodzie grupowania, która zapewnia selekcję zjawisk jednorodnych, tego samego typu; 2) wyłączenie wpływu na obliczenie średniej wartości przyczyn i czynników losowych, czysto indywidualnych. Osiąga się to w przypadku, gdy obliczenie średniej opiera się na wystarczająco masywnym materiale, w którym przejawia się działanie prawa dużych liczb, a wszystkie wypadki znoszą się nawzajem; 3) przy obliczaniu wartości średniej ważne jest ustalenie celu jej obliczania oraz tzw. wskaźnika określającego (właściwości), na którym ma się ona opierać. Wskaźnik determinujący może pełnić funkcję sumy wartości uśrednionej cechy, sumy jej odwrotności, iloczynu jej wartości itp. Zależność między wskaźnikiem definiującym a średnią wyraża się następująco: jeśli wszystkie wartości uśrednionej cechy są zastępowane przez ich średnią wartość, wtedy suma lub iloczyn w tym przypadku definiujący wskaźnik nie ulegnie zmianie. Na podstawie tego powiązania wskaźnika determinującego z wartością średnią budowany jest wstępny wskaźnik ilościowy do bezpośredniego obliczenia wartości średniej. Zdolność średnich do zachowania właściwości populacji statystycznych nazywana jest właściwością definiującą. Średnia obliczona dla całej populacji nazywana jest średnią ogólną, średnie obliczone dla każdej grupy nazywane są średnimi grupowymi. Średnia ogólna odzwierciedla ogólne cechy badanego zjawiska, średnia grupowa daje charakterystykę wielkości zjawiska, które rozwija się w specyficznych warunkach tej grupy. Metody obliczania mogą być różne, aw związku z tym w statystyce wyróżnia się kilka rodzajów średnich, z których główne to średnia arytmetyczna, średnia harmoniczna i średnia geometryczna. W analizie ekonomicznej wykorzystanie średnich jest skutecznym narzędziem oceny wyników postępu naukowo-technicznego, mierników społecznych oraz wyszukiwania ukrytych i niewykorzystanych rezerw rozwoju gospodarczego. Jednocześnie należy pamiętać, że nadmierna koncentracja na średnich może prowadzić do nieobiektywnych wniosków podczas prowadzenia analizy ekonomicznej i statystycznej. Wynika to z faktu, że wartości średnie, będące wskaźnikami uogólniającymi, niwelują i ignorują te różnice w cechach ilościowych poszczególnych jednostek populacji, które rzeczywiście istnieją i mogą być przedmiotem niezależnego zainteresowania. 2. Rodzaje średnich W statystykach stosuje się różne rodzaje średnich, które dzielą się na dwie duże klasy: 1) średnie mocy (średnia harmoniczna, średnia geometryczna, średnia arytmetyczna, średnia kwadratowa, średnia sześcienna); 2) średnie strukturalne (tryb, mediana). Do obliczenia średnich mocy konieczne jest wykorzystanie wszystkich dostępnych wartości atrybutu. Modę i medianę określa jedynie struktura rozkładu. Dlatego nazywane są średnimi strukturalnymi, pozycyjnymi. Mediana i moda są często używane jako średnia charakterystyka w tych populacjach, w których obliczenie średniej wykładniczej jest niemożliwe lub niepraktyczne. Najpopularniejszym typem średniej jest średnia arytmetyczna. Średnia arytmetyczna to wartość atrybutu, jaką miałaby każda jednostka populacji, gdyby suma wszystkich wartości atrybutu była równomiernie rozłożona na wszystkie jednostki populacji. W ogólnym przypadku jego obliczenie sprowadza się do zsumowania wszystkich wartości atrybutu zmiennej i podzielenia otrzymanej sumy przez całkowitą liczbę jednostek w populacji. Na przykład pięciu pracowników zrealizowało zamówienie na produkcję części, podczas gdy pierwszy wyprodukował 5 części, drugi 7, trzeci 4, czwarty 10, piąty 12. Ponieważ w danych początkowych wartość każdego opcja wystąpiła tylko raz, aby określić średnią wydajność jednego pracownika, należy zastosować prosty wzór na średnią arytmetyczną:  czyli w naszym przykładzie średnia produkcja jednego pracownika  Wraz z prostą średnią arytmetyczną badana jest średnia ważona. Na przykład obliczmy średni wiek uczniów w grupie 20 uczniów w wieku od 18 do 22 lat, gdzie xi - warianty uśrednionej cechy, f - częstość, która pokazuje ile razy w populacji występuje i-ta wartość. Stosując wzór na średnią ważoną otrzymujemy: 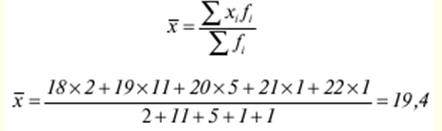 Istnieje pewna zasada wyboru średniej ważonej arytmetycznej: jeśli istnieje szereg danych dotyczących dwóch powiązanych ze sobą wskaźników, dla jednego z nich konieczne jest obliczenie wartości średniej, a jednocześnie wartości liczbowych mianownika jego logicznej formuły są znane, a wartości licznika nie są znane, ale można je znaleźć jako iloczyn tych wskaźników, wówczas średnią wartość należy obliczyć zgodnie ze wzorem arytmetycznej średniej ważonej. W niektórych przypadkach charakter początkowych danych statystycznych jest taki, że obliczenie średniej arytmetycznej traci sens, a jedynym wskaźnikiem uogólniającym może być tylko inny rodzaj średniej - średnia harmoniczna. Obecnie właściwości obliczeniowe średniej arytmetycznej straciły na znaczeniu w obliczaniu uogólniających wskaźników statystycznych z powodu powszechnego wprowadzania komputerów elektronicznych. Średnia wartość harmoniczna, która jest również prosta i ważona, nabrała wielkiego znaczenia praktycznego. Jeżeli znane są wartości liczbowe licznika wzoru logicznego, ale wartości mianownika nie są znane, wówczas wartość średnią oblicza się za pomocą ważonej formuły średniej harmonicznej. Jeżeli, używając średniej wagi harmonicznej wszystkich opcji (f;) są równe, to zamiast ważonej można użyć prostej (nieważonej) średniej harmonicznej:  gdzie x - indywidualne opcje; n to liczba wariantów uśrednionej cechy. Na przykład, prosta średnia harmoniczna może być zastosowana do prędkości, jeśli odcinki drogi przebytej z różnymi prędkościami są równe. Każda wartość średnia powinna być obliczona tak, aby po zastąpieniu każdego wariantu uśrednionej cechy wartość jakiegoś ostatecznego, uogólniającego wskaźnika, który jest powiązany ze wskaźnikiem uśrednionym, nie uległa zmianie. Tak więc przy zastępowaniu rzeczywistych prędkości na poszczególnych odcinkach ścieżki ich wartością średnią (średnią prędkością) nie powinna zmieniać całkowitej odległości. Średnia formuła jest zdeterminowana charakterem (mechanizmem) relacji tego końcowego wskaźnika ze średnią. Dlatego ostateczny wskaźnik, którego wartość nie powinna się zmieniać, gdy opcje zostaną zastąpione ich wartością średnią, nazywa się wskaźnikiem definiującym. Aby wyprowadzić średnią formułę, musisz skomponować i rozwiązać równanie, korzystając z relacji uśrednionego wskaźnika z wyznaczającym. Równanie to jest konstruowane przez zastąpienie wariantów uśrednionej cechy (wskaźnika) ich wartością średnią. Oprócz średniej arytmetycznej i średniej harmonicznej w statystyce stosuje się również inne typy (postacie) średniej. Wszystkie są szczególnymi przypadkami średniej mocy. Jeśli dla tych samych danych obliczysz wszystkie rodzaje średnich potęgowych, to ich wartości będą takie same, tutaj obowiązuje zasada dominacji średnich. Wraz ze wzrostem wykładnika średniej rośnie sama średnia. Średnia geometryczna jest stosowana, gdy występuje n czynników wzrostu, natomiast poszczególne wartości atrybutu są z reguły względnymi wartościami dynamiki, zbudowanymi w postaci wartości łańcuchowych, jako stosunek do poprzedniego poziomu każdego poziomu w serii dynamiki. Średnia charakteryzuje więc średnie tempo wzrostu. Średnia geometryczna prosta jest obliczana według wzoru:  Wzór na geometryczną średnią ważoną jest następujący:  Powyższe wzory są identyczne, ale jedna jest stosowana przy bieżących współczynnikach lub wskaźnikach wzrostu, a druga - przy bezwzględnych wartościach poziomów szeregu. Pierwiastek średniej kwadratowej jest używany przy obliczaniu z wartościami funkcji kwadratowych, służy do pomiaru stopnia fluktuacji poszczególnych wartości cechy wokół średniej arytmetycznej w szeregu rozkładu i jest obliczany według wzoru: 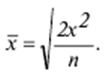 Ważoną średnią kwadratową oblicza się przy użyciu innego wzoru:  Średnia sześcienna jest używana przy obliczaniu z wartościami funkcji sześciennych i jest obliczana według wzoru:  oraz średnia ważona sześcienna: 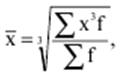 Wszystkie powyższe średnie wartości można przedstawić jako ogólną formułę: 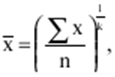 gdzie x jest wartością średnią; x - wartość indywidualna; n to liczba jednostek badanej populacji; k - wykładnik określający rodzaj średniej. Przy użyciu tych samych danych początkowych im więcej k w ogólnym wzorze średniej mocy, tym większa wartość średnia. Wynika z tego, że istnieje regularna zależność między wartościami mocy oznacza:  Opisane powyżej średnie wartości dają ogólne wyobrażenie o badanej populacji iz tego punktu widzenia ich znaczenie teoretyczne, stosowane i poznawcze jest niepodważalne. Ale zdarza się, że wartość średniej nie pokrywa się z żadną z naprawdę istniejących opcji. Dlatego oprócz rozważanych średnich, w analizie statystycznej wskazane jest wykorzystywanie wartości poszczególnych opcji, które zajmują dobrze określoną pozycję w uporządkowanym (uszeregowanym) szeregu charakterystycznych wartości. Wśród takich wielkości najczęściej spotykane są średnie strukturalne (lub opisowe) - tryb (Mo) i mediana (Me). Moda - wartość cechy najczęściej spotykanej w tej populacji. W stosunku do szeregu wariacyjnego modą jest najczęściej występująca wartość szeregu rankingowego, czyli wariant o największej częstości. Moda może posłużyć do określenia najczęściej odwiedzanych sklepów, najczęstszej ceny dla dowolnego produktu. Pokazuje wielkość cechy charakterystyczną dla znacznej części populacji i określa ją wzór: 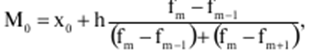 gdzie x0 - dolna granica interwału; h jest wartością przedziału; fm- częstotliwość interwału; fm1- częstotliwość poprzedniego interwału; fm+1- częstotliwość następnego interwału. mediana nazywa się wariant znajdujący się na środku rzędu rankingowego. Mediana dzieli szereg na dwie równe części w taki sposób, że po obu jego stronach znajduje się taka sama liczba jednostek populacji. Jednocześnie w jednej połowie jednostek populacji wartość atrybutu zmiennej jest mniejsza od mediany, w drugiej połowie jest od niej większa. Mediana jest używana podczas badania elementu, którego wartość jest większa lub równa lub jednocześnie mniejsza lub równa połowie elementów szeregu dystrybucyjnego. Mediana daje ogólne wyobrażenie o tym, gdzie koncentrują się wartości cechy, innymi słowy, gdzie jest ich centrum. Opisowy charakter mediany przejawia się w tym, że charakteryzuje ona ilościową granicę wartości zmiennego atrybutu, które posiada połowa jednostek populacji. Problem znalezienia mediany dla dyskretnego szeregu wariacyjnego jest rozwiązany w prosty sposób. Jeżeli wszystkie jednostki serii mają numery seryjne, to numer seryjny wariantu mediany definiuje się jako (n + 1) / 2 z nieparzystą liczbą członków n. Jeżeli liczba członków serii jest parzysta, wtedy mediana będzie średnią z dwóch wariantów o numerach seryjnych n / 2 i n/2 + 1. Przy wyznaczaniu mediany w szeregach zmienności przedziałowych najpierw określa się przedział, w którym się ona znajduje (przedział mediany). Przedział ten charakteryzuje się tym, że jego skumulowana suma częstości jest równa lub przekracza połowę sumy wszystkich częstości szeregu. Obliczenie mediany szeregu zmienności przedziałowej odbywa się według wzoru:  gdzie x0 - dolna granica interwału; h jest wartością przedziału; fm- częstotliwość interwału; f to liczba członków serii; ∫ m -1 - suma skumulowanych członków szeregu poprzedzającego ten. Wraz z medianą dla pełniejszego scharakteryzowania struktury badanej populacji wykorzystuje się inne wartości opcji, które zajmują dość określoną pozycję w szeregach rankingowych. Należą do nich kwartyle i decyle. Kwartyle dzielą szereg przez sumę częstotliwości na cztery równe części, a decyle na dziesięć równych części. Istnieją trzy kwartyle i dziewięć decyli. Mediana i moda, w przeciwieństwie do średniej arytmetycznej, nie wygaszają różnic indywidualnych w wartościach atrybutu zmiennej, a zatem są dodatkowymi i bardzo ważnymi cechami populacji statystycznej. W praktyce często stosuje się je zamiast średniej lub razem z nią. Szczególnie celowe jest obliczenie mediany i mody w tych przypadkach, gdy badana populacja zawiera pewną liczbę jednostek o bardzo dużej lub bardzo małej wartości atrybutu zmiennej. Te wartości opcji, które są mało charakterystyczne dla populacji, wpływając jednocześnie na średnią arytmetyczną, nie wpływają na wartości mediany i mody, co czyni te ostatnie bardzo cennymi wskaźnikami do analizy ekonomicznej i statystycznej. 3. Wskaźniki zmienności Celem badania statystycznego jest identyfikacja głównych właściwości i wzorców badanej populacji statystycznej. W procesie sumarycznego przetwarzania statystycznych danych obserwacyjnych budowane są szeregi dystrybucyjne. Istnieją dwa rodzaje szeregów dystrybucyjnych – atrybutywny i wariacyjny – w zależności od tego, czy atrybut przyjęty za podstawę grupowania jest jakościowy czy ilościowy. Szeregi wariacyjne nazywane są szeregami dystrybucyjnymi zbudowanymi na podstawie ilościowej. Wartości cech ilościowych w poszczególnych jednostkach populacji nie są stałe, mniej więcej różnią się od siebie. Ta różnica w wielkości cechy nazywana jest zmiennością. Oddzielne wartości liczbowe cechy występujące w badanej populacji nazywane są wariantami wartości. Obecność zmienności w poszczególnych jednostkach populacji wynika z wpływu dużej liczby czynników na kształtowanie się poziomu cechy. Badanie charakteru i stopnia zmienności znaków w poszczególnych jednostkach populacji jest najważniejszym zagadnieniem każdego opracowania statystycznego. Wskaźniki zmienności służą do opisu miary zmienności cech. Kolejnym ważnym zadaniem badań statystycznych jest określenie roli poszczególnych czynników lub ich grup w zmienności niektórych cech populacji. Do rozwiązania takiego problemu w statystyce stosuje się specjalne metody badania zmienności, oparte na wykorzystaniu systemu wskaźników mierzących zmienność. W praktyce badacz ma do czynienia z wystarczająco dużą liczbą opcji wartości atrybutu, co nie daje wyobrażenia o rozkładzie jednostek według wartości atrybutu w agregacie. W tym celu wszystkie warianty wartości atrybutów są ułożone w porządku rosnącym lub malejącym. Proces ten nazywa się rankingiem serii. Szereg rankingowy od razu daje ogólne pojęcie o wartościach, jakie cecha przyjmuje w agregacie. Niewystarczalność wartości średniej do wyczerpującej charakterystyki populacji powoduje konieczność uzupełnienia wartości średnich o wskaźniki pozwalające ocenić typowość tych średnich poprzez pomiar fluktuacji (zmienności) badanej cechy. Zastosowanie tych wskaźników zmienności pozwala na pełniejszą i bardziej znaczącą analizę statystyczną, a tym samym na lepsze zrozumienie istoty badanych zjawisk społecznych. Najprostsze znaki zmienności to minimum i maksimum - jest to najmniejsza i największa wartość cechy w agregacie. Liczbę powtórzeń poszczególnych wariantów wartości cech nazywamy częstotliwością powtórzeń. Częstotliwość - względny wskaźnik częstości, który może być wyrażony w ułamkach jednostki lub w procentach, pozwala porównać serie zmienności o różnej liczbie obserwacji. Formalnie mamy: 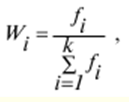 gdzie fi - ilość opcji. Aby zmierzyć zmienność cechy, stosuje się różne wskaźniki bezwzględne i względne. Bezwzględne wskaźniki zmienności obejmują średnie odchylenie liniowe, zakres zmienności, wariancję, odchylenie standardowe. Zakres zmienności (R) to różnica pomiędzy maksymalnymi i minimalnymi wartościami cechy w badanej populacji, formalnie mamy: R=Xmax-Xmin Wskaźnik ten daje tylko najbardziej ogólne pojęcie o zmienności badanej cechy, ponieważ pokazuje różnicę tylko między wartościami granicznymi wariantów. Jest całkowicie niezwiązany z licznościami w szeregu wariacyjnym, czyli z charakterem rozkładu, a jego uzależnienie tylko od skrajnych wartości atrybutu może nadać mu niestabilny, losowy charakter. Zakres zmienności nie dostarcza informacji o cechach badanych populacji i nie pozwala na ocenę stopnia typowości uzyskanych średnich. Zakres tego wskaźnika ogranicza się do dość jednorodnych populacji. Dokładniej, wskaźnik charakteryzuje zmienność cechy, w oparciu o uwzględnienie zmienności wszystkich wartości cechy. Aby scharakteryzować zmienność cechy, należy uogólnić odchylenia wszystkich tych wartości od jakiejś typowej wartości dla badanej populacji. Wskaźniki zmienności takie jak średnie odchylenie liniowe, wariancja i odchylenie standardowe opierają się na uwzględnieniu odchyleń wartości atrybutu poszczególnych jednostek populacji od średniej arytmetycznej. Średnie odchylenie liniowe jest średnią arytmetyczną wartości bezwzględnych odchyleń poszczególnych opcji od ich średniej arytmetycznej:  gdzie d jest średnim odchyleniem liniowym; |x−x| - wartość bezwzględna (moduł) odchylenia wariantu od średniej arytmetycznej; f - częstotliwość. Pierwsza formuła jest stosowana, gdy każda z opcji występuje w agregacie tylko raz, a druga – szeregowo z nierównymi częstotliwościami. Istnieje inny sposób uśrednienia odchyleń opcji od średniej arytmetycznej. Ta bardzo powszechna w statystyce metoda sprowadza się