|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Notatki z wykładów, ściągawki
Baza danych. Notatki z wykładu: krótko, najważniejsze
Katalog / Notatki z wykładów, ściągawki Spis treści
Wykład nr 1. Wprowadzenie 1. Systemy zarządzania bazami danych Systemy zarządzania bazami danych (DBMS) to specjalistyczne oprogramowanie, które umożliwia: 1) na stałe przechowywać dowolnie duże (ale nie nieskończone) ilości danych; 2) wyodrębnić i zmodyfikować te przechowywane dane w taki czy inny sposób, za pomocą tzw. zapytań; 3) tworzyć nowe bazy danych, tj. opisywać logiczne struktury danych i ustalać ich strukturę, tj. udostępniać interfejs programistyczny; 4) uzyskiwać dostęp do przechowywanych danych przez kilku użytkowników jednocześnie (tj. zapewniać dostęp do mechanizmu zarządzania transakcjami). W związku z powyższym, Baza danych to zbiory danych znajdujące się pod kontrolą systemów zarządzania. Obecnie systemy zarządzania bazami danych są najbardziej złożonymi produktami oprogramowania na rynku i stanowią jego podstawę. W przyszłości planowane jest prowadzenie prac rozwojowych nad połączeniem konwencjonalnych systemów zarządzania bazami danych z programowaniem obiektowym (OOP) i technologiami internetowymi. Początkowo DBMS opierały się na: hierarchiczny и modele danych sieciowych, tj. może pracować tylko ze strukturami drzewiastymi i grafowymi. W procesie rozwoju w 1970 roku pojawiły się systemy zarządzania bazami danych zaproponowane przez Codda, oparte na: relacyjny model danych. 2. Relacyjne bazy danych Termin „relacyjny” pochodzi od angielskiego słowa „relation” – „relationship”. W najbardziej ogólnym sensie matematycznym (jak pamiętamy z klasycznego kursu algebry zbiorów) postawa - to zestaw R = {(x1,..., xn) | X1 A1,...,Xn ∈ An}, gdzie1,..., An to zbiory tworzące produkt kartezjański. W ten sposób, stosunek R jest podzbiorem iloczynu kartezjańskiego zbiorów: A1 x... x An : R ⊆ A 1 x... x An. Rozważmy na przykład relacje binarne ścisłego porządku „większe niż” i „mniejsze niż” na zbiorze uporządkowanych par liczb A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x A2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x A2. Relacje te można przedstawić w formie tabel. Stosunek „większy niż”>:
Stosunek „mniej niż” R<:
Widzimy zatem, że w relacyjnych bazach danych duża różnorodność danych jest zorganizowana w formie relacji i może być prezentowana w formie tabel. Należy zauważyć, że te dwie relacje R> i R< nie są sobie równoważne, innymi słowy tabele odpowiadające tym relacjom nie są sobie równe. Tak więc formy reprezentacji danych w relacyjnych bazach danych mogą być różne. Jak objawia się ta możliwość odmiennej reprezentacji w naszym przypadku? Relacje R> i R< - są to zbiory, a zbiór jest strukturą nieuporządkowaną, co oznacza, że w tabelach odpowiadających tym relacjom wiersze mogą być ze sobą zamieniane. Ale jednocześnie elementy tych zbiorów są zbiorami uporządkowanymi, w naszym przypadku - uporządkowanymi parami liczb 3, 4, 5, co oznacza, że kolumny nie mogą być zamieniane. Pokazaliśmy zatem, że reprezentacja relacji (w sensie matematycznym) w postaci tabeli o dowolnej kolejności wierszy i ustalonej liczbie kolumn jest akceptowalną, poprawną formą reprezentacji relacji. Ale jeśli weźmiemy pod uwagę relacje R> i R< z punktu widzenia zawartych w nich informacji widać, że są one równoważne. Dlatego w relacyjnych bazach danych pojęcie „związek” ma nieco inne znaczenie niż relacja w matematyce ogólnej. Mianowicie nie jest to związane z uporządkowaniem według kolumn w tabelarycznej formie prezentacji. Zamiast tego wprowadzono tak zwane schematy relacji „wiersz – nagłówek kolumny”, tzn. każda kolumna otrzymuje nagłówek, po którym można je dowolnie zamieniać. Tak będzie wyglądać nasza relacja R> i R< w relacyjnej bazie danych. Ścisła relacja porządku (zamiast relacji R>):