do obliczenia kwadratów odchyleń opcji od średniej, a następnie ich uśrednienia. W tym przypadku otrzymujemy nowy wskaźnik zmienności - wariancję. wariancja (σ2) - średnia z kwadratów odchyleń wariantów wartości cech od ich średniej wartości: 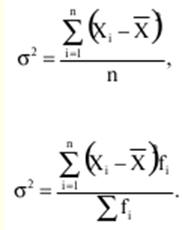 Drugi wzór jest stosowany, jeśli warianty mają własne wagi (lub częstotliwości serii wariantów). W analizie ekonomicznej i statystycznej zwyczajowo ocenia się zmienność atrybutu najczęściej przy użyciu odchylenia standardowego. Odchylenie standardowe (σ) jest pierwiastkiem kwadratowym z wariancji:  Średnie odchylenia liniowe i średnie odchylenia kwadratowe pokazują, jak bardzo wartość atrybutu zmienia się średnio dla jednostek badanej populacji i są wyrażone w tych samych jednostkach, co warianty. W praktyce statystycznej często konieczne staje się porównywanie zmienności różnych cech. Na przykład bardzo interesujące jest porównanie zmienności wieku personelu i jego kwalifikacji, stażu pracy i wynagrodzeń itp. Dla takich porównań wskaźniki bezwzględnej zmienności cech (średnia liniowa i odchylenie standardowe) oczywiście, są nieodpowiednie. W rzeczywistości niemożliwe jest porównanie fluktuacji doświadczenia zawodowego wyrażonego w latach z wahaniami płac wyrażonymi w rublach i kopiejkach. Porównując zmienność różnych cech w agregacie, wygodnie jest stosować względne wskaźniki zmienności. Wskaźniki te są obliczane jako stosunek wskaźników bezwzględnych do średniej arytmetycznej (lub mediany). Wykorzystując zakres zmienności, średnie odchylenie liniowe, odchylenie standardowe jako bezwzględny wskaźnik zmienności, otrzymuje się względne wskaźniki fluktuacji:  Współczynnik zmienności jest najczęściej stosowanym wskaźnikiem zmienności względnej, charakteryzującym jednorodność populacji. Zbiór uważa się za jednorodny, jeśli współczynnik zmienności nie przekracza 33% dla rozkładów zbliżonych do normalnego. WYKŁAD №6. Selektywna obserwacja 1. Ogólna koncepcja obserwacji selektywnej Obserwację statystyczną można zorganizować jako ciągłą i nieciągłą. Ciągły polega na badaniu wszystkich jednostek badanej populacji zjawiska, nieciągły - tylko jego części. Do nieciągłości należy również obserwacja selektywna. Obserwacja selektywna jest jednym z najczęściej stosowanych rodzajów obserwacji nieciągłej. Obserwacja ta opiera się na założeniu, że niektóre wybrane w przypadkowej kolejności jednostki mogą reprezentować cały badany zbiór zjawiska zgodnie z interesującymi badacza charakterystykami. Celem obserwacji próby jest uzyskanie informacji przede wszystkim w celu określenia sumarycznej charakterystyki uogólniającej całej badanej populacji. Pod względem celu obserwacja selektywna pokrywa się z jednym z zadań obserwacji ciągłej, dlatego może pojawić się pytanie, który z dwóch rodzajów obserwacji - ciągły czy selektywny - jest bardziej celowy do przeprowadzenia. Rozwiązując ten problem, należy wyjść z następujących podstawowych wymagań dotyczących obserwacji statystycznej: 1) informacja musi być wiarygodna, tj. jak najbardziej odpowiadać rzeczywistości; 2) informacje muszą być wystarczająco kompletne, aby rozwiązać problem badawczy; 3) wybór informacji powinien być dokonany jak najszybciej, aby zapewnić ich wykorzystanie do celów operacyjnych; 4) koszty pieniężne i robocizny związane z organizacją i prowadzeniem powinny być minimalne. Przy obserwacji selektywnej wymagania te są spełnione w większym stopniu niż przy obserwacji ciągłej. Zalety obserwacji wybiórczej w porównaniu z obserwacją ciągłą można w pełni docenić, jeśli jest ona zorganizowana i prowadzona w ścisłej zgodności z naukowymi zasadami teorii metody próbkowania. Taką zasadą jest zapewnienie losowości doboru jednostek i ich dostatecznej liczby. Zgodność z zasadą umożliwia uzyskanie takiego zbioru jednostek, który według interesujących badacza cech reprezentuje cały badany zbiór, czyli jest reprezentatywny (reprezentatywny). Podczas prowadzenia obserwacji selektywnej nie bada się wszystkich jednostek badanego obiektu, to znaczy nie wszystkich jednostek populacji ogólnej, ale tylko jej część, specjalnie wyselekcjonowaną. Pierwsza zasada doboru – zapewniająca losowość – polega na tym, że przy wyborze każdej z jednostek badanej populacji zapewnione są równe szanse dostania się do próby. Losowy wybór nie jest przypadkowym wyborem. Losowy wybór można zapewnić jedynie poprzez przestrzeganie określonej metodologii (na przykład poprzez losowanie, wykorzystanie tabel liczb losowych itp.). Druga zasada doboru – zapewnienie odpowiedniej liczby wyselekcjonowanych jednostek – jest ściśle związana z pojęciem reprezentatywności próby. Pojęcie reprezentatywności wybranego zbioru jednostek nie powinno być rozumiane jako jego reprezentatywność pod każdym względem, tj. pod każdym względem badanej populacji. Takie przedstawienie jest prawie niemożliwe. Każda obserwacja na próbie prowadzona jest w konkretnym celu i jasno sformułowanych konkretnych zadaniach, a pojęcie reprezentatywności powinno być powiązane z celem i celami badania. Część wybrana z całej badanej populacji powinna być reprezentatywna przede wszystkim w stosunku do tych cech, które są badane lub mają istotny wpływ na kształtowanie sumarycznych cech generalizujących. Przedstawmy kilka pojęć używanych w obserwacji selektywnej. Ogólna populacja nazywa się cały badany zbiór jednostek, który podlega badaniu zgodnie z interesującymi badacza cechami. zestaw do pobierania próbek jakaś jej część wybierana losowo z ogólnej populacji to tzw. Próba ta podlega wymogowi reprezentatywności, co oznacza możliwość, poprzez badanie tylko części populacji ogólnej, rozszerzenia wyników na całą populację. Cechami populacji ogólnej i próbnej mogą być wartości średnie badanych cech, ich wariancje i odchylenia standardowe, moda i mediana itp. Badaczy może również zainteresować rozkład jednostek według badanych cech w populacji ogólnej i próbnej. W tym przypadku częstotliwości nazywane są odpowiednio częstotliwościami ogólnymi i częstotliwościami próbkowania. Treścią metody doboru próby jest system zasad doboru i sposobów charakteryzowania jednostek badanej populacji. Istotą metody doboru próby jest pozyskiwanie danych pierwotnych poprzez obserwację próby, a następnie uogólnianie, analizę i dystrybucję na całą populację w celu uzyskania wiarygodnych informacji o badanym zjawisku. Reprezentatywność próby zapewnia przestrzeganie zasady losowego doboru obiektów w populacji w próbie. Jeżeli populacja jest jakościowo jednorodna, to zasada losowości jest realizowana przez prosty losowy dobór obiektów próby. Prosty dobór losowy to taka procedura doboru próby, która zapewnia takie samo prawdopodobieństwo dla każdej jednostki populacji, która ma zostać wybrana do obserwacji, dla dowolnej próby o danej wielkości. Zatem celem metody doboru próby jest wyciągnięcie wniosku o wartości cech populacji ogólnej na podstawie informacji z próby losowej z tej populacji. 2. Błędy próbkowania Pomiędzy cechami populacji próbnej a cechami populacji ogólnej z reguły występuje pewna rozbieżność, którą nazywamy błędem obserwacji statystycznej. Podczas masowej obserwacji błędy są nieuniknione, ale powstają z różnych przyczyn. Wartość ewentualnego błędu przykładowego atrybutu składa się z błędów rejestracji i błędów reprezentatywności. Błędy rejestracyjne, czyli błędy techniczne, wiążą się z niewystarczającymi kwalifikacjami obserwatorów, niedokładnymi obliczeniami, niedoskonałością przyrządów itp. pod błąd reprezentatywności (reprezentacji) zrozumieć rozbieżność między charakterystyką próbki a szacowaną charakterystyką populacji ogólnej. Błędy reprezentatywności mogą być losowe lub systematyczne. Błędy systematyczne wiążą się z naruszeniem ustalonych zasad selekcji. Błędy losowe tłumaczy się niewystarczająco jednolitą reprezentacją w próbie różnych kategorii jednostek populacji ogólnej. W wyniku pierwszego powodu próba może łatwo okazać się stronnicza, ponieważ przy wyborze każdej jednostki popełniany jest błąd, zawsze skierowany w tym samym kierunku. Ten błąd nazywa się błędem przesunięcia. Jego wielkość może przekroczyć wartość błędu losowego. Cechą błędu obciążenia jest to, że będąc stałą częścią błędu reprezentatywności, rośnie wraz z wielkością próby. Błąd losowy zmniejsza się wraz ze wzrostem wielkości próbki. Ponadto można określić wielkość błędu losowego, podczas gdy wielkość błędu obciążenia jest bardzo trudna, a czasami niemożliwa do bezpośredniego określenia w praktyce. Dlatego ważne jest poznanie przyczyn błędu przesunięcia i zapewnienie środków do jego wyeliminowania. Błędy stronniczości są zamierzone lub niezamierzone. Powodem zamierzonego błędu jest tendencyjne podejście do doboru jednostek z populacji ogólnej. Aby zapobiec wystąpieniu takiego błędu, należy przestrzegać zasady losowego doboru jednostek. Niezamierzone błędy mogą wystąpić na etapie przygotowania obserwacji próbki, tworzenia populacji próby i analizy jej danych. Aby uniknąć takich błędów, potrzebny jest dobry operat losowania, czyli populacja, z której ma być wykonana próba, np. lista jednostek losowania. Operat losowania musi być rzetelny, kompletny i spójny z celem badania, a jednostki losowania i ich cechy muszą odpowiadać ich rzeczywistemu stanowi w momencie przygotowywania losowania. Nierzadko zdarza się, że niektóre jednostki w próbie mają trudności z zebraniem informacji ze względu na ich brak w czasie obserwacji, niechęć do udzielania informacji itp. W takich przypadkach jednostki te muszą być zastąpione innymi. Konieczne jest zapewnienie wymiany przez jednostki równoważne. Błąd losowego doboru próby występuje w wyniku losowych różnic między jednostkami w próbie a jednostkami populacji ogólnej, czyli jest związany z doborem losowym. Teoretycznym uzasadnieniem pojawienia się losowych błędów doboru próby jest teoria prawdopodobieństwa i jej twierdzenia graniczne. Istota twierdzeń granicznych polega na tym, że w zjawiskach masowych skumulowany wpływ różnych przyczyn losowych na kształtowanie się prawidłowości i uogólniających charakterystyk będzie arbitralnie mały lub praktycznie nie zależy od przypadku. Ponieważ losowy błąd doboru występuje w wyniku losowych różnic między jednostkami próby a populacją ogólną, to przy odpowiednio dużej liczebności próby będzie on arbitralnie mały. Twierdzenia graniczne teorii prawdopodobieństwa pozwalają określić wielkość błędów losowych próbkowania. Rozróżnij średnie (standardowe) i marginalne błędy próbkowania. Pod średni (standardowy) błąd próbkowanie odnosi się do rozbieżności między średnią próbki a średnią populacji. błąd krańcowy Zwyczajowo przyjmuje się maksymalną możliwą rozbieżność, tj. maksymalny błąd dla danego prawdopodobieństwa jej wystąpienia, jako próbkę. W matematycznej teorii metody doboru próby porównuje się średnie cechy cech próby i populacji ogólnej i dowodzi się, że wraz ze wzrostem liczebności próby prawdopodobieństwo dużych błędów i granice maksymalnego możliwego błędu zmniejszać. Im więcej jednostek zostanie przebadanych, tym mniejsze będą rozbieżności między próbą a charakterystyką ogólną. Na podstawie twierdzenia udowodnionego przez P. L. Czebyszewa wartość błędu standardowego prostej próby losowej o wystarczająco dużej liczebności próby (n) można wyznaczyć ze wzoru: 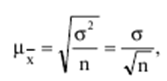 gdzie µx- Standardowy błąd. Z tego wzoru na średni (standardowy) błąd prostej próbki losowej wynika, że wartość µx zależy od zmienności cechy w populacji ogólnej (im większa zmienność cechy, tym większy błąd próby) oraz od liczebności próby n, im więcej jednostek jest badanych, tym mniejsza rozbieżność między próbą a cechami ogólnymi) . Akademik A. M. Lyapunov udowodnił, że prawdopodobieństwo wystąpienia losowego błędu próbkowania przy wystarczająco dużej jego wielkości jest zgodne z prawem rozkładu normalnego. Prawdopodobieństwo to określa wzór:  W statystyce matematycznej stosuje się współczynnik ufności t, a wartości funkcji F(t) są stabelaryzowane dla różnych jej wartości, uzyskując odpowiednie poziomy ufności. Współczynnik ufności pozwala obliczyć marginalny błąd próbkowania, obliczony według wzoru: 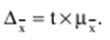 Ze wzoru wynika, że krańcowy błąd próbkowania jest równy - razy liczba przeciętnych błędów próbkowania. Zatem wartość marginalnego błędu próbkowania można ustalić z pewnym prawdopodobieństwem. Obserwacja próbki umożliwia wyznaczenie średniej arytmetycznej próbki x i błąd krańcowy tej średniej ∆x, który pokazuje z pewnym prawdopodobieństwem), jak bardzo próbka może się różnić od ogólnej średniej w górę lub w dół. Wtedy wartość średniej ogólnej będzie reprezentowana przez oszacowanie przedziałowe, dla którego dolna granica będzie równa  Przedział, w którym nieznana wartość szacowanego parametru zostanie ujęta z określonym stopniem prawdopodobieństwa, nazywamy przedziałem ufności, a prawdopodobieństwo P nazywamy prawdopodobieństwem ufności. Najczęściej przyjmuje się, że prawdopodobieństwo ufności wynosi 0,95 lub 0,99, a następnie współczynnik ufności t wynosi odpowiednio 1,96 i 2,58. Oznacza to, że przedział ufności zawiera ogólną średnią z danym prawdopodobieństwem. Wraz z wartością bezwzględną marginalnego błędu próby obliczany jest również względny błąd próby, który jest definiowany jako procent krańcowego błędu próby do odpowiedniej cechy populacji próby: 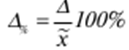 Im większa wartość marginalnego błędu próbkowania, tym większa wartość przedziału ufności, a co za tym idzie, mniejsza dokładność oszacowania. Średni (standardowy) błąd próby zależy od wielkości próby i stopnia zmienności cechy w populacji ogólnej. 3. Określenie wymaganej wielkości próby Jedną z naukowych zasad teorii pobierania próbek jest zapewnienie, że wybrana zostanie wystarczająca liczba jednostek. Teoretycznie konieczność przestrzegania tej zasady jest przedstawiona w dowodach twierdzeń granicznych rachunku prawdopodobieństwa, które pozwalają ustalić, ile jednostek należy wybrać z populacji ogólnej, aby było to wystarczające i zapewniało reprezentatywność próby. Spadek błędu standardowego próby (a tym samym wzrost dokładności oszacowania) zawsze wiąże się ze wzrostem liczebności próby. Dlatego już na etapie organizowania obserwacji próbnej należy zdecydować, jaka powinna być wielkość próby, aby zapewnić wymaganą dokładność wyników obserwacji. Obliczenie wymaganej wielkości próby jest budowane przy użyciu formuł wywodzących się ze wzorów na marginalne błędy próby (∆) odpowiadające temu lub innemu rodzajowi i metodzie doboru. Tak więc dla losowo powtarzanej próby (n) mamy: 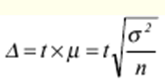  Znaczenie tego wzoru jest takie, że w przypadku losowego ponownego wyboru wymaganej liczby wielkość próby jest wprost proporcjonalna do kwadratu współczynnika ufności (t2) i wariancji cechy zmienności (σ2) i jest odwrotnie proporcjonalna do kwadratu marginalnego błędu próbkowania (∆2). W szczególności przy 2-krotnym wzroście błędu krańcowego wymagana liczebność próby może zostać zmniejszona czterokrotnie. Spośród trzech parametrów dwa (t i ∆) są ustalane przez badacza. Jednocześnie badacz, opierając się na celu i zadaniach badania reprezentacyjnego, musi zdecydować, w jakiej kombinacji ilościowej lepiej uwzględnić te parametry, aby zapewnić najlepszą opcję. W jednym przypadku może być bardziej zadowolony z wiarygodności uzyskanych wyników (t) niż z miary dokładności (∆), w drugim odwrotnie. Trudniej jest rozstrzygnąć kwestię wielkości krańcowego błędu próbkowania, gdyż badacz nie dysponuje tym wskaźnikiem na etapie projektowania obserwacji próbnej. Dlatego w praktyce przyjęło się ustalać wartość krańcowego błędu próbkowania z reguły w przedziale do 4% oczekiwanego średniego poziomu cechy. Do ustalenia zakładanego średniego poziomu można podejść na różne sposoby: wykorzystując dane z podobnych wcześniejszych badań lub wykorzystując dane z operatu losowania i pobierając małą próbę pilotażową. Kwestia określenia wymaganej liczebności próby komplikuje się, jeśli badanie reprezentacyjne obejmuje badanie kilku cech jednostek próby. W tym przypadku średnie poziomy każdej z cech i ich zmienność z reguły są różne, a zatem można zdecydować, które rozproszenie której z cech daje pierwszeństwo, biorąc pod uwagę jedynie cel i cele Badanie. Projektując obserwację próbną, przyjmuje się z góry określoną wartość dopuszczalnego błędu próbkowania zgodnie z celami danego badania i prawdopodobieństwem wniosków na podstawie wyników obserwacji. Ogólnie rzecz biorąc, wzór na błąd krańcowy średniej z próby pozwala rozwiązać następujące problemy: 1) określić wielkość możliwych odchyleń wskaźników populacji ogólnej od wskaźników populacji próbnej; 2) określić wymaganą wielkość próby, zapewniając wymaganą dokładność, w której granice ewentualnego błędu nie przekroczą określonej, z góry określonej wartości; 3) określić prawdopodobieństwo, że błąd w próbie będzie miał określoną granicę. 4. Metody doboru i rodzaje pobierania próbek W teorii metody doboru próby opracowano różne metody doboru i rodzaje doboru próby, aby zapewnić reprezentatywność. Pod metoda wyboru zrozumieć procedurę wyboru jednostek z populacji ogólnej. Istnieją dwie metody selekcji: powtarzana i nie powtarzana. W ponownej selekcji każda wylosowana jednostka po jej zbadaniu wraca do populacji ogólnej i przy kolejnej selekcji może ponownie znaleźć się w próbie. Ta metoda selekcji jest budowana zgodnie ze schematem „zwróconej piłki”. Przy tej metodzie doboru prawdopodobieństwo dostania się do próby dla każdej jednostki populacji ogólnej nie zmienia się niezależnie od liczby wybranych jednostek. Przy selekcji nie powtarzalnej, każda wybrana losowo jednostka, po jej zbadaniu, nie jest zwracana do populacji ogólnej. Ta metoda selekcji jest zbudowana zgodnie ze schematem „niezwróconej piłki”. Prawdopodobieństwo wybrania dla każdej jednostki populacji wzrasta wraz z dokonywaniem selekcji. W zależności od metodyki losowania wyróżnia się następujące główne typy doboru: faktycznie losowe, mechaniczne, typowe (uwarstwione, zregionalizowane), seryjne (zagnieżdżone), kombinowane, wieloetapowe, wielofazowe, przenikające. Rzeczywista próba losowa jest tworzona w ścisłej zgodności z naukowymi zasadami i regułami losowej selekcji. W celu uzyskania właściwej próby losowej populacja jest ściśle dzielona na jednostki losowania, a następnie wybierana jest wystarczająca liczba jednostek w kolejności losowej powtarzalnej lub niepowtarzającej się. Kolejność losowa to kolejność równoważna losowaniu. W praktyce najlepiej tę kolejność zapewnić stosując specjalne tablice liczb losowych. Jeśli na przykład należy wybrać 1587 jednostek z populacji zawierającej 40 jednostek, to z tabeli wybiera się 40 czterocyfrowych liczb mniejszych niż 1587. Przy nie powtarzalnej metodzie selekcji obliczenie błędu standardowego odbywa się za pomocą wzoru: 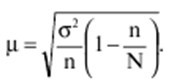