Ścisła relacja porządku (zamiast relacji R<):
Obie tabele-relacje otrzymują nową (w tym przypadku taką samą, ponieważ wprowadzając dodatkowe nagłówki wymazaliśmy różnice między relacjami R> i R<) tytuł. Widzimy więc, że za pomocą tak prostej sztuczki, jak dodanie niezbędnych nagłówków do tabel, dochodzimy do tego, że relacje R> i R< stają się sobie równoważni. Zatem dochodzimy do wniosku, że pojęcie „związku” w ogólnym sensie matematycznym i relacyjnym nie jest całkowicie zbieżne, nie są identyczne. Obecnie systemy zarządzania relacyjnymi bazami danych stanowią podstawę rynku technologii informatycznych. Prowadzone są dalsze badania w kierunku łączenia różnych stopni modelu relacyjnego. Wykład 2. Brakujące dane W systemach zarządzania bazami danych do wykrywania brakujących danych opisane są dwa rodzaje wartości: puste (lub Puste-wartości) i niezdefiniowane (lub Null-wartości). W niektórych (głównie komercyjnych) literaturze wartości Null są czasami określane jako wartości puste lub wartości null, ale jest to niepoprawne. Znaczenie pustych i nieokreślonych znaczeń jest zasadniczo różne, dlatego konieczne jest uważne monitorowanie kontekstu użycia określonego terminu. 1. Puste wartości (puste-wartości) pusta wartość to tylko jedna z wielu możliwych wartości dla jakiegoś dobrze zdefiniowanego typu danych. Wymieniamy najbardziej „naturalne”, natychmiastowe puste wartości (czyli puste wartości, które moglibyśmy przydzielić sami bez dodatkowych informacji): 1) 0 (zero) - wartość null jest pusta dla numerycznych typów danych; 2) false (zły) - jest pustą wartością dla typu danych binarnych; 3) B'' - pusty ciąg bitów dla ciągów o zmiennej długości; 4) "" - pusty ciąg dla ciągów znaków o zmiennej długości. W powyższych przypadkach można określić, czy wartość jest pusta, czy nie, porównując istniejącą wartość ze stałą pustą zdefiniowaną dla każdego typu danych. Jednak systemy zarządzania bazami danych, ze względu na zaimplementowane w nich schematy długoterminowego przechowywania danych, mogą pracować tylko z ciągami o stałej długości. Z tego powodu pusty ciąg bitów można nazwać ciągiem zer binarnych. Lub ciąg składający się ze spacji lub innych znaków sterujących jest pustym ciągiem znaków. Oto kilka przykładów ciągów pustych o stałej długości: 1) B'0'; 2) B'000'; 3) ' '. Jak w takich przypadkach rozpoznać, czy ciąg jest pusty? W systemach zarządzania bazami danych do testowania pustki wykorzystywana jest funkcja logiczna, czyli predykat IsEmpty(<wyrażenie>), co dosłownie oznacza „jeść puste”. Ten predykat jest zwykle wbudowany w system zarządzania bazą danych i można go zastosować do dowolnego typu wyrażenia. Jeżeli takiego predykatu nie ma w systemach zarządzania bazami danych, to można samodzielnie napisać funkcję logiczną i dołączyć ją do listy obiektów projektowanej bazy danych. Rozważ inny przykład, w którym nie jest tak łatwo określić, czy mamy pustą wartość. Dane typu daty. Która wartość w tym typie powinna być uważana za wartość pustą, jeśli data może się różnić w zakresie od 01.01.0100. przed 31.12.9999? W tym celu w DBMS wprowadzane jest specjalne oznaczenie dla константы пустой даты {...}, jeśli zapisana jest wartość tego typu: {DD. MM. RR} lub {RR. MM. DD}. Przy tej wartości następuje porównanie podczas sprawdzania wartości pod kątem pustki. Uznawana jest za dobrze zdefiniowaną, „pełną” wartość wyrażenia tego typu i najmniejszą możliwą. Podczas pracy z bazami danych wartości null są często używane jako wartości domyślne lub są używane w przypadku braku wartości wyrażeń. 2. Niezdefiniowane wartości (Wartości zerowe) Słowo Null używany do oznaczenia niezdefiniowane wartości w bazach danych. Aby lepiej zrozumieć, jakie wartości są rozumiane jako niezdefiniowane, rozważ tabelę będącą fragmentem bazy danych:
W ten sposób niezdefiniowana wartość lub Wartość zerowa - to jest: 1) nieznana, ale zwykła, tj. obowiązująca wartość. Na przykład pan Khairetdinov, który jest numerem jeden w naszej bazie danych, niewątpliwie ma pewne dane paszportowe (jak osoba urodzona w 1980 roku i obywatel kraju), ale nie są one znane, dlatego nie są uwzględniane w bazie . Dlatego wartość Null zostanie zapisana w odpowiedniej kolumnie tabeli; 2) nie dotyczy wartości. Pan Karamazow (nr 2 w naszej bazie danych) po prostu nie może mieć żadnych danych paszportowych, ponieważ w momencie tworzenia tej bazy danych lub wprowadzania do niej danych był dzieckiem; 3) wartość dowolnej komórki tabeli, jeśli nie możemy powiedzieć, czy ma ona zastosowanie, czy nie. Na przykład pan Kovalenko, który zajmuje trzecie miejsce w opracowanej przez nas bazie danych, nie zna roku urodzenia, więc nie możemy z całą pewnością stwierdzić, czy ma dane paszportowe, czy też nie. I w konsekwencji wartości dwóch komórek w linii poświęconej panu Kovalenko będą wartością zerową (pierwsza - jako nieznana w ogóle, druga - jako wartość, której natura jest nieznana). Jak każdy inny typ danych, wartości Null również mają pewność właściwości. Wymieniamy najważniejsze z nich: 1) z biegiem czasu rozumienie wartości Null może ulec zmianie. Na przykład dla pana Karamazowa (nr 2 w naszej bazie danych) w 2014 roku, tj. po osiągnięciu pełnoletności, wartość zero zmieni się na określoną, dobrze określoną wartość; 2) Wartość pusta może być przypisana zmiennej lub stałej dowolnego typu (numeryczna, łańcuchowa, logiczna, data, godzina itp.); 3) wynikiem wszelkich operacji na wyrażeniach z wartościami Null jako argumentami jest wartość Null; 4) wyjątkiem od poprzedniej reguły są operacje koniunkcji i alternatywy w warunkach praw absorpcji (więcej szczegółów na temat praw absorpcji w paragrafie 4 wykładu nr 2). 3. Wartości Null i ogólna zasada oceny wyrażeń Porozmawiajmy więcej o akcjach na wyrażeniach zawierających wartości Null. Ogólna zasada postępowania z wartościami Null (że wynikiem operacji na wartościach Null jest wartość Null) dotyczy następujących operacji: 1) do arytmetyki; 2) do operacji bitowych negacji, koniunkcji i alternatywy (z wyjątkiem praw absorpcji); 3) do operacji na ciągach (na przykład konkatenacja - konkatenacja ciągów); 4) do operacji porównawczych (<, ≤, ≠, ≥, >). Podajmy przykłady. W wyniku zastosowania następujących operacji zostaną uzyskane wartości Null: 3 + zero, 1/ zero, (Iwanow' + '' + zero) ≔ zero Tutaj zamiast zwykłej równości używamy operacja zastępcza „≔” ze względu na szczególny charakter pracy z wartościami Null. W dalszej części ten znak będzie również używany w podobnych sytuacjach, co oznacza, że wyrażenie po prawej stronie symbolu wieloznacznego może zastąpić dowolne wyrażenie z listy znajdującej się po lewej stronie znaku wieloznacznego. Charakter wartości Null często powoduje, że niektóre wyrażenia generują wartość Null zamiast oczekiwanej wartości null, na przykład: (x - x), y * (x - x), x * 0 ≔ Null, gdy x = Null. Chodzi o to, że podstawiając na przykład wartość x = Null do wyrażenia (x - x), otrzymujemy wyrażenie (Null - Null) i ogólną zasadę obliczania wartości wyrażenia zawierającego wartości Null wejdzie w życie, a informacja o tym, że tutaj wartość Null odpowiada tej samej