Ponieważ proporcja ta jest zawsze mniejsza niż jeden, błąd w doborze nie powtarzalnym, przy innych czynnikach równych, jest zawsze mniejszy niż w doborze powtarzanym. Selekcja niepowtarzalna jest praktycznie zawsze łatwiejsza do zorganizowania niż selekcja wielokrotna i jest stosowana częściej. Utworzenie próby w ścisłej zgodności z zasadami doboru losowego jest praktycznie bardzo trudne, a czasem niemożliwe, ponieważ przy użyciu tablic liczb losowych konieczne jest ponumerowanie wszystkich jednostek populacji ogólnej. Dość często populacja jest tak liczna, że przeprowadzenie takich wstępnych prac jest niezwykle trudne i niepraktyczne. Dlatego w praktyce stosuje się inne rodzaje próbek, z których każda nie jest ściśle losowa. Są one jednak zorganizowane w taki sposób, aby zapewnić maksymalne zbliżenie do warunków losowego doboru. W przypadku próby czysto mechanicznej cała populacja jednostek musi być przede wszystkim przedstawiona w formie listy jednostek selekcji, zestawionej w jakiejś neutralnej kolejności względem badanej cechy, na przykład alfabetycznie. Następnie listę jednostek losowania dzieli się na tyle równych części, ile jest konieczne do wybrania jednostek. Ponadto, zgodnie z ustaloną z góry regułą, niezwiązaną ze zmiennością badanej cechy, z każdej części listy wybiera się jedną jednostkę. Ten rodzaj doboru próby nie zawsze zapewnia dobór losowy, a wynikowa próba może być stronnicza. Tłumaczy się to tym, że, po pierwsze, uporządkowanie jednostek populacji ogólnej może mieć element nielosowy. Po drugie, pobieranie próbek z każdej części populacji, jeśli pochodzenie jest nieprawidłowo ustalone, może również prowadzić do błędu błędu systematycznego. Praktycznie jednak łatwiej jest zorganizować próbę mechaniczną niż właściwą losową, a ten rodzaj doboru jest najczęściej stosowany w badaniach reprezentacyjnych. Typowe (strefowe, warstwowe) próbkowanie ma dwa cele: 1) zapewnić reprezentację w próbie odpowiednich grup typowych populacji ogólnej zgodnie z interesującymi badacza cechami; 2) zwiększyć dokładność wyników badania reprezentacyjnego. Przy typowej próbie, przed rozpoczęciem jej formowania, ogólna populacja jednostek jest dzielona na typowe grupy. W tym przypadku bardzo ważnym punktem jest właściwy wybór atrybutu grupującego. Wybrane grupy typowe mogą zawierać taką samą lub różną liczbę jednostek wyboru. W pierwszym przypadku zbiór jest tworzony z jednakowym udziałem selekcji z każdej grupy, w drugim – z udziałem proporcjonalnym do jego udziału w populacji generalnej. Jeśli próba jest utworzona z równym udziałem selekcji, w istocie jest równoważna pewnej liczbie właściwych próbek losowych z mniejszych populacji, z których każda jest typową grupą. Selekcja z każdej grupy odbywa się w kolejności losowej (powtarzającej się lub nie powtarzającej się) lub mechanicznej. Przy próbie typowej (zarówno o równym, jak i nierównym udziale doboru) możliwe jest wyeliminowanie wpływu zmienności międzygrupowej badanej cechy na trafność jej wyników, gdyż obowiązkowa reprezentacja każdej z typowych grup w populacji próby jest zapewnione. Błąd standardowy próby nie będzie zależał od wartości wariancji całkowitej - σ2, oraz o wartości średniej dyspersji grupowych σi2. Ponieważ średnia wariancji grupowych jest zawsze mniejsza niż całkowita wariancja, to przy innych czynnikach równych, błąd standardowy typowej próbki będzie mniejszy niż błąd standardowy samej próbki losowej. Przy określaniu błędów standardowych typowej próbki stosuje się następujące wzory: 1) metodą selekcji powtórnej: 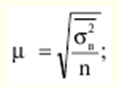 2) z niepowtórzoną metodą selekcji:  gdzie σв2- średnia wariancji grupowych w populacji próby. Próbkowanie seryjne (zagnieżdżone) - jest to rodzaj tworzenia próby, gdy nie badane jednostki, ale grupy jednostek (serie, gniazda) są wybierane losowo. W ramach wybranej serii (gniazd) badane są wszystkie jednostki. Próbkowanie seryjne jest praktycznie łatwiejsze do zorganizowania i przeprowadzenia niż dobór poszczególnych jednostek. Jednak przy tego typu losowaniu po pierwsze nie jest zapewniona reprezentacja każdej z serii, a po drugie nie jest eliminowany wpływ międzyseryjnej zmienności badanej cechy na wyniki ankiety. Gdy ta zmienność jest znacząca, zwiększa błąd reprezentatywności losowej. Przy wyborze rodzaju próbki badacz musi wziąć pod uwagę tę okoliczność. Błąd standardowy próbkowania seryjnego określają wzory: 1) metodą selekcji powtórnej:  gdzie σв2- wariancja międzyseryjna populacji próby; r - numer wybranej serii; 2) z niepowtórzoną metodą selekcji:  gdzie R jest liczbą szeregów w populacji ogólnej. W praktyce stosuje się określone metody i rodzaje doboru próby w zależności od celu i celów badań reprezentacyjnych oraz możliwości ich organizacji i przeprowadzenia. Najczęściej stosuje się kombinację metod pobierania próbek i rodzajów pobierania próbek. Takie próbki nazywane są połączonymi. Możliwe są kombinacje w różnych kombinacjach: próbkowanie mechaniczne i seryjne, próbkowanie typowe i mechaniczne, seryjne i losowe itp. Próbkowanie łączone stosuje się w celu zapewnienia jak największej reprezentatywności przy najniższych kosztach pracy i kosztów pieniężnych związanych z organizacją i przeprowadzeniem badania. W przypadku próbki połączonej wartość błędu standardowego próbki składa się z błędów na każdym z jej etapów i może być określona jako pierwiastek kwadratowy z sumy kwadratów błędów odpowiednich próbek. Tak więc, jeśli zastosowano próbkowanie mechaniczne i typowe w połączeniu z próbkowaniem łączonym, błąd standardowy można określić za pomocą wzoru: 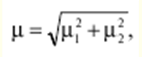 gdzie μ1 i μ2są standardowymi błędami próbek mechanicznych i typowych. Cechą próbki wieloetapowej jest to, że próbka jest tworzona stopniowo, zgodnie z etapami selekcji. W pierwszym etapie jednostki pierwszego etapu są wybierane przy użyciu z góry określonej metody i rodzaju selekcji. W drugim etapie z każdej jednostki pierwszego etapu wchodzącej w skład próby wybierane są jednostki drugiego etapu itd. Liczba etapów może być większa niż dwa. Na ostatnim etapie tworzona jest próbka, której jednostki podlegają badaniu. I tak np. do reprezentacyjnego badania budżetów gospodarstw domowych w pierwszym etapie wybierane są podmioty terytorialne kraju, w drugim powiaty w wybranych regionach, w trzecim etapie wybierane są przedsiębiorstwa lub organizacje w każdej gminie , wreszcie w czwartym etapie w wybranych przedsiębiorstwach dokonuje się selekcji rodzin. W ten sposób zestaw do pobierania próbek jest tworzony na ostatnim etapie. Próbkowanie wieloetapowe jest bardziej elastyczne niż inne typy, chociaż generalnie daje mniej dokładne wyniki niż próbka jednoetapowa o tej samej wielkości. Jednocześnie ma to jednak jedną ważną zaletę polegającą na tym, że operat losowania w doborze wieloetapowym musi być budowany na każdym etapie tylko dla tych jednostek, które są w próbie, a to jest bardzo ważne, ponieważ istnieje często brak gotowego operatu losowania. Błąd standardowy doboru próby w selekcji wielostopniowej z grupami o różnej objętości określa wzór: 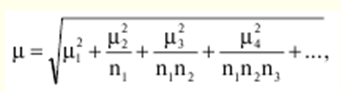 gdzie μ1, M2, M3,… - błędy standardowe na różnych etapach; n1, n2, n3,… - liczba próbek na odpowiednich etapach selekcji. W przypadku, gdy grupy nie są takie same pod względem objętości, teoretycznie ten wzór nie może być stosowany. Ale jeśli całkowita proporcja selekcji na wszystkich etapach jest stała, to w praktyce obliczenia według tego wzoru nie doprowadzą do zniekształcenia błędu. Istota próbki wielofazowej polega na tym, że na podstawie wstępnie uformowanej próbki tworzona jest podpróbka, z tej podpróbki następna podpróbka itd. Próbka początkowa to pierwsza faza, podpróbka z niej druga itd. Próbka wielofazowa przydatna w kilku przypadkach: 1) jeżeli do badania różnych cech wymagana jest nierówna wielkość próby; 2) jeśli fluktuacja badanych cech nie jest taka sama, a wymagana dokładność jest inna; 3) jeżeli w odniesieniu do wszystkich jednostek próby początkowej (pierwszej fazy) konieczne jest zebranie jednej - mniej szczegółowej informacji, aw odniesieniu do jednostek każdej kolejnej fazy - pozostałych - bardziej szczegółowych. Jedną z niewątpliwych zalet pobierania próbek wielofazowych jest fakt, że informacje uzyskane w pierwszej fazie mogą być wykorzystane jako informacja dodatkowa w kolejnych fazach, informacja z drugiej fazy może być wykorzystana jako informacja dodatkowa w kolejnych fazach itp. To wykorzystanie informacji zwiększa dokładność wyników badania reprezentacyjnego. Organizując próbkowanie wielofazowe, można zastosować kombinację różnych metod i rodzajów selekcji (typowe próbkowanie z próbkowaniem mechanicznym itp.). Selekcja wielofazowa może być łączona z wielostopniową. Na każdym etapie pobieranie próbek może być wielofazowe. Błąd standardowy w próbce wielofazowej obliczany jest dla każdej fazy oddzielnie zgodnie ze wzorami metody doboru i rodzaju próbki, z której została utworzona jej próbka. Próbki przenikające się to dwie lub więcej niezależnych próbek z tej samej populacji ogólnej, utworzonych tą samą metodą i typem. Wskazane jest uciekanie się do prób przenikających się, jeśli konieczne jest uzyskanie w krótkim czasie wstępnych wyników badań reprezentacyjnych. Przenikające się próbki są skuteczne w ocenie wyników ankiety. Jeżeli wyniki są takie same w niezależnych próbach, oznacza to wiarygodność danych z badania próby. Próbki wzajemnie przenikające się mogą czasami być wykorzystywane do testowania pracy różnych badaczy, prosząc każdego badacza o przeprowadzenie innej ankiety na próbie. Błąd standardowy dla próbek przenikających się definiuje się tak samo jak dla typowego próbkowania proporcjonalnego. Próbki wzajemnie przenikające się wymagają więcej pracy i pieniędzy niż inne typy, dlatego badacz musi wziąć to pod uwagę podczas projektowania ankiety próbnej. Błędy graniczne dla różnych metod doboru i rodzajów próbkowania określa wzór: Δ = tμ, gdzie μ jest odpowiednim błędem standardowym. WYKŁAD №7. Analiza indeksu 1. Ogólna koncepcja indeksów i metody indeksowania W praktyce statystycznej indeksy wraz ze średnimi są najczęstszymi wskaźnikami statystycznymi. Za ich pomocą scharakteryzowano rozwój gospodarki narodowej jako całości i jej poszczególnych sektorów, zbadano rolę poszczególnych czynników w kształtowaniu najważniejszych wskaźników ekonomicznych. Wskaźniki wykorzystywane są również w międzynarodowych porównaniach wskaźników ekonomicznych, określających poziom życia, monitorujących działalność gospodarczą w gospodarce itp. Indeks (łac. Index) to wartość względna pokazująca, ile razy poziom badanego zjawiska w danych warunkach różni się od poziomu tego samego zjawiska w innych warunkach. Różnica warunków może przejawiać się w czasie (wskaźniki dynamiki), w przestrzeni (wskaźniki terytorialne) oraz w wyborze pewnego poziomu warunkowego jako podstawy porównania. W zależności od pokrycia elementów populacji (jej obiektów, jednostek i ich cech) wyróżnia się wskaźniki indywidualne (elementarne) i sumaryczne (złożone), które dzielą się na ogólne i grupowe. Indeksy indywidualne - jest to wynik porównania dwóch wskaźników związanych z tym samym przedmiotem, na przykład porównania cen produktu, wielkości jego sprzedaży itp. W analizie statystycznej i ekonomicznej działalności przedsiębiorstw i branż poszczególne wskaźniki szeroko stosowane są wskaźniki jakościowe i ilościowe, np. wskaźnik cen . Określone wzorem: 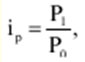 Wskaźnik cen charakteryzuje względną zmianę poziomu ceny jednostkowej każdego rodzaju produktu w okresie sprawozdawczym w porównaniu z wartością bazową i jest wskaźnikiem jakościowym. Wskaźnik objętości fizycznej określa wzór: 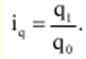 Wskaźnik wielkości fizycznej pokazuje, ile razy zmieniła się produkcja tego rodzaju produktu w okresie sprawozdawczym w stosunku do okresu, z którym dokonano porównania i jest wskaźnikiem ilościowym. Indeks złożony charakteryzuje stosunek poziomów kilku elementów populacji (na przykład zmiana wielkości produkcji kilku rodzajów produktów o innej postaci materiału naturalnego lub zmiana poziomu wydajności pracy w produkcja kilku rodzajów produktów). Jeżeli badana populacja składa się z kilku grup, to wskaźnikami złożonymi, z których każdy charakteryzuje zmianę poziomów odrębnej grupy jednostek, są grupa (wskaźniki cząstkowe), a wskaźnik złożony, obejmujący całą populację jednostek , to indeks ogólny (całkowity). Indeksy złożone wyrażają stosunek złożonych zjawisk społeczno-gospodarczych i składają się z dwóch części: 1) od wartości indeksowanej; 2) z licznika, który nazywa się wagą. Wskaźnik, którego zmiana charakteryzuje indeks, nazywany jest indeksowanym. Indeksowane wskaźniki mogą być dwojakiego rodzaju. Niektóre z nich mierzą ogólną, całkowitą wielkość (objętość) konkretnego zjawiska i są warunkowo nazywane wolumetrycznymi, ekstensywnymi (ilość, tj. fizyczna objętość danego rodzaju produktu, liczba pracowników, całkowite koszty pracy przy produkcji, całkowity koszt produkcji itp.).P.). Wskaźniki te są uzyskiwane w wyniku bezpośrednich obliczeń lub sumowania i mają charakter wstępny, pierwotny. Inne wskaźniki mierzą poziom zjawiska lub cechy w odniesieniu do tej lub innej jednostki populacji i są warunkowo nazywane jakościowymi, intensywnymi: wydajność produkcji na jednostkę czasu (lub na pracownika), czas pracy na jednostkę produkcji, jednostkowy koszt produkcja itp. Wskaźniki te uzyskuje się poprzez podzielenie wskaźników wolumetrycznych, tj. mają one wyliczony, drugorzędny charakter. Mierzą intensywność, efektywność zjawiska lub procesu i z reguły są wartościami średnimi lub względnymi. Podczas korzystania z metody indeksowej stosuje się pewną symbolikę, tj. system konwencji. Każdy indeksowany wskaźnik jest oznaczony konkretną literą, zwykle łacińską): Q - ilość (objętość) wyprodukowanych produktów (lub ilość sprzedanych towarów) tego typu w ujęciu fizycznym; T - całkowity koszt czasu pracy (robocizny) przy wytwarzaniu tego typu produktu, mierzony w roboczogodzinach lub osobodniach; w niektórych przypadkach ta sama litera wskazuje średnią liczbę pracowników; z - koszt jednostkowy produkcji; p to cena jednostki produkcji lub towaru; M - całkowite zużycie surowców, materiału lub paliwa do wytworzenia produktów danego rodzaju i objętości. Wskaźniki dla okresu bazowego mają we wzorach indeks dolny „0”, a dla okresu porównywanego (bieżącego, sprawozdawczego) znak „1”. Poszczególne indeksy oznaczane są literą i oraz dodatkowo opatrzone indeksem dolnym - oznaczeniem indeksowanego wskaźnika. Tak, 1Q oznacza indywidualny wskaźnik ilości (fizycznej wielkości) wytworzonych produktów (lub sprzedanych towarów) danego rodzaju; iz - indywidualny wskaźnik kosztu jednostkowego danego rodzaju produktu itp. Indeksy złożone są oznaczone literą I i towarzyszą im także wskaźniki indeksowe wskaźników, których zmianę charakteryzują. Na przykład jat - złożony wskaźnik pracochłonności jednostki produkcyjnej itp. Poszczególne indeksy są zwykłymi wartościami względnymi, to znaczy można je nazwać indeksami tylko w szerokim tego słowa znaczeniu. Indeksy w wąskim znaczeniu, lub indeksy właściwe, są również wskaźnikami względnymi, ale szczególnego rodzaju. Mają bardziej złożoną metodę konstrukcji i obliczeń, a specyficzne metody ich budowy są istotą metody wskaźnikowej. Zjawiska społeczno-gospodarcze i charakteryzujące je wskaźniki mogą być współmierne, czyli mieć wspólną miarę, i niewspółmierne. Zatem