zmiennej ginie. Możemy wnioskować, że przy obliczaniu dowolnych operacji innych niż logiczne wartości Null są interpretowane jako nieodpowiedni, a zatem wynik jest również wartością Null. Użycie wartości Null w operacjach porównania prowadzi do nie mniej nieoczekiwanych wyników. Na przykład następujące wyrażenia również generują wartości Null zamiast oczekiwanych wartości logicznych True lub False: (null < null); (Zero ≤ zero); (null = zero); (null ≠ zero); (Null > Null); (null ≥ zero) ≔ zero; W związku z tym dochodzimy do wniosku, że nie można powiedzieć, że wartość Null jest sobie równa lub nie równa sobie. Każde nowe wystąpienie wartości Null jest traktowane jako niezależne, a za każdym razem wartości Null są traktowane jako różne nieznane wartości. Pod tym względem wartości Null zasadniczo różnią się od wszystkich innych typów danych, ponieważ wiemy, że można bezpiecznie powiedzieć o wszystkich przekazanych wcześniej wartościach i ich typach, że są sobie równe lub nierówne. Widzimy więc, że wartości Null nie są wartościami zmiennych w zwykłym znaczeniu tego słowa. W związku z tym niemożliwe staje się porównywanie wartości zmiennych lub wyrażeń zawierających wartości Null, ponieważ w wyniku otrzymamy nie wartości logiczne True lub False, ale wartości Null, jak w poniższych przykładach: (x < zero); (x ≤ zero); (x=Null); (x ≠ zero); (x > zero); (x ≥ zero) ≔ zero; Dlatego, analogicznie do pustych wartości, aby sprawdzić wyrażenie pod kątem wartości Null, należy użyć specjalnego predykatu: IsNull(<wyrażenie>), co dosłownie oznacza „jest zerowa”. Funkcja Boolean zwraca True, jeśli wyrażenie zawiera wartość Null lub ma wartość Null, a False w przeciwnym razie, ale nigdy nie zwraca wartości Null. Predykat IsNull można zastosować do zmiennych i wyrażeń dowolnego typu. Po zastosowaniu do wyrażeń typu pustego predykat zawsze zwróci False. Na przykład:
Tak więc rzeczywiście widzimy, że w pierwszym przypadku, gdy predykat IsNull został wzięty od zera, wynik okazał się fałszem. We wszystkich przypadkach, w tym w drugim i trzecim, gdy argumenty funkcji logicznej okazały się równe wartości Null, a w czwartym przypadku, gdy sam argument początkowo był równy wartości Null, predykat zwrócił True. 4. Wartości Null i operacje logiczne Zazwyczaj w systemach zarządzania bazami danych bezpośrednio obsługiwane są tylko trzy operacje logiczne: negacja ¬, koniunkcja & i alternatywa ∨. Operacje następstwa ⇒ i równoważności ⇔ wyraża się za pomocą podstawień: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Należy zauważyć, że te podstawienia są w pełni zachowywane podczas używania wartości Null. Co ciekawe, używając operatora negacji "¬" każda z operacji koniunkcja & lub alternatywa ∨ może być wyrażona jedna przez drugą w następujący sposób: (x i y) ¬ (¬x ¬y); (x ∨ y) ≔ ¬(¬x i ¬y); Te podstawienia, jak również poprzednie, nie podlegają wartościom Null. A teraz podamy tabele prawdy operacji logicznych negacji, koniunkcji i alternatywy, ale oprócz zwykłych wartości True i False jako operandów używamy również wartości Null. Dla wygody wprowadzamy następującą notację: zamiast True napiszemy t, zamiast False - f, a zamiast Null - n. 1. Odmowa XX.
Warto zwrócić uwagę na następujące ciekawostki dotyczące operacji negacji przy użyciu wartości Null: 1) ¬¬x ≔ x - prawo podwójnej negacji; 2) ¬Null ≔ Null — wartość Null jest punktem stałym. 2. Koniunkcja x i y.
Ta operacja ma również swoje własne właściwości: 1) x & y ≔ y & x - przemienność; 2) x & x ≔ x - idempotencja; 3) False & y ≔ False, tutaj False jest elementem absorbującym; 4) Prawda i y ≔ y, tutaj Prawda jest elementem neutralnym. 3. Iloczyn x ∨ y.