wolumeny produktów lub towarów tego samego rodzaju i rodzaju, wytwarzane w różnych przedsiębiorstwach lub sprzedawane w różnych sklepach, są współmierne i można je sumować, podczas gdy wolumeny różnych rodzajów produktów lub towarów są niewspółmierne i nie można ich bezpośrednio zsumować. Nie da się na przykład dodać kilogramów chleba z litrami mleka, metrami sukna i par butów. Niewspółmierność i niemożność bezpośredniego sumowania w konstrukcji i obliczaniu wskaźnika złożonego tłumaczy się tutaj nie tyle różnicą w naturalnych jednostkach miary, ile różnicą we właściwościach konsumenckich, nierówną naturalno-materialną formą tych produktów lub towarów. W związku z tym, aby obliczyć wskaźniki złożone, konieczne jest doprowadzenie ich części składowych do porównywalnej postaci. Jedność różnych rodzajów produktów lub różnych towarów polega na tym, że są one produktami pracy, mają określoną wartość i jej pieniężny wyraz – cenę (p). Każdy produkt ma również określony koszt (z) i pracochłonność (t). Te wskaźniki jakościowe można wykorzystać jako miarę ogólną - współczynniki porównania produktów heterogenicznych. Mnożąc wielkość każdego rodzaju produktu (Q) przez odpowiednią cenę, koszt lub pracochłonność jednostki produkcji, zredukujemy różne produkty do tej samej jednostki i otrzymamy porównywalne liczby, które można podsumować. Podobnie sytuacja wygląda przy konstruowaniu złożonych wskaźników wskaźników jakościowych. Załóżmy na przykład, że interesuje nas zmiana ogólnego poziomu cen różnych sprzedawanych towarów. Choć formalnie ceny różnych towarów są współmierne, to ich bezpośrednie zsumowanie (bez uwzględniania ilości każdego sprzedanego towaru) daje wartość pozbawioną samodzielnego znaczenia praktycznego. Dlatego złożonego wskaźnika cen nie można skonstruować jako stosunku prostych sum: 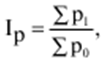 Ceny poszczególnych towarów nie uwzględniają określonej liczby sprzedanych towarów oraz ich statystycznej wagi i roli w procesie obrotu towarowego. Proste sumy cen poszczególnych dóbr również nie nadają się do konstruowania indeksu złożonego, także dlatego, że ceny zależą od jednostki miary dóbr, której zmiana da różne ilości i inną wartość indeksu. W związku z tym, konstruując złożone wskaźniki wskaźników jakościowych, nie można ich rozpatrywać w oderwaniu od powiązanych z nimi wskaźników wolumetrycznych, na jednostkę, z której obliczane są te wskaźniki jakościowe. Tylko poprzez pomnożenie jednego lub drugiego wskaźnika jakościowego (p, z, t) przez wskaźnik wolumenu (Q) bezpośrednio z nimi związany, możliwe jest uwzględnienie roli i wagi statystycznej każdego rodzaju produktu (lub produktu) w określony proces gospodarczy – proces kształtowania się wartości całkowitej (pQ), kosztu całkowitego (zQ), całkowitego kosztu czasu pracy (tQ) itp. Jednocześnie możliwe jest uzyskanie wskaźników, których sumowanie ma znaczenie praktyczne. Zatem pierwszą cechą metody indeksowej i samych indeksów jest to, że indeksowany wskaźnik nie jest rozpatrywany w oderwaniu, ale w połączeniu z innymi wskaźnikami. Mnożąc indeksowany wskaźnik przez inny, powiązany z nim, sprowadzamy różne zjawiska do ich jedności, zapewniamy ich porównywalność ilościową oraz uwzględniamy ich wagę w rzeczywistym procesie gospodarczym. Dlatego wskaźniki mnożnikowe związane ze wskaźnikami indeksowanymi są zwykle nazywane wagami indeksów, a mnożenie przez nie nazywane jest wagami. Jednak pomnożenie wartości indeksowanego wskaźnika przez wartości innego wskaźnika (wagi) z nim związanego nie rozwiązuje jeszcze problemu samego indeksu. Mnożąc na przykład ceny odpowiednich ilości towarów, można znaleźć wartość tych towarów w każdym okresie, a tym samym rozwiązać problem współmierności i ważenia. Natomiast porównując otrzymane sumy produktów (∑p1Q1 i poQo) podaje wskaźnik charakteryzujący zmianę obrotów handlowych w zależności od dwóch czynników – cen i ilości (wolumenów) towarów, ale nie charakteryzuje zmian poziomu cen i poziomu produkcji towarów: 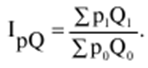 Aby wskaźnik charakteryzował zmianę tylko jednego czynnika, należy w powyższym wzorze wyeliminować zmianę drugiego czynnika, ustalając ją zarówno w liczniku, jak i mianowniku na poziomie tego samego okresu. Przykładowo, aby oszacować wolumen produktów niejednorodnych w dwóch porównywanych okresach, należy wycenić towary sprzedane w obu okresach po jednakowych np. cenach podstawowych (p0). Otrzymany wskaźnik będzie odzwierciedlał zmianę tylko jednego czynnika - fizycznej wielkości produkcji Q: 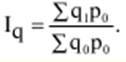 Aby ocenić zmianę poziomu cen dla grupy towarów, należy porównać te same ilości tych towarów, tj. liczba towarów (Q) powinna być ustalona zarówno w liczniku, jak i w mianowniku wskaźnika na tym samym poziomie (albo na poziomie podstawowym, albo na poziomie raportowania). Zatem konstruowane złożone indeksy cen będą charakteryzować tylko zmianę cen, czyli wskaźnik indeksowany, gdyż zmiana wag (Q) zostanie wyeliminowana (wyeliminowana) ze względu na ich utrwalenie:  W obu przypadkach (Tq oraz Tp) indeks odzwierciedlał zmianę tylko jednego czynnika – wskaźnika indeksowanego – w związku z utrwaleniem się drugiego (wag) na tym samym poziomie. Eliminowanie wpływu zmieniających się wag poprzez ustalanie ich w liczniku i mianowniku indeksu na tym samym poziomie to druga cecha indeksów i metody indeksowej. Biorąc pod uwagę problemy, jakie pojawiają się przy konstrukcji rzeczywistych wskaźników, zadaniem było przedstawienie porównawczego opisu poziomów złożonego zjawiska składającego się z elementów niejednorodnych (różne rodzaje produktów itp.). Tak, Tp powinien pokazywać, jak ogólnie zmienił się poziom cen, tj. mierzyć dynamikę cen różnych towarów w postaci jednego uogólniającego wskaźnika. Historycznie same wskaźniki powstały w wyniku rozwiązania tego konkretnego zadania ekonomicznego - zadania uogólnienia, syntezy dynamiki poszczególnych elementów złożonego zjawiska w jednym wskaźniku uogólniającym - indeksie złożonym. Jednak same wskaźniki służą do rozwiązania innego problemu – do analizy wpływu zmian poszczególnych wskaźników-czynników na zmianę wskaźnika reprezentującego funkcję tych czynników-argumentów. Całkowity koszt sprzedanych towarów jest więc funkcją ich cen (p) i ilości (wolumen - Q). W związku z tym możliwe jest postawienie zadania pomiaru wpływu każdego z tych czynników na zmianę obrotów: określenie, jak zmieniły się one z osobna pod wpływem zmian każdego z czynników. Indeksy służące do rozwiązywania tego typu problemów analitycznych są również budowane z wykorzystaniem specyficznych cech metody indeksowej - ważenia i eliminacji zmian wag. Sam wskaźnik jest więc wskaźnikiem względnym szczególnego rodzaju, w którym poziomy zjawiska społeczno-gospodarczego są rozpatrywane w połączeniu z innym (lub innym) zjawiskiem, którego zmiana jest w tym przypadku eliminowana. Wskaźniki związane z indeksowanym wskaźnikiem są używane jako wagi indeksów, a ważenie i eliminacja zmian wag (ustalenie w liczniku i mianowniku indeksu na tym samym poziomie) to specyfika samych indeksów i metody indeksowania. 2. Zagregowane indeksy wskaźników jakościowych Każdy wskaźnik jakościowy jest powiązany z takim lub innym wskaźnikiem wolumenu, na podstawie jednostki miary, której jest obliczany (lub jednostki miary, której dotyczy). Zatem cena jednostkowa towaru jest powiązana z jego ilością (Q); wskaźniki jakości takie jak cena (p), koszt (z) i pracochłonność są związane z wielkością produkcji  jednostek produkcji, a także jednostkowego zużycia surowców, materiałów 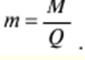 Złożone wskaźniki jakości nie powinny ogólnie charakteryzować ich zmiany w odniesieniu do dowolnego dowolnego zestawu towarów lub produktów, ale zmianę cen, kosztów własnych, pracochłonności lub kosztów jednostkowych całkowicie określonej ilości wyprodukowanych towarów lub towarów sprzedanych. Osiąga się to poprzez ważenie - mnożenie poziomów indeksowanego wskaźnika jakościowego przez wartość związanego z nim wskaźnika (wagi) wolumenu - i ustalanie wag w liczniku i mianowniku wskaźnika na tym samym poziomie. Porównanie sum takich produktów daje indeks zagregowany. Podobnie można skonstruować zagregowane wskaźniki dynamiki kosztu i pracochłonności jednostki produkcji, a także wskaźnik jednostkowego zużycia surowców lub materiałów. Głównym problemem przy konstruowaniu tych wskaźników kompozytowych jest ekonomicznie uzasadniony wybór poziomu, na którym należy ustalić wagi wskaźnika, czyli w tym przypadku wielkości produkcji (towarów) – Q. Zwykle przed złożonym wskaźnikiem dynamiki wskaźnika jakościowego zadaniem jest zmierzenie nie tylko względnej zmiany poziomu, ale także bezwzględnej wartości efektu ekonomicznego, jaki w bieżącym okresie uzyskuje się w wyniku tej zmiany : kwota oszczędności dla kupujących z tytułu obniżek cen (lub kwota ich dodatkowych kosztów, jeśli ceny wzrosły), kwota oszczędności (lub dodatkowych kosztów) z tytułu zmian kosztów itp. Takie sformułowanie problemu prowadzi do wskaźników dynamiki wskaźników jakościowych z wagami bieżącego okresu. Po pierwsze, badacza interesuje zmiana kosztu lub pracochłonności produktów, które są obecnie wytwarzane, a nie w przeszłości; po drugie, efekt ekonomiczny powinien być powiązany z rzeczywistymi wynikami bieżącego, sprawozdawczego, a nie poprzedniego (bazowego) okresu. Jako przykład podaję zagregowany wskaźnik kosztów: 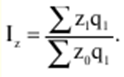 Zatem w tym indeksie licznik jest sumą rzeczywistych kosztów produktów w okresie sprawozdawczym, a mianownik jest wartością warunkową, która pokazuje, ile pieniędzy wydano by na produkty okresu sprawozdawczego, gdyby koszt jednostkowy każdego rodzaju produkt pozostał na poziomie bazowym. Realny efekt ekonomiczny uzyskany poprzez zmianę jednostkowego kosztu produkcji wyrażony jest jako wartość bezwzględna, która jest liczona jako różnica pomiędzy wielkościami w liczniku i mianowniku wskaźnika 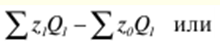 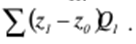 W konsekwencji ważenie wagami okresu sprawozdawczego (bieżącego) wiąże wskaźnik wskaźnika jakościowego ze wskaźnikiem efektu ekonomicznego, który uzyskuje się poprzez zmianę wskaźnika indeksowanego. Dlatego zagregowane wskaźniki dynamiki wskaźników jakościowych są zwykle budowane i obliczane z wagami okresu sprawozdawczego: 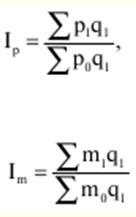 W tych wskaźnikach różnica między licznikiem a mianownikiem charakteryzuje: w pierwszym przypadku spadek lub wzrost kosztu nabycia tego samego zestawu towarów, w zależności od znaku różnicy; w drugim przypadku - wzrost lub spadek zużycia materiałów do produkcji tej samej ilości produktów. 3. Zagregowane indeksy wskaźników wolumenu Wskaźniki wolumetryczne mogą być współmierne (ilość produktów lub towarów tego samego rodzaju) i niewspółmierne (ilość produktów lub towarów różnych rodzajów - Q). Porównywalne wskaźniki wolumenu można bezpośrednio zsumować, a konstrukcja wskaźników agregatowych nie nastręcza trudności. Aby uzyskać ogólny wynik i zbudować zagregowany wskaźnik odmiennego wskaźnika objętości, należy najpierw zmierzyć poszczególne wartości tego wskaźnika. Opierając się na ekonomicznej istocie zjawiska, konieczne jest znalezienie wspólnej miary i wykorzystanie jej jako współczynnika pomiaru. Taką powszechną miarą dla wskaźników wolumetrycznych jest skojarzona wskaźniki jakości z nimi. Zatem wolumeny różnych rodzajów produktów można mierzyć za pomocą ceny (p), kosztu (z) i pracochłonności (t) jednostki tych produktów. Mnożąc indeksowany wskaźnik wolumenu przez taki lub inny wskaźnik jakościowy, nie tylko daje się możliwość sumowania, ale jednocześnie uwzględnia się także rolę każdego elementu, np. produktu, w rzeczywistym procesie gospodarczym, który jest jego statystyczną wagą w tym procesie. Ponieważ różne wskaźniki jakościowe mogą pełnić rolę wag w indeksie wolumenu, pojawia się pytanie, które z nich należy zastosować. Kwestia ta w każdym konkretnym przypadku musi być rozwiązana zgodnie z postawionym przed indeksem poznawczym zadaniem ekonomicznym, tj. wybór pewnych wag-komensatorów musi być ekonomicznie uzasadniony. W praktyce prac ekonomicznych i statystycznych ceny są zwykle używane jako wagi dla zagregowanego wskaźnika produkcji. W ten sposób budowane są wskaźniki wolumenu produktów przemysłowych i rolnych, a także wskaźniki fizycznego wolumenu handlu. W wielu przypadkach zmiana wielkości produkcji jest dla nas interesująca nie sama w sobie, ale z punktu widzenia jej wpływu na zmianę wskaźnika bardziej złożonego zamówienia - całkowitego kosztu produkcji, jej całkowity koszt, całkowity koszt czasu pracy, całkowita wielkość produkcji w danym jej dziale itp. W takich przypadkach wybór wag-składników jest determinowany relacją wskaźników-czynników, od których zależy bardziej złożony wskaźnik . Aby indeks odzwierciedlał tylko zmianę indeksowanego wskaźnika wolumenu, wagi w jego liczniku i mianowniku są ustalone na poziomie tego samego okresu. W praktyce pracy ekonomicznej we wskaźnikach dynamiki wskaźników wolumenu wagi są zwykle ustalane na poziomie okresu bazowego. Umożliwia to budowanie systemów połączonych ze sobą indeksów. Dla poszczególnych wskaźników objętości (wielkość sprzedaży, wielkość produktywności, powierzchnia zasiewu) wagi dobierane są na poziomie okresu bazowego. Na przykład:  Gdzie jan - złożony wskaźnik wydajności; Ip - złożony wskaźnik kosztu obrotu towarowego; Iq - skonsolidowany wskaźnik kosztów. W przeciwieństwie do wskaźników jakości, które są obliczane na porównywalnym zakresie jednostek (produktów porównywalnych), złożone wskaźniki wolumenu, ze względu na kompletność i dokładność, powinny obejmować cały zakres wyprodukowanych lub sprzedanych jednostek w każdym okresie. W związku z tym pojawia się pytanie, jakie wagi należy przyjąć dla tych rodzajów produktów, które nie zostały wyprodukowane w jednym z porównywanych okresów. W praktyce statystycznej w takich przypadkach stosuje się dwie metody. Przy obliczaniu wskaźników wielkości produkcji przemysłowej nowe rodzaje produkcji przemysłowej, dla których nie ma cen okresu bazowego, są szacowane warunkowo po cenach okresu bieżącego. Przy obliczaniu wskaźników wolumenu sprzedanych towarów stosuje się metodę opartą na warunkowym założeniu, że ceny nowych towarów zmieniły się w takim samym stopniu, jak ceny porównywalnego asortymentu towarów podobnych. 4. Serie indeksów zagregowanych o stałych i zmiennych wagach Badając dynamikę zjawisk ekonomicznych, budowane są i obliczane wskaźniki dla szeregu kolejnych okresów. Tworzą one serię indeksów podstawowych lub łańcuchowych. W wielu indeksach podstawowych indeksowany wskaźnik w każdym indeksie jest porównywany z poziomem z tego samego okresu, a w szeregu indeksów łańcuchowych indeksowany wskaźnik jest porównywany z poziomem z poprzedniego okresu. W każdym indywidualnym indeksie wagi w jego liczniku i mianowniku są z konieczności ustalone na tym samym poziomie. Jeśli budowany jest szereg indeksów, wówczas wagi w nim zawarte mogą być stałe dla wszystkich indeksów szeregu lub zmienne. Szereg podstawowych wskaźników wielkości produkcji: 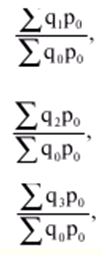 Stałe wagi (p0) posiada również szereg indeksów łańcuchowych:  Szereg indeksów cen łańcuchowych:  W przypadku indeksów dynamiki o stałych wagach obowiązuje zależność między łańcuchowymi a podstawowymi tempami wzrostu (wskaźnikimi):  Zatem stosowanie stałych wag na przestrzeni wielu lat umożliwia przejście od indeksów łańcuchowych do indeksów podstawowych i odwrotnie. Dlatego szeregi wskaźników wielkości produkcji i wielkości sprzedanych towarów konstruowane są w praktyce statystycznej o stałych wagach. Na przykład we wskaźnikach wolumenu jako stałe wagi stosuje się ceny ustalone na poziomie ustalonym 1 stycznia dowolnego roku bazowego. Takie ceny, stosowane od wielu lat, nazywane są porównywalnymi (stałymi). Zastosowanie porównywalnych cen we wskaźnikach wielkości produkcji (towarów) pozwala, poprzez proste sumowanie, uzyskiwać wyniki za kilka lat. Ceny porównywalne nie powinny znacząco różnić się od obecnych (bieżących) cen. W związku z tym podlegają okresowym przeglądom, przechodząc do nowych porównywalnych cen. Aby móc obliczyć wskaźniki wielkości produkcji dla długich okresów, w których stosowano różne porównywalne ceny, produkcję jednego roku wycenia się zarówno według starych, jak i nowych stałych cen. Indeks dla długiego okresu jest wyliczany metodą łańcuchową, czyli mnożąc indeksy dla poszczególnych segmentów tego okresu. Szeregi indeksów wskaźników jakościowych, które są ekonomicznie poprawne do ważenia według wag bieżącego okresu, są konstruowane z wagami zmiennymi. 