cechy: 1) x y ≔ y ∨ x - przemienność; 2) x x ≔ x - idempotencja; 3) Fałsz ∨ y ≔ y, tutaj Fałsz jest elementem neutralnym; 4) Prawda ∨ y ≔ Prawda, tutaj Prawda jest elementem absorbującym. Wyjątkiem od ogólnej reguły są zasady obliczania operacji logicznych koniunkcja & i alternatywa ∨ w warunkach działania prawa absorpcji: (Fałsz & y) ≔ (x & Fałsz) ≔ Fałsz; (Prawda ∨ y) ≔ (x ∨ Prawda) ≔ Prawda; Te dodatkowe zasady są sformułowane w taki sposób, że przy zastępowaniu wartości Null wartością Fałsz lub Prawda wynik nadal nie będzie zależał od tej wartości. Jak wcześniej pokazano w przypadku innych typów operacji, użycie wartości Null w operacjach logicznych może również skutkować nieoczekiwanymi wartościami. Na przykład logika na pierwszy rzut oka jest złamana prawo wyłączenia trzeciej (x ∨ ¬x) i prawo refleksyjności (x = x), ponieważ dla x ≔ Null mamy: (x ∨ ¬x), (x = x) ≔ Zero. Prawa nie są egzekwowane! Wyjaśnia się to w ten sam sposób, jak poprzednio: po podstawieniu wartości Null do wyrażenia, informacja, że ta wartość jest raportowana przez tę samą zmienną, zostaje utracona i obowiązuje ogólna zasada pracy z wartościami Null. Zatem dochodzimy do wniosku: podczas wykonywania operacji logicznych z wartościami Null jako operandem, wartości te są określane przez systemy zarządzania bazami danych jako dotyczy, ale nieznane. 5. Wartości Null i sprawdzanie warunków Tak więc z powyższego możemy wywnioskować, że w logice systemów zarządzania bazami danych nie istnieją dwie wartości logiczne (True i False), ale trzy, ponieważ wartość Null jest również uważana za jedną z możliwych wartości logicznych. Dlatego często nazywa się ją wartością nieznaną, wartością nieznaną. Jednak mimo to w systemach zarządzania bazami danych implementowana jest tylko logika dwuwartościowa. Dlatego warunek o wartości Null (niezdefiniowany warunek) musi być interpretowany przez maszynę jako Prawda lub Fałsz. Domyślnie język DBMS rozpoznaje warunek o wartości Null jako False. Zilustrujemy to następującymi przykładami implementacji instrukcji warunkowych If i While w systemach zarządzania bazami danych: Jeśli P, to A inaczej B; Ten wpis oznacza: jeśli P ma wartość Prawda, to wykonywana jest akcja A, a jeśli P ma wartość Fałsz lub Null, to wykonywana jest akcja B. Teraz zastosujemy operację negacji do tego operatora, otrzymujemy: Jeśli ¬P to B inaczej A; Z kolei ten operator oznacza, co następuje: jeśli ¬P ma wartość Prawda, to wykonywana jest akcja B, a jeśli ¬P ma wartość Fałsz lub Null, to akcja A zostanie wykonana. I znowu, jak widzimy, gdy pojawia się wartość Null, napotykamy nieoczekiwane wyniki. Chodzi o to, że dwie instrukcje If w tym przykładzie nie są równoważne! Chociaż jeden z nich uzyskuje się od drugiego poprzez zanegowanie warunku i przestawienie gałęzi, czyli przez standardową operację. Takie operatory są generalnie równoważne! Ale w naszym przykładzie widzimy, że zerowa wartość warunku P w pierwszym przypadku odpowiada poleceniu B, aw drugim - A. Rozważmy teraz działanie instrukcji warunkowej while: Podczas gdy P zrobić A; B; Jak działa ten operator? Dopóki P ma wartość Prawda, akcja A zostanie wykonana, a gdy P będzie fałszem lub zerem, zostanie wykonana akcja B. Ale wartości Null nie zawsze są interpretowane jako False. Na przykład w ograniczeniach integralności niezdefiniowane warunki są uznawane za Prawda (ograniczenia integralności to warunki, które są nakładane na dane wejściowe i zapewniają ich poprawność). Dzieje się tak dlatego, że w takich ograniczeniach należy odrzucać tylko celowo fałszywe dane. I znowu, w systemach zarządzania bazami danych jest specjalny funkcja podstawienia IfNull(ograniczenia integralności, True), za pomocą którego można jawnie przedstawić wartości Null i niezdefiniowane warunki. Przepiszmy warunkowe instrukcje If i While za pomocą tej funkcji: 1) Jeśli IfNull (P, False) to A w przeciwnym razie B; 2) Podczas gdy IfNull (P, False) wykonaj A; B; Tak więc funkcja podstawienia IfNull(wyrażenie 1, wyrażenie 2) zwraca wartość pierwszego wyrażenia, jeśli nie zawiera wartości Null, aw przeciwnym razie wartość drugiego wyrażenia. Należy zauważyć, że nie ma ograniczeń co do typu wyrażenia zwracanego przez funkcję IfNull. Dlatego za pomocą tej funkcji można jawnie przesłonić wszelkie reguły pracy z wartościami Null. Wykład 3. Obiekty danych relacyjnych 1. Wymagania dotyczące tabelarycznej formy reprezentacji relacji 1. Pierwszym warunkiem tabelarycznej postaci reprezentacji relacji jest skończoność. Praca z nieskończonymi tabelami, relacjami lub innymi reprezentacjami i organizacjami danych jest niewygodna, rzadko uzasadnia włożony wysiłek, a ponadto ten kierunek ma niewiele praktycznego zastosowania. Ale oprócz tego, całkiem oczekiwane, są inne wymagania. 2. Nagłówek tabeli reprezentującej relację musi koniecznie składać się z jednego wiersza - nagłówka kolumn oraz z unikalnymi nazwami. Nagłówki wielopoziomowe są niedozwolone. Na przykład te:
Wszystkie nagłówki wielowarstwowe są zastępowane nagłówkami jednowarstwowymi, wybierając odpowiednie nagłówki. W naszym przykładzie tabela po określonych przekształceniach będzie wyglądać tak:
Widzimy, że nazwa każdej kolumny jest unikalna, więc można je dowolnie zamieniać, tzn. ich kolejność staje się nieistotna. A to bardzo ważne, bo to trzecia właściwość. 3. Kolejność wierszy nie powinna być znacząca. Jednak ten wymóg nie jest również ściśle restrykcyjny, ponieważ każdą tabelę można łatwo sprowadzić do wymaganej formy. Na przykład możesz wprowadzić dodatkową kolumnę, która określi kolejność wierszy. W tym przypadku również nic się nie zmieni po przestawieniu linii. Oto przykład takiego stołu:
4. W tabeli reprezentującej relację nie powinno być zduplikowanych wierszy. Jeśli w tabeli znajdują się zduplikowane wiersze, można to łatwo naprawić, wprowadzając dodatkową kolumnę odpowiedzialną za liczbę duplikatów każdego wiersza, na przykład:
Poniższa właściwość jest również całkiem oczekiwana, ponieważ leży u podstaw wszystkich zasad programowania i projektowania relacyjnych baz danych. 5. Dane we wszystkich kolumnach muszą być tego samego typu. A poza tym muszą być prostego typu. Wyjaśnijmy, czym są proste i złożone typy danych. Prosty typ danych to taki, którego wartości danych są niezłożone, to znaczy nie zawierają części składowych. Dlatego w kolumnach tabeli nie powinny znajdować się ani listy, ani tablice, ani drzewa, ani podobne obiekty złożone. Takie obiekty są złożony typ danych - w systemach zarządzania relacyjnymi bazami danych są one same prezentowane w postaci niezależnych tabel-relacji. 2. Domeny i atrybuty Domeny i atrybuty to podstawowe pojęcia w teorii tworzenia i zarządzania bazami danych. Wyjaśnijmy, co to jest. Formalnie, domena atrybutów (oznaczony przez dom(a)), gdzie a jest atrybutem, jest zdefiniowany jako zbiór poprawnych wartości tego samego typu co odpowiadający atrybut a. Ten typ musi być prosty, czyli: dom(a) ⊆ {x | typ(x) = typ(a)}; Atrybut (oznaczony a) jest z kolei definiowany jako uporządkowana para składająca się z nazwy atrybutu name(a) oraz domeny atrybutu dom(a), czyli: a = (imię(a): dom(a)); Ta definicja używa ":" zamiast zwykłego "," (jak w standardowych definicjach par uporządkowanych). Ma to na celu podkreślenie powiązania domeny atrybutu z typem danych atrybutu. Oto kilka przykładów różnych atrybutów: а1 = (Kurs: {1, 2, 3, 4, 5}); а2 = (MasaKg: {x | typ(x) = rzeczywista, x 0}); а3 = (DługośćSm: {x | typ(x) = rzeczywista, x 0}); Zauważ, że atrybuty a2 i a3 domeny są formalnie zgodne. Ale znaczenie semantyczne tych atrybutów jest inne, ponieważ porównywanie wartości masy i długości jest bez znaczenia. Dlatego domena atrybutów jest powiązana nie tylko z typem poprawnych wartości, ale także z znaczeniem semantycznym. W formie tabelarycznej relacji atrybut jest wyświetlany jako nagłówek kolumny w tabeli, a domena atrybutu nie jest określona, ale jest domniemana. To wygląda tak:
Łatwo zauważyć, że tutaj każdy z nagłówków a1, A2, A3 kolumny tabeli reprezentujące relację są osobnym atrybutem. 3. Schematy relacji. Krotki nazwanych wartości W teorii i praktyce DBMS podstawowe są koncepcje schematu relacji i nazwanej wartości krotki w atrybucie. Przynieśmy je. schemat relacji (oznaczony przez S) jest zdefiniowany jako skończony zbiór atrybutów o unikalnych nazwach, tj.: S = {a | a S}; W każdej tabeli, która reprezentuje relację, wszystkie nagłówki kolumn (wszystkie atrybuty) są łączone w schemat relacji. Liczba atrybutów w schemacie relacji określa stopień to postawy i oznaczamy jako liczność zbioru: |S|. Schemat relacji może być powiązany z nazwą schematu relacji. W formie tabelarycznej reprezentacji relacji, jak łatwo zauważyć, schemat relacji to nic innego jak wiersz nagłówków kolumn.