5. Budowa skonsolidowanych wskaźników terytorialnych Przy konstruowaniu wskaźników terytorialnych, tj. przy porównywaniu wskaźników w przestrzeni (międzyokręgowych, porównania między różnymi przedsiębiorstwami itp.), pojawiają się pytania o wybór bazy porównawczej i regionu (obiektu), na poziomie którego powinny byc naprawionym. W każdym konkretnym przypadku kwestie te należy rozwiązać w oparciu o cele badania. Wybór bazy porównawczej zależy w szczególności od tego, czy porównania będą dwustronne (np. porównanie wskaźników dwóch sąsiednich jednostek terytorialnych), czy wielostronne (porównanie wskaźników kilku terytoriów, obiektów). W porównaniach dwustronnych każde terytorium lub obiekt o tej samej podstawie może być traktowane zarówno jako porównanie, jak i jako baza porównawcza. W związku z tym pojawia się pytanie o ustalenie wag wskaźnika złożonego na poziomie konkretnego regionu (obiektu). Niech na przykład trzeba określić, w którym z dwóch obszarów io ile procent jednostkowy koszt produkcji jest niższy, a wielkość jego produkcji większa. Jeśli porównamy obszar A z obszarem B, dość rozsądnym i prostym sposobem jest ustalenie wskaźnika kosztów jako wagi ogólnej wielkości produkcji dla obu terytoriów (Q = QA + QE), to otrzymujesz: 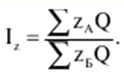 W przypadku porównań wielostronnych, na przykład przy porównywaniu wskaźników jakościowych w kilku obszarach, konieczne jest poszerzenie granic terytorium, na poziomie którego odpowiednio ustalane są wagi. W skonsolidowanych wskaźnikach terytorialnych wskaźników wielkości, jako wagi można przyjąć średnie poziomy odpowiednich wskaźników jakościowych liczonych łącznie dla porównywanych terytoriów. 6. Średnie indeksy W zależności od metodyki obliczania indeksów indywidualnych i złożonych wyróżnia się średnią arytmetyczną i średnie indeksy harmoniczne. Innymi słowy, indeks ogólny zbudowany na podstawie indeksu indywidualnego przyjmuje postać średniej arytmetycznej lub indeksu harmonicznego, czyli można go przeliczyć na średnią arytmetyczną i średni indeks harmoniczny. Pomysł skonstruowania indeksu złożonego jako średniej poszczególnych indeksów (grupowych) jest całkiem naturalny, ponieważ indeks złożony jest ogólną miarą charakteryzującą średnią zmianę indeksowanego wskaźnika i oczywiście jego wartość powinna zależeć od wartości poszczególnych indeksów. A kryterium poprawności konstrukcji wskaźnika złożonego w postaci wartości średniej (wskaźnik średni) jest jego identyczność z indeksem zagregowanym. Przekształcenie wskaźnika zagregowanego na średnią wskaźników indywidualnych (grupowych) przeprowadza się w następujący sposób: albo w liczniku, albo w mianowniku wskaźnika zagregowanego, wskaźnik indeksowany zastępuje się jego wyrażeniem w kategoriach odpowiedniego wskaźnika indywidualnego . Jeżeli taka zamiana zostanie dokonana w liczniku, to indeks zagregowany zostanie przeliczony na średnią arytmetyczną, jeśli w mianowniku, to na średnią harmoniczną poszczególnych indeksów. Na przykład znany jest indywidualny wskaźnik objętości fizycznej i koszt produkcji każdego rodzaju w okresie bazowym (q0p0). Podstawą wyjściową do konstrukcji średniej poszczególnych wskaźników jest złożony wskaźnik objętości fizycznej:  Z dostępnych danych tylko mianownik formuły można uzyskać bezpośrednio przez sumowanie. Licznik można otrzymać mnożąc koszt pojedynczego rodzaju produktu okresu bazowego przez indywidualny indeks: 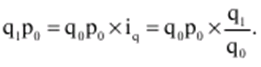 Wtedy formuła indeksu złożonego przyjmie postać: 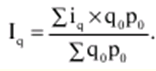 W konsekwencji otrzymujemy średni arytmetyczny wskaźnik objętości fizycznej, gdzie wagami są koszt poszczególnych rodzajów produktów w okresie bazowym. Załóżmy, że dysponujemy informacjami o dynamice wolumenu produkcji każdego rodzaju produktu (iq) oraz koszt każdego rodzaju produktu w okresie sprawozdawczym (p1q1). Aby określić całkowitą zmianę produkcji przedsiębiorstwa w tym przypadku, wygodnie jest użyć formuły Paasche: 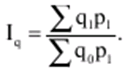 Licznik wzoru można otrzymać sumując wielkości q1p1, a mianownik - dzieląc rzeczywisty koszt każdego rodzaju produktu przez odpowiedni indywidualny wskaźnik fizycznej wielkości produkcji, tj. dzieląc p1q1 / jaq, następnie: 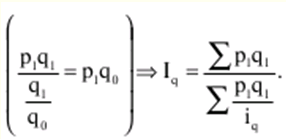 W ten sposób otrzymujemy wzór na średni ważony wskaźnik harmoniczny objętości fizycznej. Zastosowanie takiego lub innego wzoru na wskaźnik objętości fizycznej (agregat, średnia arytmetyczna i średnia harmoniczna) zależy od dostępnych informacji. Należy również pamiętać, że indeks zagregowany można przeliczyć i obliczyć jako średnią poszczególnych indeksów tylko wtedy, gdy lista rodzajów produktów lub towarów (ich zakres) w okresach sprawozdawczych i bazowych pokrywa się, tj. gdy indeks zagregowany jest zbudowany na porównywalnym zakresie jednostek (wskaźniki agregatowe wskaźników jakościowych oraz indeksy agregatowe wskaźników wolumenowych, z uwzględnieniem porównywalnego asortymentu). WYKŁAD №8. Charakterystyka systemu wskaźników determinujących działalność gospodarczą przedsiębiorstwa 1. Zasady tworzenia systemu wskaźników Ogólna zasada leżąca u podstaw tworzenia systemu wskaźników statystyki przedsiębiorstw jest następująca. 1. Przedmiot statystyk - jest to zbieranie i przetwarzanie wskaźników ekonomicznych, które pozwalają na analizę działalności gospodarczej przedsiębiorstw różnych typów i branż. Zbieranie informacji statystycznych o zamówieniach konkretnych konsumentów odbywa się w ramach statystyki branżowej. Na przykład jest to działalność małych przedsiębiorstw. Wszystkie informacje podzielone są na dwa strumienie: 1) główne wyniki całej działalności gospodarczej małych przedsiębiorstw, niezależnie od ich przynależności branżowej (formularz nr MP - sekcja T, najważniejsze wskaźniki ekonomiczne); 2) wskaźniki statystyczne produkcji produktów lub świadczenia usług w małych przedsiębiorstwach niektórych branż, w tym produkcji w ujęciu fizycznym, opracowywane są z wykorzystaniem sekcji TT formularza nr MP i szeregu form branżowych, które charakteryzują się znacznym zróżnicowanie i wyszczególnienie ilości żądanych informacji. Trwają również prace nad przygotowaniem wskaźników bazowych do statystyk dotyczących dużych i średnich przedsiębiorstw. Obszary analizy działalności dużych i średnich przedsiębiorstw, które decydują o składzie informacji gromadzonych w ramach statystyki przedsiębiorstw, to: 1) efektywność działalności gospodarczej przedsiębiorstwa, stosunek wyników i kosztów (struktura zysków i kosztów, opłacalność produkcji, stosunek aktywów i pasywów itp.); 2) stan majątkowy i finansowy przedsiębiorstw (środki trwałe i obrotowe, źródła i kierunki wydawania pieniędzy, zadłużenie itp.); 3) działalność inwestycyjna i gospodarcza przedsiębiorstw (inwestycje, moce produkcyjne i ich wykorzystanie, stan zapasów, popyt na produkty, przepływ siły roboczej itp.); 4) cechy strukturalne i demograficzne przedsiębiorstw. Etapy pracy w celu określenia składu głównych wskaźników ekonomicznych: 1) inwentaryzacja i analiza aktualnej sprawozdawczości branżowej pod kątem składu wskaźników, metodologii ich tworzenia, terminów składania, kręgu jednostek sprawozdawczych itp.; 2) tworzenie głównych wskaźników ekonomicznych na poziomie mikro, z uwzględnieniem ogólnej struktury schematu koncepcyjnego do analizy rozwoju społeczno-gospodarczego Rosji i składu poszczególnych bloków specjalnych; 3) porównanie wykazu wskaźników ze wskaźnikami statystycznymi dostępnymi w bieżącej sprawozdawczości; 4) opracowanie formularzy sprawozdawczości statystycznej dla dużych i średnich przedsiębiorstw; 5) przygotowywanie propozycji zmian w formach statystycznej sprawozdawczości branżowej. Sprawozdawczość branżowa obowiązuje w zakresie produkcji. Obejmuje zagadnienia rozliczania produktów w ujęciu wartościowym i fizycznym ze wszystkimi jego obliczeniami i odzwierciedla specyfikę pracy przedsiębiorstw w danej branży. Zintegrowane formularze sprawozdawcze pomagają wyeliminować powtarzalność wskaźników statystycznych, zmniejszyć obciążenie informacyjne przedsiębiorstwa. 2. Forma badania strukturalnego przedsiębiorstw to jeden z przykładów zintegrowanych formularzy sprawozdawczych dla różnych typów producentów. Główny cel badanie strukturalne to regularne dostarczanie danych statystycznych o stanie struktury systemu produkcyjnego w celu kompleksowej analizy głównych parametrów działalności finansowej i gospodarczej przedsiębiorstw, tworzenia poszczególnych wskaźników makroekonomicznych. 2. Proces produkcyjny. Charakterystyka jego modelu Proces produkcyjny to zestaw odrębnych procesów pracy, których celem jest przekształcenie surowców i materiałów w gotowe produkty. Skład procesu produkcyjnego ma pewien wpływ na budowę przedsiębiorstwa i jego jednostek produkcyjnych. Proces produkcyjny jest podstawą działalności gospodarczej każdego przedsiębiorstwa. Głównymi czynnikami, które pomagają określić charakter produkcji są: 1) środki pracy (maszyny, urządzenia, budynki, konstrukcje itp.); 2) przedmioty pracy (surowce, materiały, półprodukty); 3) praca jest działalnością ludzi. Interakcja tych głównych czynników kształtuje skład procesu produkcyjnego. Do zasobów pracy odnosi się do personelu, siły roboczej, która jest zdefiniowana jako zdolność osoby do pracy. Siła robocza w procesie produkcji jest zużywana w postaci kosztów pracy żywej, mierzonych czasem pracy, jako naturalną miarą celowej aktywności pracowników. Przedsiębiorca, który w swojej działalności gospodarczej wykorzystuje personel, ma do czynienia z faktem, że siła robocza na rynku pracy jest produktem szczególnie specyficznym, posiadającym wartość. Ilość wydatkowanej pracy jest wyrażona w wartościach pieniężnych (płace). Aby proces produkcyjny przebiegał sprawnie, przedsiębiorca musi uzyskać wystarczająco dokładne i wszechstronne informacje o całkowitej ilości dostępnych zasobów pracy, jej cechach jakościowych (skład zawodowy, kwalifikacje itp.) oraz specyfice kształtowania się kosztów pracy. Zasoby środków pracy to zbiór różnych środków trwałych produkcyjnych. Podsystem informacyjny zasobów środków pracy powinien zawierać wskaźniki odzwierciedlające ich dostępność, skład według rodzaju, stanu technicznego i roli w kształtowaniu kosztów produkcji i dystrybucji. Cechą środków pracy jest ich funkcjonowanie w kilku cyklach produkcyjnych. Środki pracy przenoszą swoją wartość na produkt w częściach, to znaczy w miarę zużywania się. W kosztach produkcji jednego cyklu produkcyjnego środki pracy są zawarte w odpowiedniej części ich amortyzacji, która jest określona w kategoriach pieniężnych przez odpowiednią kwotę amortyzacji. Do przedmiotów pracy przedsiębiorstwa obejmują: zapasy surowców, materiałów, paliw i innych zasobów materiałowych, w tym półproduktów, komponentów i zapasów towarów. Wszystkie te zasoby przedmiotów pracy przedsiębiorstwa są niezbędne do normalnego przebiegu procesów produkcyjnych. W ujęciu pieniężnym stanowią one większość kapitału obrotowego firmy, do którego zalicza się również środki w rozliczeniach, wolne środki pieniężne i inne rodzaje aktywów finansowych. Aby scharakteryzować obecność i wykorzystanie przedmiotów pracy, system wskaźników powinien zawierać dane dotyczące ich naturalnego i materialnego składu, dostępności, odbioru i wydatków w procesie produkcyjnym, charakterystykę efektywności ich zużycia itp., wskaźniki, które określą wkład przedmiotów pracy w kształtowanie całkowitego kosztu przedsiębiorstwa. Koszty produkcji związane z wykorzystaniem czynników produkcji przenoszone są zarówno na koszt całkowity, jak i na koszt wytworzonego produktu, który musi przewyższać koszt całkowity. Ostateczny wynik procesu produkcyjnego i obiegu dla przedsiębiorcy jest wyjaśniany w momencie otrzymania środków (przychodu) otrzymanych od nabywców produktów firmy w formie gotówkowej lub bezgotówkowej. Wpływy pieniężne otrzymane przez przedsiębiorcę są rozdzielane na kilka kierunków, są to: 1) zwrot kosztów związanych z wznowieniem produkcji w dowolnej wysokości określonej przez właściciela firmy, co wymaga zainwestowania środków finansowych w odnowienie zapasów przedmiotów pracy w celu utrzymania i odnowienia zasobów narzędzi pracy oraz opłacenie na koszty związane z bieżącą konsumpcją żywych zasobów pracy; 2) część przychodów przedsiębiorstwa przeznacza przedsiębiorca na potrzeby osobiste; 3) część wpływów trafia do środowiska zewnętrznego wobec przedsiębiorstwa (płatność podatków, wpłaty na fundusze pozabudżetowe i specjalne itp.). 3. Charakterystyka systemów wskaźników określających potencjał zasobowy i wyniki wszystkich działań przedsiębiorstwa” Rola zasobów pracy stale rośnie i to nie tylko w okresie stosunków rynkowych. Kolektyw pracowniczy - jedno z głównych zadań przedsiębiorcy, które jest kluczem do sukcesu działalności przedsiębiorczej, ekspresji i dobrobytu przedsiębiorcy. Zespół ludzi o podobnych poglądach i partnerów, którzy są w stanie zrealizować, zrozumieć i wdrożyć plany kierownictwa firmy, nazywany jest kolektywem pracowniczym. Stosunki pracy to złożony aspekt przedsiębiorstwa. Proces produkcji zależy od ludzi, czyli od ich chęci i umiejętności do pracy, a co za tym idzie od ich kwalifikacji. Powstające nowe systemy produkcyjne to nie tylko maszyny, ale także osoby ściśle współpracujące. Kapitał ludzki, wyposażenie i zapasy są podstawą konkurencyjności, wzrostu gospodarczego i wydajności. Główne czynniki wpływające na wzrost efektywności przedsiębiorstwa: 1) dobór i awans personelu; 2) szkolenie personelu i jego ustawiczne kształcenie; 3) stabilność i elastyczność składu pracowników; 4) poprawa materialnej i moralnej oceny pracy pracowników. Istnieją dwa kryteria wyboru i awansowania pracowników: 1) wysokie kwalifikacje zawodowe i umiejętność uczenia się; 2) doświadczenie komunikacyjne i chęć współpracy. Bezpieczeństwo zatrudnienia, zmniejszona rotacja pracowników, wysokie płace dają znaczący efekt ekonomiczny i wywołują wśród pracowników chęć poprawy efektywności pracy. Wynagrodzenia powinny stymulować wzrost wydajności pracy i działać motywująco. Aby zwiększyć wydajność i produktywność, konieczna jest zmiana zarówno płacy, jak i podejścia do jej kształtowania. Organizacja pracy i zarządzanie zespołem przedsiębiorstwa obejmuje: 1) zatrudnianie pracowników w niepełnym wymiarze godzin lub tygodniowo; 2) rozmieszczenie pracowników zgodnie z ustalonym systemem produkcji; 3) podział obowiązków wśród pracowników przedsiębiorstwa; 4) przekwalifikowanie lub szkolenie personelu; 5) stymulacja porodu; 6) doskonalenie organizacji pracy. Kolektyw pracy przedsiębiorstwa dostosowuje się do istniejącego systemu procesów produkcyjnych. Struktura procesu produkcyjnego oparta jest na naukowych zasadach organizacji pracy, do których należą: 1) podział pracy i doskonalenie jej współpracy w oparciu o podział procesu produkcyjnego; 2) dobór pracowników zawodowych i wykwalifikowanych oraz ich rozmieszczenie; 3) doskonalenie procesów pracy poprzez opracowywanie i wdrażanie racjonalnych metod i technik pracy; 4) doskonalenie obsługi zakładów pracy na podstawie jasnego uregulowania każdej funkcji usługowej; 5) wprowadzenie efektywnych form pracy zespołowej, rozwój usług wielooddziałowych i łączenia zawodów; 6) poprawa racjonowania pracy w oparciu o wykorzystanie rezerw, obniżenie kosztów pracy i najbardziej racjonalne sposoby eksploatacji sprzętu; 7) organizacja i prowadzenie systematycznych instruktaży produkcyjnych - zaawansowane szkolenie pracowników, wymiana doświadczeń i upowszechnianie zaawansowanych metod pracy; 8) tworzenie korzystnych warunków pracy i bezpieczeństwa pracy w zakresie stosunków sanitarno-higienicznych, psychofizjologicznych, estetycznych, wprowadzanie racjonalnych harmonogramów pracy, trybów pracy i odpoczynku w pracy. Ogólne wskaźniki realizacji tych zasad to: 1) wzrost wydajności pracy; 2) spełnienie wszystkich warunków pracy; 3) zadowolenie z treści pracy i jej atrakcyjności. Głównymi źródłami rekrutacji w przedsiębiorstwie są wszelkiego rodzaju instytucje edukacyjne, przedsiębiorstwa o podobnych zawodach oraz giełda pracy. Podział obowiązków i rozmieszczenie pracowników opiera się na systemie podziału pracy. Rozpowszechniły się następujące formy podziału pracy: 1) technologiczne – według rodzajów prac, zawodów i specjalności; 2) operacyjne - dla niektórych rodzajów operacji procesu technologicznego; 3) według funkcji wykonywanej pracy - głównej, pomocniczej, pomocniczej; 4) przez kwalifikację. Jeżeli właściciel przedsiębiorstwa wyselekcjonował pracowników spełniających wszystkie jego wymagania, wówczas konieczne jest sporządzenie umowy o pracę lub kontraktu – jest to umowa między przedsiębiorcą a osobą, która jest zatrudniana, a w praktyka domowa. Cały personel przedsiębiorstwa jest podzielony na kategorie. 1) pracownicy; 2) pracownicy; 3) specjaliści; 4) liderzy. Pracownicy przedsiębiorstwa to pracownicy bezpośrednio zaangażowani w tworzenie wartości materialnych lub świadczenie usług transportowych i produkcyjnych. Pracownicy dzielą się na głównych i pomocniczych. Ich stosunek jest analitycznym wskaźnikiem przedsiębiorstwa. Wskaźnik zatrudnienia głównych pracowników określa wzór:  gdzie Tvr to średnia liczba pracowników pomocniczych w przedsiębiorstwie, w warsztatach, na miejscu (osoba); Tr - średnia liczba wszystkich pracowników w przedsiębiorstwie, w warsztacie, na miejscu (osoba). Specjaliści i kierownicy (dyrektorzy, brygadziści, główni specjaliści itp.) organizują i zarządzają procesem produkcyjnym. Pracownicy to pracownicy wykonujący rozliczenia finansowe, zaopatrzenie i marketing oraz inne funkcje (agenci, kasjerzy, urzędnicy, sekretarki, statystycy itp.). Kwalifikacja pracy zależy od poziomu wiedzy specjalistycznej i umiejętności praktycznych oraz charakteryzuje stopień złożoności pracy. Zgodność zdolności, cech fizycznych i psychicznych każdego zawodu oznacza przydatność zawodową pracownika. Struktura personelu przedsiębiorstwa to stosunek różnych kategorii pracowników do ich całkowitej liczby. W celu analizy struktury kadrowej określa się i porównuje udział każdej kategorii pracowników dpi w ogólnej średniej liczbie pracowników przedsiębiorstwa T: 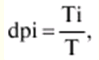 gdzie ti - średnia liczba pracowników kategorii (osoby). Stan ramek jest określany za pomocą współczynników. Stopień ścieralności mkw. (%) to stosunek liczby pracowników zwolnionych z różnych powodów za dany okres Tuv. do średniej liczby pracowników za ten sam okres T: 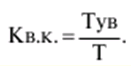 Wskaźnik akceptacji ramek (Kp.k). (%) to stosunek liczby pracowników zatrudnionych na dany okres, oznaczany przez Tp, do średniej liczby zatrudnionych w tym samym okresie, oznaczanej przez T:  Współczynnik stabilności personelu Кс.к. wykorzystywane do oceny poziomu organizacji zarządzania produkcją zarówno w przedsiębiorstwie w poszczególnych działach, jak i jako całości:  gdzie jest Tuw. - liczba pracowników, którzy zrezygnowali z własnej woli oraz z powodu naruszenia dyscypliny pracy za okres sprawozdawczy (osoby); T - średnia liczba pracowników w przedsiębiorstwie w okresie poprzedzającym okres sprawozdawczy (osoby); Tp - liczba nowo zatrudnionych pracowników w okresie sprawozdawczym (osoby). Wskaźnik rotacji personelu (Kt.k.) określa się dzieląc liczbę pracowników przedsiębiorstwa, którzy przeszli na emeryturę lub zwolnili się za dany okres (Tuv.), Przez średnią liczbę za ten sam okres T (%): 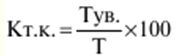 Statystyka siły roboczej bada skład i wielkość siły roboczej. W dziedzinie produkcji materialnej siła robocza dzieli się na personel zajmujący się główną działalnością przedsiębiorstwa oraz personel zajmujący się działalnością niezwiązaną z podstawową działalnością. Główną kategorią personelu są pracownicy. Robotników grupuje się według zawodów, według stopnia mechanizacji pracy oraz według kwalifikacji. Głównym wskaźnikiem kwalifikacji jest kategoria taryfowa lub współczynnik taryfowy. Przeciętny poziom umiejętności określa się na podstawie kategorii średniego wynagrodzenia, obliczonej jako średnia arytmetyczna kategorii, ważona liczbą lub odsetkiem pracowników:  gdzie P - kategorie taryfowe; T - liczba (%) pracowników w danej kategorii. Wszyscy pracownicy są pogrupowani według płci, wieku, doświadczenia zawodowego i wykształcenia. Kategorie liczby pracowników i pracowników obejmują listę płac i liczbę pracowników, liczbę faktycznie pracujących. Zatrudnienie obejmuje wszystkich pracowników przedsiębiorstwa zatrudnionych na okres jednego lub więcej dni. Liczba frekwencji obejmuje pracowników, którzy przybyli do pracy, a także tych, którzy są w delegacjach służbowych i zatrudnieni w innych przedsiębiorstwach na zlecenie ich organizacji. Wszystkie kategorie zatrudnienia określane są na konkretną datę, jednak do wielu obliczeń ekonomicznych konieczna jest znajomość przeciętnej liczby zatrudnionych – przeciętnej listy płac, przeciętnej liczby zatrudnionych oraz średniej faktycznie pracujących. Średnia liczba jest określana w następujący sposób. Załóżmy, że znana jest lista płac na początek i koniec okresu, to średnie zatrudnienie jest określane jako połowa sumy tych wartości. Przeciętne zatrudnienie za kwartał, pół roku i rok określa się jako średnią arytmetyczną ze średnich miesięcznych: T \uXNUMXd Suma średniej miesięcznej liczby pracowników / Liczba miesięcy okresu. Jeżeli stan zatrudnienia jest znany z terminów w regularnych odstępach czasu, na przykład na początku lub na końcu każdego miesiąca, to średnie zatrudnienie za kwartał, pół roku lub rok ustala się według średniego wzoru chronologicznego: 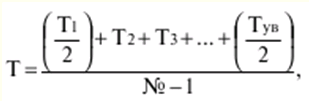 gdzie nr 1 to liczba wskaźników; T1- numer na pierwszą randkę, T2, T3 - na inne terminy. Trzy formuły dają najdokładniejsze wyniki:  Przeciętną liczbę pracowników określa wzór:  Przeciętną liczbę faktycznie zatrudnionych oblicza się według wzoru:  Czas pracy mierzony jest w osobodniach i roboczogodzinach. W statystyce brane są pod uwagę następujące fundusze czasu pracy (w osobodniach). fundusz kalendarzowy - jest to cały czas okresu sprawozdawczego, jest to iloczyn liczby dni kalendarzowych w okresie przez liczbę pracowników. Fundusz personalny jest mniejszy niż fundusz kalendarzowy o liczbę osobodni urlopowych i weekendowych. Maksymalny możliwy fundusz jest mniejszy niż fundusz personalny ze względu na czas następnych wakacji. W rzeczywistości fundusz czasu spędzonego jest mniejszy niż maksymalny możliwy z powodu różnych strat czasu pracy. Wykorzystanie środków czasowych mierzy się następującymi współczynnikami:
Statystyki analizują również wykorzystanie czasu pracy zmianowej, w tym celu stosuje się następujące wskaźniki:  Skorygowany współczynnik przesunięcia = współczynnik ciągłości x współczynnik wykorzystania trybu przesunięcia. Praca przekształca naturalne przedmioty lub surowce w gotowy produkt. Ta zdolność pracy nazywana jest siłą produkcyjną. Wydajność pracy jest miarą sukcesu. Wydajność pracy - jest to efektywność żywej pracy, efektywność działań produkcyjnych w celu stworzenia produktu w czasie. Zadania statystyki wydajności pracy to: 1) doskonalenie metodyki obliczania wydajności pracy; 2) identyfikacja czynników wzrostu wydajności pracy; 3) określenie wpływu wydajności pracy na zmianę produkcji. Wydajność pracy charakteryzuje się wskaźnikami pracochłonności i wydajności. Produkcja (W) produktów na jednostkę czasu jest mierzona stosunkiem wielkości produkcji (q) do kosztu (T) czasu pracy (przeciętne zatrudnienie): 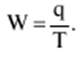 Jest to bezpośredni wskaźnik wydajności pracy. Odwrotnie jest pracochłonność: 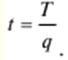 Produkcja pokazuje, ile produkcji jest wytwarzane na jednostkę czasu pracy. System statystycznych wskaźników wydajności pracy określa jednostka miary wielkości produkcji. Jednostki mogą być naturalne, warunkowo naturalne, robocizna i koszt. Wykorzystują naturalne, warunkowo naturalne metody pracy i kosztów do pomiaru poziomu i dynamiki wydajności pracy. W zależności od pomiaru kosztów pracy wyróżnia się następujące poziomy produktywności.  Ten poziom charakteryzuje średnią wydajność pracownika za godzinę pracy rzeczywistej. 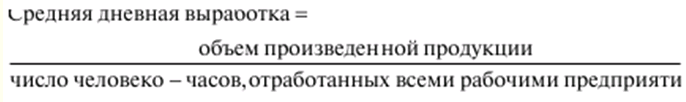 Ten poziom pokazuje stopień wykorzystania produkcyjnego dnia roboczego.  Mianownik odzwierciedla rezerwy pracy. Średnia kwartalna produkcja ustalana jest podobnie jak średnia miesięczna. Przeciętną produkcję charakteryzuje stosunek produktów zbywalnych do średniego zatrudnienia. Istnieje związek między wszystkimi rozważanymi wskaźnikami: W1PPP = Wч × Pr & D × Prp ×dpracownicy в Zapytanie ofertowe gdzie W1nnn - wydajność na pracownika; Wч - średnia wydajność godzinowa; Пr & D - godziny pracy; Пrp - długość godzin pracy; dpracownicy в Zapytanie ofertowe - udział pracowników w ogólnej liczbie personelu przemysłowego i produkcyjnego. W zależności od metody pomiaru poziomu, dynamikę wydajności pracy analizują następujące wskaźniki statystyczne: 1) indeks naturalny: 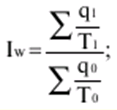 2) wskaźnik pracy: 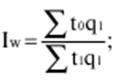 3) indeks akademika S.G. Strumilina: 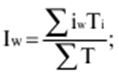 4) indeks wartości:  4. Kapitał stały przedsiębiorstwa Produkcja ma miejsce tylko wtedy, gdy występują dwa czynniki. Po pierwsze, jest to praca - celowa działalność człowieka. Po drugie, są to środki produkcji, które dzielą się na środki pracy (maszyny, narzędzia itp.) i przedmioty pracy (materiały, paliwo, surowce itp.). Za pomocą środków pracy oddziałuje się bezpośrednio na przedmioty pracy - ich wydobycie, gromadzenie, przetwarzanie itp. lub stwarza się warunki zapewniające proces produkcji - są to budynki przemysłowe, konstrukcje itp. Różnica między środkami pracy a przedmiotami pracy polega na tym, że przedmioty pracy są konsumowane w jednym cyklu produkcyjnym, a ich wartość jest całkowicie i raz przeniesiona na produkty, podczas gdy środki pracy zachowują swoją naturalną formę w proces produkcyjny, przenosić ich wartość na produkty w częściach, wielokrotnie, przy każdym cyklu produkcyjnym. Wszystkie środki pracy funkcjonujące w procesie produkcji stanowią środki trwałe. Zatem środki trwałe są środkami pracy, które wpływają na procesy produkcyjne, przedmioty pracy lub zapewniają warunki do realizacji procesu produkcyjnego w przedsiębiorstwie, ale funkcjonując przez długi czas, przenoszą swoją wartość w częściach na tworzone produkty . Skład i struktura środków trwałych Kapitał jest czynnikiem produkcji. Zewnętrznie kapitał wyraża się w określonych formach – są to środki produkcji (kapitał produkcyjny), pieniądz (gotówka), dobra (towar). Część kapitału produkcyjnego (budynki, budowle, maszyny i urządzenia) nazywana jest kapitałem trwałym. Kolejną częścią kapitału produkcyjnego (surowce, materiały, zasoby energetyczne itp.) jest kapitał obrotowy. W rachunkowości występują takie terminy jak „środki trwałe”, „środki trwałe”. W relacjach rynkowych główne miejsce zajmuje problem zwiększenia zdolności produkcyjnych organizacji i efektywności wykorzystania środków trwałych. Od tego, jak skutecznie rozwiązywane są te problemy, zależy miejsce przedsiębiorstwa w produkcji przemysłowej, jego kondycja finansowa oraz konkurencyjność na rynku. Pracownicy przedsiębiorstw w procesie produkcyjnym za pomocą narzędzi pracy wpływają na przedmioty pracy i przekształcają je w różnego rodzaju gotowe produkty. Środki trwałe funkcjonujące w procesie produkcji dzieli się na produkcyjne środki trwałe, do których zalicza się tę część środków trwałych, która uczestniczy w procesie produkcji i kształtowaniu jej wartości, a nieprodukcyjne środki trwałe to środki niezwiązane bezpośrednio z do produkcji materialnej, aw istocie dotyczą sfer służby ludziom pracy, zaspokajania ich potrzeb codziennych i kulturalnych (domy mieszkalne, placówki dziecięce, sportowe i inne). Stały wzrost nieprodukcyjnych środków trwałych wiąże się z poprawą dobrostanu pracowników przedsiębiorstwa oraz wzrostem materialnego i kulturowego poziomu ich życia, co wpływa na wyniki przedsiębiorstwa. Głównymi aktywami produkcyjnymi są materialne i techniczne zaplecze produkcji społecznej. Zdolności produkcyjne przedsiębiorstwa oraz poziom technicznego wyposażenia siły roboczej zależą od wielkości środków trwałych produkcyjnych. Proces pracy jest wzbogacany przez akumulację środków trwałych i wzrost technicznego wyposażenia pracy. Aktywa produkcyjne działające w przemyśle stanowią aktywa produkcji przemysłowej – fundusze te, ze względu na swoją różnorodność, są badane kompleksowo. W celu zbadania wielkości i składu aktywów produkcji przemysłowej grupuje się je według różnych kryteriów - według formy własności, według branży oraz według ich postaci naturalnej. Obecnie aktywa produkcji przemysłowej grupuje się według ich postaci naturalnej zgodnie z klasyfikacją ustaloną w systemie księgowym. Istotą klasyfikacji jest stworzenie możliwości rozłożenia środków trwałych przedsiębiorstw zgodnie z ich przeznaczeniem w procesie produkcyjnym i odzwierciedlającym ich poziom techniczny. Główne aktywa produkcyjne przedsiębiorstw przemysłowych dzielą się na grupy: 1) budynki, budowle; 2) urządzenia transmisyjne; 3) maszynach i urządzeniach - są to maszyny i urządzenia energetyczne, maszyny i urządzenia robocze, przyrządy i urządzenia pomiarowe i regulacyjne oraz sprzęt laboratoryjny, technika komputerowa, inne maszyny i urządzenia; 4) narzędzia i osprzęt, które trwają ponad rok i kosztują ponad 1 milion rubli. kawałek. Narzędzia i sprzęt, które służą mniej niż rok lub kosztują mniej niż 1 milion rubli. na sztukę, traktowane są jako kapitał obrotowy jako małowartościowe i zużywające się; 5) produkcja i inwentaryzacja gospodarstw domowych. Udział poszczególnych grup środków trwałych w ich sumie wolumen reprezentuje specyficzną strukturę środków trwałych. Budynki, budowle, inwentaryzacje, zapewniają funkcjonowanie aktywnych elementów środków trwałych, a więc należą do pasywnej części środków trwałych. Jeżeli udział wyposażenia w kosztach trwałych środków produkcji jest wysoki, to przy niezmiennych pozostałych czynnikach produkcja jest wyższa, a stopa zwrotu z majątku wyższa. Poprawa struktury trwałego majątku produkcyjnego jest warunkiem zwiększenia produkcji i stopy zwrotu z majątku, obniżenia kosztów oraz zwiększenia oszczędności przedsiębiorstw. Czynnikami wpływającymi na strukturę trwałych aktywów produkcyjnych są: charakter produktów, wielkość produkcji, poziom mechanizacji i automatyzacji, poziom kooperacji i specjalizacji, położenie geograficzne organizacji oraz warunki klimatyczne. Wpływ charakteru wytwarzanych produktów znajduje odzwierciedlenie w wielkości i kosztach budynków, udziale pojazdów i urządzeń transmisyjnych. Jeżeli wielkość produkcji jest duża, to wzrasta również udział specjalnych progresywnych maszyn i urządzeń roboczych. Ta sytuacja jest również charakterystyczna dla wpływu trzeciego i czwartego czynnika na strukturę funduszy. Udział budynków i budowli zależy od warunków klimatycznych. Planowanie i rozliczanie środków trwałych produkcyjnych odbywa się w formach naturalnych i pieniężnych. Przy wycenie rzeczowego majątku trwałego ustalana jest liczba maszyn, ich wydajność, wydajność, wielkość powierzchni produkcyjnych i inne różne wartości liczbowe. Takie dane są wykorzystywane do obliczania zdolności produkcyjnych przedsiębiorstw i gałęzi przemysłu, planowania programu produkcyjnego, zwiększania rezerw produkcyjnych na sprzęt i bilansowania sprzętu. Podstawą fizycznego księgowania środków trwałych jest ich paszportyzacja, a także inwentaryzacja, rozliczanie ich przybycia i zbycia. Dla każdej jednostki środków trwałych sporządzany jest paszport, który zawiera charakterystykę produkcyjno-techniczną, co umożliwia pogrupowanie ich według cech technicznych, celu produkcji i według ich stanu. Wycena pieniężna środków trwałych pozwala zaplanować rozszerzoną reprodukcję środków trwałych, określić stopień i wysokość amortyzacji, wielkość prywatyzacji. W praktyce księgowej stosuje się kilka rodzajów wycen środków trwałych, które wiążą się z ich długotrwałym udziałem i stopniowym zużywaniem się w procesie produkcyjnym, zmianami warunków reprodukcji w tym okresie: przy wartości pierwotnej, odtworzeniowej i rezydualnej . Koszt początkowy środków trwałych to suma kosztów pozyskania lub wytworzenia środków, ich montażu i dostawy. Przede wszystkim wycenę środków trwałych przeprowadza się po ich pierwotnym koszcie. Koszt początkowy środków trwałych obejmuje koszty nabycia, transportu, montażu i instalacji środków trwałych, czyli są to wszystkie koszty związane z ich nabyciem i uruchomieniem. Koszt odtworzenia - koszt odtworzenia środków trwałych w warunkach rynkowych. Koszt odtworzenia ustalany jest podczas przeszacowania środków. Wartość rezydualna to różnica między kosztem pierwotnym lub odtworzenia środków trwałych a kwotą ich amortyzacji. Główne aktywa produkcyjne w procesie funkcjonowania zużywają się, przenosząc swoją wartość na wytwarzane produkty. Amortyzacja to wartość pieniężna amortyzacji środków trwałych przeniesionych na produkty. Amortyzacja jest wliczona w koszt wytworzenia. Roczną kwotę odpisów amortyzacyjnych określa wzór: A \uXNUMXd (B - L) / T, gdzie B to całkowity koszt początkowy środków trwałych; L - wartość likwidacyjna środków trwałych pomniejszona o koszty ich demontażu; T to standardowy okres użytkowania środków trwałych; M to szacunkowy koszt modernizacji w całym okresie eksploatacji. Roczne stawki amortyzacji określane są również według następującego wzoru:  Roczne bilanse środków trwałych są zestawiane w celu scharakteryzowania zmiany wielkości i ruchu środków trwałych, ich reprodukcji, na ich podstawie analizuje się procesy ich reprodukcji, bada się dynamikę, wskaźniki odnowienia, zbycia i stanu środków trwałych aktywa są obliczane. Roczna amortyzacja środków trwałych jest równa kwocie amortyzacji naliczonej za dany rok. Źródłami odbioru środków trwałych są: 1) oddanie do eksploatacji nowych środków trwałych; 2) zakup środków trwałych od osób prawnych i osób fizycznych; 3) nieodpłatne odebranie środków trwałych innych osób prawnych i osób fizycznych; 4) dzierżawa środków trwałych. Zbycie może nastąpić w trakcie likwidacji z powodu niszczenia i zużycia, sprzedaży środków trwałych różnym osobom prawnym i osobom fizycznym, nieodpłatnego przekazania, przeniesienia środków trwałych na dzierżawę długoterminową. Na podstawie tych sald można obliczyć szereg wskaźników charakteryzujących stan i reprodukcję środków trwałych: 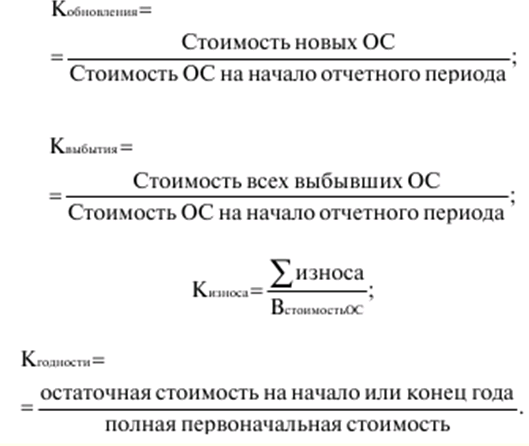 Wskaźniki wykorzystania środków trwałych. zwrot z aktywów:  kapitałochłonność:  stosunek kapitału do pracy:  5. Majątek obrotowy przedsiębiorstwa Kapitał obrotowy - są to środki finansowe zainwestowane w obiekty, których wydatki są realizowane przez