S = {a1, A2, A3, A4} - schemat relacji tej tabeli. Nazwa relacji jest wyświetlana jako schematyczny nagłówek tabeli. W formie tekstowej schemat relacji może być reprezentowany jako nazwana lista nazw atrybutów, na przykład: Uczniowie (numer księgi szkolnej, nazwisko, imię, nazwisko patronimiczne, data urodzenia). Tutaj, podobnie jak w formie tabelarycznej, domeny atrybutów nie są określone, ale implikowane. Z definicji wynika, że schemat relacji również może być pusty (S = ∅). To prawda, że jest to możliwe tylko w teorii, ponieważ w praktyce system zarządzania bazą danych nigdy nie pozwoli na stworzenie pustego schematu relacji. Nazwana wartość krotki w atrybucie (oznaczony przez t(a)) definiuje się przez analogię z atrybutem jako uporządkowaną parę składającą się z nazwy atrybutu i wartości atrybutu, tj.: t(a) = (nazwa(a) : x), x ∈ dom(a); Widzimy, że wartość atrybutu jest pobierana z domeny atrybutu. W formie tabelarycznej relacji każda nazwana wartość krotki w atrybucie jest odpowiednią komórką tabeli:
Tutaj t(a1), t(a2), t(a3) - nazwane wartości krotki t na atrybutach a1I2I3. Najprostsze przykłady nazwanych wartości krotek na atrybutach: (Kurs: 5), (Punktacja: 5); Tutaj Course i Score są nazwami odpowiednio dwóch atrybutów, a 5 to jedna z ich wartości zaczerpnięta z ich domen. Oczywiście, chociaż wartości te są w obu przypadkach równe, to są one semantycznie różne, gdyż zbiory tych wartości w obu przypadkach różnią się od siebie. 4. Krotki. Typy krotek Pojęcie krotki w systemach zarządzania bazami danych można intuicyjnie odnaleźć już w poprzednim punkcie, kiedy mówiliśmy o nazwanej wartości krotki na różnych atrybutach. Więc, orszak (oznaczony przez t, z angielskiego. krotka - „krotka”) ze schematem relacji S jest zdefiniowana jako zbiór nazwanych wartości tej krotki na wszystkich atrybutach zawartych w tym schemacie relacji S. Innymi słowy, atrybuty są pobierane z zakres krotki, def(t), tj.: t ≡ t(S) = {t(a) | a def(t) ⊆ S;. Ważne jest, aby jednej nazwie atrybutu odpowiadała nie więcej niż jedna wartość atrybutu. W formie tabelarycznej relacji krotka będzie dowolnym wierszem tabeli, tj.:
Tutaj t1(S) = {t(a1), t(a2), t(a3), t(a4)} oraz T2(S) = {t(a5), t(a6), t(a7), t(a8)} - krotki. Krotki w DBMS różnią się typy w zależności od dziedziny definicji. Krotki nazywają się: 1) częściowy, если их область определения включается или совпадает со схемой отношения, т. е. def(t) ⊆ S. Jest to powszechny przypadek w praktyce baz danych; 2) kompletny, в том случае если их область определения полностью совпадает, равна схеме отношения, т. е. def(t) = S; 3) niekompletny, если область определения полностью включается в схему отношений, т. е. def(t) ⊂ S; 4) nigdzie nie zdefiniowano, если их область определения равна пустому множеству, т. е. def(t) = ∅. Wyjaśnijmy na przykładzie. Załóżmy, że mamy zależność podaną w poniższej tabeli.