przedsiębiorstwo w krótkim okresie kalendarzowym. Pozycje wchodzące w skład kapitału obrotowego obejmują pozycje o okresie użytkowania nie dłuższym niż rok, niezależnie od ich wartości, a także pozycje o wartości poniżej ustalonego limitu nie większej niż 50-krotność minimalnego wynagrodzenia na jednostkę w dniu zakupu , niezależnie od żywotności i kosztów. Skład kapitału obrotowego: 1) zapasy produkcyjne; 2) produkcję w toku i półprodukty; 3) niedokończoną produkcję rolną; 4) pasze i pasze; 5) koszty przyszłych okresów sprawozdawczych; 6) produkty gotowe; 7) towary; 8) inne pozycje inwentarzowe; 9) wysłane towary; 10) gotówka; 11) dłużnicy; 12) krótkoterminowe inwestycje finansowe; 13) inne aktywa obrotowe. W składzie zapasów znajdują się: surowce i materiały, zakupione półprodukty, komponenty, paliwa i smary, paliwo, komponenty itp. Źródłem powstawania elementów kapitału obrotowego są zasoby finansowe. Skład zasobów finansowych obejmuje: fundusze własne (fundusze kapitału docelowego, fundusze specjalne, które powstają kosztem zysku), środki przyciągane (kredyty komercyjne, depozyty, wystawione weksle itp.). Kapitał obrotowy to aktywa, które są w ciągłym ruchu i zamieniają się w gotówkę. Do scharakteryzowania wykorzystania kapitału obrotowego należą trzy wskaźniki szybkości ich obiegu. Wskaźnik rotacji charakteryzuje liczbę obrotów średniego salda kapitału obrotowego produkcji za okres sprawozdawczy:  gdzie P to koszt sprzedanych towarów za dany okres; SO - średni stan kapitału obrotowego, definiowany jako średnia arytmetyczna ze średnich miesięcznych (za kwartał, pół roku, rok) lub jako średnia chronologiczna. Współczynnik wiązania kapitału obrotowego - ta wartość pokazuje, ile potrzebujesz mieć kapitał obrotowy na 1 rubel. koszt sprzedanych produktów. Średni czas trwania jednego obrotu kapitału obrotowego w dniach: 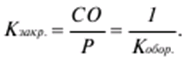 Średni czas trwania jednego obrotu kapitału obrotowego w dniach:  gdzie D to liczba dni w okresie. Obliczane są średnie wskaźniki szybkości obiegu kapitału obrotowego. Wskaźniki rotacji i fiksacji obliczane są jako arytmetyczne średnie ważone: 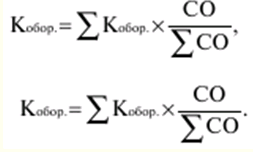 Średni czas trwania jednego obrotu w dniach określa się jako harmoniczną średnią ważoną: 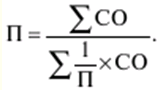 Efekt przyspieszenia obrotu kapitału obrotowego wyraża się kwotą środków warunkowo zwolnionych z obiegu dzięki przyspieszeniu ich obrotu. Wskaźnikiem wykorzystania przedmiotów pracy jest materiałochłonność, która w kategoriach pieniężnych charakteryzuje zużycie zasobów materialnych na jednostkę wyniku produkcji. Wskaźnik zużycia materiału oblicza się według wzoru: 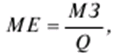 gdzie MZ - koszty produkcji materiałów bez amortyzacji środków trwałych; Q - wielkość produktu społecznego ogółem, dochodu narodowego lub produktów poszczególnych branż i przedsiębiorstw. 6. Studium statystyczne finansów przedsiębiorstw Finanse przedsiębiorstwa - są to relacje wyrażone w formie pieniężnej, które powstają przy tworzeniu, dystrybucji i wykorzystaniu środków pieniężnych i oszczędności w procesie produkcji i sprzedaży towarów, wykonywania pracy i świadczenia różnych usług. Ilościowa charakterystyka stosunków finansowych i monetarnych wraz z ich cechami jakościowymi, ze względu na tworzenie, dystrybucję i wykorzystanie zasobów finansowych, wypełnianie zobowiązań podmiotów gospodarczych wobec siebie, systemu finansowo-bankowego i państwa, jest przedmiot studiów statystyki finansowej. Główne zadania statystyki finansowej: 1) badanie stanu i rozwoju stosunków finansowych i pieniężnych podmiotów gospodarczych; 2) analiza wielkości i struktury źródeł tworzenia środków finansowych; 3) określić kierunek wykorzystania środków; 4) analizować poziom i dynamikę zysków, rentowność przedsiębiorstwa; 5) ocenia stabilność finansową i wypłacalność; 6) ocenia wykonanie przez podmioty gospodarcze zobowiązań finansowych i kredytowych. Zasoby finansowe - są to środki własne i pożyczone podmiotów gospodarczych będące w ich dyspozycji i przeznaczone na wypełnienie zobowiązań finansowych i poniesienie kosztów produkcji. Wielkość i struktura zasobów finansowych jest powiązana z poziomem rozwoju przedsiębiorstwa i jego efektywnością. Jeśli przedsiębiorstwo odnosi sukces, to wielkość jego dochodów pieniężnych jest wysoka. Tworzenie środków finansowych następuje w momencie tworzenia funduszu statutowego. Źródłami kapitału docelowego są: 1) kapitał zakładowy; 2) udział wkładów członków spółdzielni; 3) kredyt długoterminowy; 4) środki budżetowe. W przedsiębiorstwach o ugruntowanej pozycji w gospodarce rynkowej źródłami środków finansowych są: 1) zysk ze sprzedanych produktów, wykonanych prac lub świadczonych usług; 2) odpisy amortyzacyjne, wpływy ze sprzedaży akcji, papierów wartościowych; 3) pożyczki krótkoterminowe i długoterminowe; 4) dochody ze sprzedaży nieruchomości itp. Zysk charakteryzuje końcowe wyniki działalności handlowej i produkcyjnej. Zysk jest głównym wskaźnikiem kondycji finansowej przedsiębiorstwa. W statystykach finansów przedsiębiorstw wyróżnia się następujące rodzaje zysku: 1) zysk bilansowy; 2) zysk ze sprzedaży produktów (robót, usług); 3) zysk brutto; 4) zysk netto. zysk bilansowy - jest to zysk uzyskany w wyniku sprzedaży produktów środków trwałych i innego majątku podmiotów gospodarczych, a także dochód pomniejszony o straty z działalności niesprzedażowej. Zysk ze sprzedaży produktów obliczany jest jako różnica pomiędzy wpływami ze sprzedaży produktów a kosztami wytworzenia i sprzedaży, uwzględnionymi w koszcie wytworzenia. Zysk brutto w ramach przychodów i strat pozaoperacyjnych uwzględnia zapłacone kary i grzywny. Same przedsiębiorstwa określają kierunki, wielkość i charakter wykorzystania zysku netto. Kosztem zysku netto tworzy się fundusz rozwoju produkcji, fundusz akumulacyjny, fundusz rozwoju społecznego oraz fundusz zachęt rzeczowych, fundusz rezerwowy. Wskaźniki rentowności 1. Ogólna rentowność: 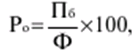 gdzie pб - całkowity zysk bilansowy; F - średni roczny koszt środków trwałych i znormalizowanego kapitału obrotowego. 2. Rentowność sprzedanych produktów: 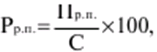 gdzie p r.p. - zysk ze sprzedaży produktów; C to całkowity koszt sprzedanych towarów. Wskaźniki działalności gospodarczej przedsiębiorstwa Działalność gospodarczą przedsiębiorstwa określa się za pomocą wskaźnika całkowitego obrotu kapitałowego:  gdzie B to wpływy ze sprzedaży produktów; K - główny kapitał przedsiębiorstwa. Analiza stabilności finansowej przedsiębiorstwa jest bardzo ważna w gospodarce rynkowej. Stabilność finansowa - jest to zdolność podmiotu gospodarczego do terminowego zwrotu z własnych środków kosztów zainwestowanych w środki trwałe i obrotowe, wartości niematerialne i prawne oraz spłaty swoich zobowiązań, czyli do bycia wypłacalnym. Do oceny pomiaru stabilności stosuje się współczynniki. 1. Współczynnik autonomii: 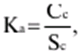 gdzie Cс - fundusze własne; Sс - suma wszystkich źródeł środków finansowych. 2. Współczynnik stabilności: 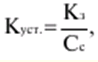 gdzie Kз - Zobowiązania i inne pożyczone środki. 3. Czynnik zwinności: Km = (Cс + DKZ - OSt..) / Zс, gdzie DKZ - długoterminowe kredyty i pożyczki; Osv. - środki trwałe i inne aktywa trwałe. 4. Wskaźnik płynności: 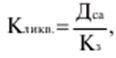 gdzie Dsa - środki ulokowane w papiery wartościowe, zapasy, należności; KZ - dług krótkoterminowy. WYKŁAD №9. Analiza dynamiczna 1. Dynamika zjawisk społeczno-gospodarczych i zadania jej badań statystycznych Zjawiska życia społecznego badane przez statystyki społeczno-ekonomiczne podlegają ciągłym zmianom i rozwojowi. Z biegiem czasu - z miesiąca na miesiąc, z roku na rok - zmienia się populacja i jej skład, wielkość produkcji, poziom wydajności pracy itp. Dlatego jednym z najważniejszych zadań statystyki jest badanie zmian zjawiska społeczne w czasie – proces ich rozwoju, ich dynamika. Statystyka rozwiązuje ten problem poprzez konstruowanie i analizowanie szeregów czasowych (szeregów czasowych). Zakres dynamiki (chronologiczne, dynamiczne, szeregi czasowe) to ciąg uporządkowanych w czasie wskaźników liczbowych, charakteryzujących poziom rozwoju badanego zjawiska. Seria zawiera dwa obowiązkowe elementy: czas i konkretną wartość wskaźnika (poziom serii). Każda wartość liczbowa wskaźnika, charakteryzująca wielkość, wielkość zjawiska, nazywana jest poziomem szeregu. Oprócz poziomów każda seria dynamiki zawiera wskazania tych momentów lub okresów czasu, do których odnoszą się poziomy. Podsumowując wyniki obserwacji statystycznych, uzyskuje się wskaźniki bezwzględne dwóch typów. Niektóre z nich charakteryzują stan zjawiska w pewnym momencie: obecność w tym momencie dowolnych jednostek populacji lub obecność jednej lub drugiej objętości cechy. Do takich wskaźników zalicza się populację, flotę samochodową, zasoby mieszkaniowe, inwentarze itp. Wartość takich wskaźników można określić bezpośrednio tylko na określony punkt w czasie, dlatego wskaźniki te i odpowiadające im szeregi czasowe nazywamy chwilowymi. Inne wskaźniki charakteryzują wyniki dowolnego procesu przez pewien okres (przedział) czasu (dzień, miesiąc, kwartał, rok itp.). Takimi wskaźnikami są na przykład liczba urodzeń, liczba wyprodukowanych produktów, oddanie do użytku budynków mieszkalnych, fundusz płac itp. Wartość tych wskaźników można obliczyć tylko dla pewnego przedziału (okresu) czasu. Dlatego takie wskaźniki i serie ich wartości nazywane są interwałami. Niektóre cechy (właściwości) poziomów odpowiadających im szeregów czasowych wynikają z odmiennego charakteru wskaźników bezwzględnych interwału i momentu. W szeregu przedziałowym wartość poziomu, który jest wynikiem dowolnego procesu dla określonego przedziału (okresu) czasu, zależy od długości tego okresu (długości przedziału). Gdy inne rzeczy są równe, poziom szeregu przedziałowego jest tym większy, im dłuższa jest długość przedziału, do którego należy ten poziom. W przypadku szeregów dynamiki chwilowej, gdzie występują również interwały (przedziały czasowe pomiędzy sąsiadującymi datami w szeregu), wartość danego poziomu nie zależy od długości okresu pomiędzy sąsiadującymi datami. Każdy poziom szeregu interwałowego jest już sumą poziomów dla krótszych okresów czasu. W tym przypadku jednostka populacji, która jest częścią jednego poziomu, nie jest uwzględniana na innych poziomach. Zatem w interwałowym szeregu dynamiki można sumować poziomy dla sąsiednich okresów, uzyskując wyniki (poziomy) dla dłuższych okresów (czyli sumując poziomy miesięczne, otrzymujemy poziomy kwartalne, sumując poziomy kwartalne - otrzymujemy roczne, sumując roczne - długoterminowe). Niekiedy poprzez sekwencyjne dodawanie poziomów szeregu przedziałów dla sąsiednich przedziałów czasowych konstruuje się serię sum skumulowanych, w których każdy poziom reprezentuje sumę nie tylko dla danego okresu, ale także dla innych okresów, począwszy od określonej daty (od początek roku itp.). Takie skumulowane wyniki są często podawane w sprawozdaniach księgowych i innych sprawozdaniach przedsiębiorstw. W szeregu czasowym chwili te same jednostki populacji są zwykle zawarte na kilku poziomach. Dlatego sumowanie poziomów momentów szeregów dynamiki samo w sobie nie ma sensu, gdyż uzyskane w tym przypadku wyniki pozbawione są niezależnego znaczenia ekonomicznego. Powyżej mówiliśmy o szeregu dynamik wartości bezwzględnych, które są początkowe, pierwotne. Wraz z nimi można konstruować szeregi dynamiki, których poziomy są wartościami względnymi i średnimi. Mogą być również chwilowe lub interwałowe. W serii przedziałów dynamiki wartości względnych i średnich bezpośrednie sumowanie poziomów samo w sobie jest bez znaczenia, ponieważ wartości względne i średnie są pochodnymi i są obliczane przez podzielenie innych wartości. Konstruując i przed analizą szeregów dynamicznych należy przede wszystkim zwrócić uwagę na to, że poziomy szeregu są ze sobą porównywalne, gdyż tylko w tym przypadku szereg dynamiczny będzie prawidłowo odzwierciedlał rozwój zjawiska . Porównywalność poziomów szeregu dynamiki - jest to najważniejszy warunek słuszności i poprawności wniosków uzyskanych w wyniku analizy tego szeregu. Konstruując szeregi czasowe należy pamiętać, że szeregi te mogą obejmować duży okres czasu, w którym mogą wystąpić zmiany naruszające porównywalność (zmiany terytorialne, zmiany w zakresie obiektów, metodologii obliczeń itp.). Podczas badania dynamiki zjawisk społecznych statystyka rozwiązuje następujące zadania: 1) mierzy bezwzględną i względną stopę wzrostu lub spadku poziomu dla poszczególnych okresów; 2) podaje ogólną charakterystykę poziomu i tempa jego zmiany za dany okres; 3) ujawnia i liczbowo charakteryzuje główne kierunki rozwoju zjawisk na poszczególnych etapach; 4) podaje porównawczy liczbowy opis rozwoju tego zjawiska w różnych regionach lub na różnych etapach; 5) ujawnia czynniki powodujące zmianę badanego zjawiska w czasie; 6) sporządza prognozy rozwoju zjawiska w przyszłości. 2. Kluczowe wskaźniki szeregów czasowych Podczas badania dynamiki stosuje się różne wskaźniki i metody analizy, zarówno elementarne, prostsze, jak i bardziej złożone, wymagające użycia bardziej złożonych sekcji matematyki. Najprostszymi wskaźnikami analizy, które są wykorzystywane przy rozwiązywaniu szeregu problemów (przede wszystkim przy pomiarze tempa zmiany poziomu szeregu dynamiki) są wzrost bezwzględny, wzrost i stopy wzrostu, a także wartość bezwzględna (zawartość) 1% wzrostu. Obliczenie tych wskaźników opiera się na porównaniu ze sobą poziomów szeregu dynamiki. Jednocześnie poziom, z którym dokonuje się porównania, nazywany jest poziomem podstawowym, ponieważ jest to podstawa porównania. Zwykle jako podstawę porównania przyjmuje się albo poprzedni poziom, albo jakiś poprzedni poziom, na przykład pierwszy poziom serii. Jeśli każdy poziom jest porównywany z poprzednim, to wskaźniki uzyskane w tym przypadku nazywane są wskaźnikami łańcuchowymi, ponieważ są one jakby ogniwami w łańcuchu łączącym poziomy serii. Jeśli wszystkie poziomy są powiązane z tym samym poziomem, który działa jako stała baza porównawcza, wówczas wskaźniki uzyskane w tym przypadku nazywane są podstawowymi. Często konstruowanie szeregu dynamiki zaczyna się od poziomu, który będzie służył jako stała baza porównawcza. Wybór tej bazy powinien być uzasadniony historycznymi i społeczno-ekonomicznymi cechami rozwoju badanego zjawiska. Celowe jest przyjęcie pewnego charakterystycznego, typowego poziomu jako poziomu podstawowego, na przykład końcowego poziomu poprzedniego etapu rozwoju (lub jego średniego poziomu, jeśli na poprzednim etapie poziom wzrósł lub obniżył się). Wzrost absolutny pokazuje, o ile jednostek poziom wzrósł (lub spadł) w porównaniu do wartości bazowej, tj. dla określonego okresu (okresu) czasu. Bezwzględny wzrost jest równy różnicy między porównywanymi poziomami i jest mierzony w tych samych jednostkach, co te poziomy: Δ=yi −yi-1, Δ=yi −y0, gdzie tyi - poziom i-tego roku; yi-1 - poziom z poprzedniego roku; y0 - poziom roku bazowego. Spadek poziomu w stosunku do bazy charakteryzuje bezwzględny spadek poziomu. Wzrost bezwzględny na jednostkę czasu (miesiąc, rok) mierzy bezwzględną stopę wzrostu (lub spadku) poziomu. Wzrosty łańcuchowe i podstawowe bezwzględne są ze sobą powiązane: suma kolejnych wzrostów łańcuchowych jest równa odpowiadającemu wzrostowi podstawowemu, tj. wzrostowi całkowitemu za cały okres. Pełniejszą charakterystykę wzrostu można uzyskać tylko wtedy, gdy wartości bezwzględne uzupełni się wartościami względnymi. Względnymi wskaźnikami dynamiki są tempa wzrostu oraz tempa wzrostu charakteryzujące intensywność procesu wzrostu. Tempo wzrostu (Tр) - wskaźnik statystyczny odzwierciedlający intensywność zmian poziomów szeregu dynamiki i pokazujący, ile razy poziom wzrósł w stosunku do poziomu bazowego, aw przypadku spadku, jaką część poziomu bazowego stanowi poziom porównywany. Mierzona stosunkiem obecnego poziomu do poprzedniego lub bazowego:  Podobnie jak inne wartości względne, tempo wzrostu można wyrazić nie tylko w postaci współczynnika (prostego stosunku poziomów), ale także w procentach. Podobnie jak bezwzględne stopy wzrostu, stopy wzrostu dla dowolnych szeregów czasowych są same w sobie wskaźnikami przedziałów, tj. charakteryzują jeden lub inny okres (przedział) czasu. Istnieje pewna zależność między tempem wzrostu łańcuchowego a tempem bazowym, wyrażona w postaci współczynników: iloczyn kolejnych tempa wzrostu łańcucha jest równy tempu wzrostu bazowego dla całego odpowiedniego okresu. Na przykład: 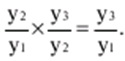 Tempo wzrostu (Tпр) charakteryzuje względną wartość wzrostu, tj. jest to stosunek bezwzględnego wzrostu do poprzedniego lub bazowego poziomu.  Wyrażona w procentach stopa wzrostu pokazuje, o ile procent poziom wzrósł (lub spadł) w porównaniu z wartością bazową, przyjętą jako 100%. Analizując tempo rozwoju, nigdy nie należy tracić z oczu tego, jakie wartości bezwzględne – poziomy i bezwzględne przyrosty – kryją się za tempami wzrostu i wzrostu. W szczególności należy mieć na uwadze, że wraz ze spadkiem (wyhamowaniem) tempa wzrostu i tempa wzrostu, wzrost bezwzględny może wzrosnąć. W związku z tym ważne jest zbadanie innego wskaźnika dynamiki - wartości bezwzględnej (zawartości) 1% (jeden procent) wzrostu, która jest określana jako wynik podzielenia wzrostu bezwzględnego przez odpowiednią stopę wzrostu: 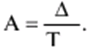 Ta wartość pokazuje, ile w wartościach bezwzględnych daje każdy procent wzrostu. Niekiedy poziomy zjawiska dla jednego roku nie są porównywalne z poziomami dla innych lat ze względu na zmiany terytorialne, resortowe i inne (zmiany w metodyce rozliczania i obliczania wskaźników itp.). Aby zapewnić porównywalność i uzyskać szereg czasowy odpowiedni do analizy, konieczne jest bezpośrednie przeliczenie poziomów nieporównywalnych z innymi. Czasami jednak wymagane do tego dane nie są dostępne. W takich przypadkach można użyć specjalnej techniki zwanej zamknięciem serii dynamiki. Niech na przykład nastąpiła zmiana granic terytorium, na którym w i-tym roku badano dynamikę rozwoju jakiegoś zjawiska. Wówczas dane uzyskane przed tym rokiem nie będą porównywalne z danymi za kolejne lata. Aby zamknąć te szeregi i móc analizować dynamikę szeregu dla całego okresu, w każdym z nich jako bazę porównawczą przyjmiemy poziom i-tego roku, dla którego istnieją dane zarówno w stare i nowe granice terytorium. Te dwa wiersze o tej samej podstawie porównania można następnie zastąpić jednym zamkniętym wierszem dynamiki. Z danych tak zamkniętego szeregu można obliczyć tempo wzrostu w porównaniu z dowolnym rokiem. Możesz również obliczyć poziomy bezwzględne dla całego okresu w nowych granicach. Trzeba oczywiście mieć na uwadze, że wyniki uzyskane przez zamknięcie szeregu dynamiki zawierają pewien błąd. Graficznie dynamikę zjawisk przedstawia się najczęściej w postaci wykresów słupkowych i liniowych. Stosowane są również inne formy wykresów - krzywe, kwadratowe, sektorowe itp. Wykresy analityczne są zwykle budowane w formie wykresów liniowych. 3. Średnia dynamika Z biegiem czasu zmieniają się nie tylko poziomy zjawisk, ale także wskaźniki ich dynamiki – bezwzględne tempo wzrostu i rozwoju. Dlatego do uogólnienia charakterystyki rozwoju, do identyfikacji i pomiaru typowych głównych trendów i wzorców oraz do rozwiązywania innych problemów analizy stosuje się średnie wskaźniki szeregów czasowych - średnie poziomy, średni bezwzględny wzrost i średnie wskaźniki dynamiki. Często konieczne jest uciekanie się do obliczania średnich poziomów szeregu dynamiki już przy konstruowaniu szeregu czasowego - aby zapewnić porównywalność licznika i mianownika przy obliczaniu wartości średnich i względnych. Niech, na przykład, trzeba zbudować szereg dynamiki produkcji energii elektrycznej na mieszkańca w Federacji Rosyjskiej. Aby to zrobić, dla każdego roku konieczne jest podzielenie ilości energii elektrycznej wyprodukowanej w tym roku (wskaźnik interwałowy) przez liczbę ludności w tym samym roku (wskaźnik natychmiastowy, którego wartość zmienia się w sposób ciągły w ciągu roku). Oczywiste jest, że wielkość populacji w pewnym momencie w ogólnym przypadku nie jest porównywalna z wielkością produkcji w całym roku. Aby zapewnić porównywalność, trzeba też jakoś datować populację na cały rok, a to można zrobić tylko przez obliczenie średniej liczby ludności dla roku. Często konieczne jest uciekanie się do średnich wskaźników dynamiki także dlatego, że poziomy wielu zjawisk ulegają dużym wahaniom z okresu na okres, na przykład z roku na rok, rosnąc lub malejąc. Dotyczy to zwłaszcza wielu wskaźników rolnictwa, gdzie z roku na rok nie spada. Dlatego też, analizując rozwój rolnictwa, często operują nie wskaźnikami rocznymi, ale bardziej typowymi i stabilnymi wskaźnikami średniorocznymi od kilku lat. Przy obliczaniu średnich wskaźników dynamiki należy pamiętać, że ogólne przepisy teorii średnich mają w pełni zastosowanie do tych średnich. Oznacza to przede wszystkim, że średnia dynamiczna będzie typowa, jeżeli charakteryzuje okres o jednorodnych, mniej lub bardziej stabilnych warunkach rozwoju zjawiska. Podział takich okresów – etapów rozwoju – jest w pewnym sensie analogiczny do grupowania. Jeżeli średnią dynamiczną oblicza się dla okresu, w którym znacząco zmieniły się warunki rozwoju zjawiska, tj. okresu obejmującego różne etapy rozwoju zjawiska, to taką średnią należy stosować z dużą ostrożnością, uzupełniając ją o średnie dla poszczególnych etapów. Średnie wskaźniki dynamiki muszą również spełniać wymóg logiczny i matematyczny, zgodnie z którym przy zastępowaniu rzeczywistych wartości, z których obliczana jest średnia, wartość wskaźnika definiującego, tj. jakiegoś wskaźnika uogólniającego związanego ze wskaźnikiem uśrednionym, nie powinno się zmieniać. Sposób obliczania średniego poziomu szeregu dynamiki zależy przede wszystkim od charakteru wskaźnika będącego podstawą szeregu, tj. od rodzaju szeregu czasowego. Najprostszym sposobem obliczenia jest średni poziom szeregu interwałowego dynamiki wartości bezwzględnych o równych poziomach. Obliczenia dokonuje się według wzoru prostej średniej arytmetycznej: 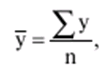 gdzie n to liczba rzeczywistych poziomów dla kolejnych równych przedziałów czasu. Sytuację komplikuje obliczenie średniego poziomu szeregu momentów dynamiki wartości bezwzględnych. Wskaźnik momentu może się zmieniać niemal w sposób ciągły. Dlatego oczywiste jest, że im bardziej szczegółowe i wyczerpujące mamy dane na temat jego zmiany, tym dokładniej możemy obliczyć średni poziom. Ponadto sama metoda obliczeń zależy od szczegółowości dostępnych danych. Możliwe są tutaj różne przypadki. Jeżeli istnieją obszerne dane dotyczące wskaźnika zmiany momentu, jego średni poziom oblicza się według wzoru na arytmetyczną średnią ważoną dla szeregu przedziałowego o różnych poziomach:  gdzie t jest liczbą okresów, w których poziom się nie zmienił. Jeżeli odstępy czasu między sąsiadującymi datami są sobie równe, czyli gdy mamy do czynienia z równymi (lub w przybliżeniu równymi) odstępami między datami (np. gdy znane są poziomy na początku każdego miesiąca lub kwartału, roku), to dla seria natychmiastowa o równych poziomach, średni poziom serii obliczamy za pomocą wzoru na średnią chronologiczną: 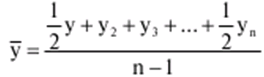 W przypadku serii instant o różnych poziomach średni poziom serii jest obliczany za pomocą wzoru: 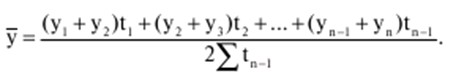 Powyżej mówiliśmy o średnim poziomie szeregu dynamiki wartości bezwzględnych. W przypadku szeregu dynamiki wartości średnich i względnych średni poziom należy obliczyć na podstawie zawartości i znaczenia tych wskaźników średnich i względnych. Średni wzrost bezwzględny pokazuje, o ile jednostek poziom wzrósł lub spadł w porównaniu do poprzedniego średnio na jednostkę czasu (średnio miesięcznie, rocznie itp.). Średni wzrost bezwzględny charakteryzuje średnią bezwzględną stopę wzrostu (lub spadku) poziomu i jest zawsze wskaźnikiem przedziału. Oblicza się go, dzieląc całkowity wzrost za cały okres przez długość tego okresu w różnych jednostkach czasu: 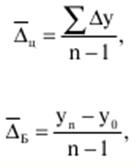 gdzie Δ - bezwzględne przyrosty łańcucha dla kolejnych okresów czasu; n to liczba przyrostów łańcucha; у0 - poziom okresu bazowego. Jako podstawę i kryterium poprawności obliczenia średniego tempa wzrostu (a także średniego przyrostu bezwzględnego) można przyjąć iloczyn łańcuchowych temp wzrostu, który jest równy tempu wzrostu dla całego rozpatrywanego okresu, jako określający wskaźnik. Zatem mnożąc n tempa wzrostu łańcucha, otrzymujemy tempo wzrostu dla całego okresu:  Należy przestrzegać równości:  Ta równość reprezentuje wzór na prostą średnią geometryczną Z tej równości wynika: 
gdzie n jest liczbą poziomów szeregu dynamicznego; Т1, T2, Tп - wskaźniki wzrostu łańcucha. Średnia stopa wzrostu, wyrażona w postaci współczynnika, pokazuje, ile razy poziom wzrósł w stosunku do poprzedniego średnio w jednostce czasu (średnio rocznie, miesięcznie itp.). W przypadku średniego wzrostu i tempa wzrostu zachodzi ta sama zależność, która zachodzi między normalnym wzrostem a tempem wzrostu:  Średnia stopa wzrostu (lub spadku), wyrażona w procentach, pokazuje, o ile procent poziom wzrósł (lub spadł) w porównaniu do poprzedniego średnio w jednostce czasu (średnio rocznie, miesięcznie itp.). Średnia stopa wzrostu charakteryzuje średnią intensywność wzrostu, tj. średnią względną stopę zmiany poziomu. Spośród dwóch rodzajów formuły średniego tempa wzrostu, drugi jest częściej używany, ponieważ nie wymaga obliczania wszystkich tempa wzrostu łańcucha. Zgodnie z pierwszą formułą, zaleca się obliczanie tylko w przypadkach, gdy nie są znane ani poziomy szeregu dynamiki, ani tempo wzrostu dla całego okresu, a znane są tylko tempo wzrostu łańcucha (lub wzrostu). 4. Identyfikacja i charakterystyka głównego trendu rozwojowego Jednym z zadań pojawiających się przy analizie szeregów czasowych jest ustalenie wzorców zmian poziomów badanego wskaźnika w czasie. W tym celu konieczne jest wyodrębnienie takich okresów (etapów) rozwoju, które są wystarczająco jednorodne w stosunku do relacji tego zjawiska z innymi oraz w odniesieniu do warunków jego rozwoju. Identyfikacja etapów rozwoju to zadanie z pogranicza nauki badającej to zjawisko (ekonomia, socjologia itp.) i statystyki. Rozwiązanie tego problemu dokonuje się nie tylko i nawet nie tyle metodami statystycznymi (choć mogą one przynieść pewną korzyść), ale na podstawie sensownej analizy istoty, natury zjawiska i ogólnej prawa jej rozwoju. Dla każdego etapu rozwoju konieczne jest zidentyfikowanie i liczbowe scharakteryzowanie głównego trendu zmiany poziomu zjawiska. Przez trend rozumie się ogólny kierunek wzrostu, spadku lub stabilizacji poziomu zjawiska w czasie. Jeśli poziom stale rośnie lub stale spada, to trend wzrostowy lub spadkowy jest wyraźny i wyraźny: można go łatwo wykryć wizualnie na wykresie szeregów czasowych. Należy jednak pamiętać, że zarówno wzrost, jak i spadek poziomu może następować na różne sposoby: równomiernie, przyspieszenie lub spowolnienie. Jednolity wzrost (lub spadek) oznacza tutaj wzrost (spadek) w stałym tempie bezwzględnym, gdy bezwzględne przyrosty łańcucha (4) są takie same. Przy przyspieszonym wzroście lub spadku przyrosty łańcucha systematycznie rosną w wartości bezwzględnej, a przy powolnym wzroście lub spadku maleją (również w wartości bezwzględnej). W praktyce poziomy szeregu dynamiki bardzo rzadko rosną (lub maleją) ściśle równomiernie. Nierzadko występuje również systematyczny – bez ani jednego odchylenia – wzrost lub spadek przyrostów łańcucha. Takie odchylenia tłumaczy się albo zmianą w czasie całego zespołu głównych przyczyn i czynników, od których zależy poziom zjawiska, albo zmianą kierunku i siły działania wtórnego (w tym losowego) okoliczności i czynniki. Dlatego analizując dynamikę, mówimy nie tylko o trendzie rozwojowym, ale o głównym trendzie, który jest dość stabilny (zrównoważony) przez cały ten etap rozwoju. W niektórych przypadkach ta prawidłowość, ogólna tendencja w rozwoju obiektu, jest dość wyraźnie pokazana przez poziomy szeregu dynamicznego. główny trend (trend) nazywa się wystarczająco płynną i stabilną zmianą poziomu zjawiska w czasie, mniej lub bardziej wolną od przypadkowych fluktuacji. Główny trend można przedstawić analitycznie - w postaci równania modelu trendu) lub graficznie. Identyfikacja głównego trendu (trendu) rozwojowego nazywana jest również w statystyce wyrównaniem szeregów czasowych, a metody identyfikacji głównego trendu nazywane są metodami wyrównania. Jednym z najczęstszych sposobów identyfikacji głównych trendów (trendów) serii dynamiki są: 1) sposób powiększania interwałów; 2) metoda średniej ruchomej (istotą metody jest zastąpienie danych bezwzględnych średnimi arytmetycznymi za określone okresy). Obliczenie średnich odbywa się metodą ślizgową, czyli stopniowe wyłączanie z przyjętego okresu pierwszego poziomu i włączanie następnego; 3) analityczna metoda dopasowania. W tym przypadku poziomy szeregu dynamiki są wyrażone jako funkcje czasu: a) f(t)= a0+ ajt- zależność liniowa; b) f(t) = a0 + cijt + a2t2- zależność paraboliczna. Metoda powiększania interwałów i ich charakterystyki o poziomy średnie polega na przechodzeniu od interwałów krótszych do dłuższych, np. odstępy czasowe. Jeżeli poziomy szeregu dynamiki zmieniają się z mniej lub bardziej określoną okresowością (falową), wówczas wskazane jest przyjęcie powiększonego przedziału równego okresowi oscylacji (długości „fali” cyklu). Jeśli takiej okresowości nie ma, to powiększanie odbywa się stopniowo od małych interwałów do coraz większych, aż ogólny kierunek trendu stanie się wystarczająco wyraźny. Jeżeli szereg dynamiki jest chwilowy, a także w przypadkach, gdy poziom szeregu jest wartością względną lub średnią, sumowanie poziomów nie ma sensu, a zagregowane okresy powinny charakteryzować się poziomami średnimi. Gdy interwały są powiększone, liczba członków szeregu dynamicznego jest znacznie zmniejszona, w wyniku czego ruch poziomy w powiększonym interwale znika z pola widzenia. W związku z tym, aby zidentyfikować główny trend i jego bardziej szczegółowe cechy, szereg wygładza się za pomocą średniej ruchomej. Wygładzanie serii dynamiki za pomocą średniej ruchomej polega na obliczeniu średniego poziomu z pewnej liczby pierwszych poziomów w szeregu, następnie średniego poziomu z tej samej liczby poziomów, zaczynając od drugiego, następnie zaczynając od trzeciego i itd. Tak więc przy obliczaniu średniego poziomu zdają się przesuwać szereg czasowy od jego początku do końca, za każdym razem odrzucając jeden poziom na początku i dodając kolejny. Stąd nazwa - średnia ruchoma. Każde ogniwo średniej ruchomej to średni poziom dla odpowiedniego okresu. W przedstawieniu graficznym i przy niektórych obliczeniach każde łącze jest umownie odnoszone do centralnego przedziału okresu, dla którego wykonano obliczenia (dla serii chwilowych, do daty centralnej). Pytanie, za jaki okres należy obliczyć powiązania średniej ruchomej, zależy od specyfiki dynamiki. Podobnie jak w przypadku powiększania przedziałów, jeśli występuje pewna okresowość wahań poziomu, wówczas wskazane jest przyjęcie okresu wygładzania równego okresowi oscylacji lub wielokrotności jego wartości. Tak więc w przypadku kwartalnych poziomów, na których występują sezonowe spadki i wzrosty w ciągu roku, zaleca się stosowanie średniej z czterech lub ośmiu kwartałów itd. Jeśli wahania poziomu są niekonsekwentne, zaleca się stopniowe zwiększanie interwału wygładzania do pojawia się wyraźny wzorzec trendu. Analityczne dopasowanie szeregów czasowych pozwala uzyskać analityczny model trendu. Jest produkowany w następujący sposób. 1. Na podstawie miarodajnej analizy wyodrębnia się etap rozwoju i ustala charakter dynamiki na tym etapie. 2. Opierając się na założeniu takiego lub innego wzorca wzrostu i natury dynamiki, wybiera się formę analitycznego wyrażenia trendu, rodzaj funkcji aproksymującej, która graficznie odpowiada określonej linii - linii prostej , parabola, krzywa wykładnicza itp. Ta linia (funkcja) wyraża oczekiwaną płynną zmianę poziomu w czasie, czyli główny trend. W tym przypadku każdy poziom szeregu dynamiki jest warunkowo traktowany jako suma dwóch składowych (składowych): yt = f(t) + ε. Jeden z nich (yt = f(t)), która wyraża trend, charakteryzuje wpływ stałych czynników głównych i nazywana jest składową regularną systematyczną. Kolejny składnik (е!) odzwierciedla wpływ czynników i okoliczności losowych i nazywana jest składową losową. Składnik ten jest również nazywany rezydualnym (lub po prostu rezydualnym), ponieważ jest równy odchyleniu rzeczywistego poziomu od trendu. Przyjmuje się więc (warunkowo zakłada się), że główny trend (trend) kształtuje się pod wpływem stale działających czynników głównych, a drugorzędne, losowe czynniki powodują odchylenie poziomu od trendu. Wybór kształtu krzywej w dużej mierze determinuje wyniki ekstrapolacji trendu. Podstawą wyboru typu krzywej może być sensowna analiza istoty rozwoju tego zjawiska. Można też polegać na wynikach wcześniejszych badań w tym zakresie. Najprostszą techniką empiryczną jest technika wizualna: wybór formy trendu w oparciu o graficzną reprezentację szeregu – linię przerywaną. W praktyce zależność liniowa jest stosowana częściej niż paraboliczna ze względu na swoją prostotę. Autor: Konik N.V.
▪ Literatura rosyjska XX wieku w skrócie. Kołyska
Maszyna do przerzedzania kwiatów w ogrodach
02.05.2024 Zaawansowany mikroskop na podczerwień
02.05.2024 Pułapka powietrzna na owady
01.05.2024
▪ sekcja serwisu Zagadki dla dorosłych i dzieci. Wybór artykułów ▪ artykuł Dwulicowy Janus. Popularne wyrażenie ▪ artykuł Czytelnik modlitwy. Legendy, uprawa, metody aplikacji ▪ artykuł Elastyczny wosk uszczelniający. Proste przepisy i porady ▪ podwyższający stabilizator napięcia AC. Encyklopedia elektroniki radiowej i elektrotechniki
Strona główna | biblioteka | Artykuły | Mapa stony | Recenzje witryn
www.diagram.com.ua |


 - odsetek jednostek populacji ogólnej, które nie zostały uwzględnione w próbie.
- odsetek jednostek populacji ogólnej, które nie zostały uwzględnione w próbie.


 Zobacz inne artykuły Sekcja
Zobacz inne artykuły Sekcja 