Niech tu t1 = {10, 20, 30}, t2 = {10, 20, zero}, t3 = {Null, zero, zero}. Wtedy łatwo zauważyć, że krotka t1 - pełna, ponieważ jej dziedziną definicji jest def(t1) = {a, b, c} = S. Krotka t2 - niekompletne, def(t2) = { a, b} ⊂ S. Wreszcie krotka t3 - nigdzie nie zdefiniowane, ponieważ jego def(t3) = ∅. Należy zauważyć, że krotka nigdzie nie zdefiniowana jest zbiorem pustym, niemniej jednak powiązanym ze schematem relacji. Czasami krotka nigdzie zdefiniowana jest oznaczana: ∅(S). Jak już widzieliśmy w powyższym przykładzie, taka krotka jest wierszem tabeli składającym się tylko z wartości Null. Interesujące jest to, porównywalny, czyli być może równe, są tylko krotkami o tym samym schemacie relacji. Dlatego na przykład dwie nigdzie zdefiniowane krotki z różnymi schematami relacji nie będą równe, jak można się spodziewać. Będą się różnić, podobnie jak ich wzorce relacji. 5. Relacje. Typy relacji I na koniec zdefiniujmy relację jako rodzaj wierzchołka piramidy, składającego się ze wszystkich poprzednich pojęć. Więc, postawa (oznaczony przez r, z angielskiego. relacji) ze schematem relacji S jest zdefiniowany jako z konieczności skończony zbiór krotek o tym samym schemacie relacji S. Zatem: r ≡ r(S) = {t(S) | t ∈r}; Przez analogię do schematów relacji liczbę krotek w relacji nazywamy siła relacji i oznaczony jako liczność zbioru: |r|. Relacje, podobnie jak krotki, różnią się rodzajem. Tak więc związek nazywa się: 1) częściowy, jeśli dla dowolnej krotki zawartej w relacji spełniony jest następujący warunek: [def(t) ⊆ S]. Jest to (jak w przypadku krotek) przypadek ogólny; 2) kompletny, w przypadku, gdy ∀t ∈ r(S) mamy [def(t) = S]; 3) niekompletny, jeśli ∃t ∈ r(S) def(t) ⊂ S; 4) nigdzie nie zdefiniowano, jeśli ∀t ∈ r(S) [def(t) = ∅]. Zwróćmy szczególną uwagę na nigdzie nie zdefiniowane relacje. W przeciwieństwie do krotek praca z takimi relacjami wymaga odrobiny subtelności. Chodzi o to, że relacje zdefiniowane nigdzie mogą być dwojakiego rodzaju: mogą być albo puste, albo mogą zawierać pojedynczą krotkę zdefiniowaną nigdzie (takie relacje są oznaczane przez {∅(S)}). porównywalny (przez analogię do krotek), tj. być może równe, są tylko relacje o tym samym schemacie relacji. Dlatego relacje z różnymi schematami relacji są różne. W formie tabelarycznej relacją jest treść tabeli, której odpowiada wiersz – nagłówek kolumn, czyli dosłownie – cała tabela wraz z pierwszym wierszem zawierającym nagłówki. Wykład nr 4. Algebra relacyjna. Operacje jednoargumentowe Algebra relacyjnajak można się domyślić, to szczególny rodzaj algebry, w którym wszystkie operacje wykonywane są na relacyjnych modelach danych, czyli na relacjach. W ujęciu tabelarycznym relacja obejmuje wiersze, kolumny oraz wiersz - nagłówek kolumn. Dlatego naturalnymi operacjami jednoargumentowymi są operacje wyboru określonych wierszy lub kolumn, a także zmiana nagłówków kolumn - zmiana nazw atrybutów. 1. Jednoargumentowa operacja wyboru Pierwsza jednoargumentowa operacja, której przyjrzymy się, to operacja pobierania - operacja wybierania wierszy z tabeli reprezentującej relację według jakiejś zasady, czyli wybierania wierszy-krotek spełniających określony warunek lub warunki. Operator pobierania oznaczone przez σ , warunki pobierania próbek - P , czyli operator σ jest zawsze brany z pewnym warunkiem na krotki P, a sam warunek P jest zapisywany w zależności od schematu relacji S. Biorąc to wszystko pod uwagę, operacja pobierania nad schematem relacji S w stosunku do relacji r będzie wyglądać tak: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, Fałsz}; Wynikiem tej operacji będzie nowa relacja o tym samym schemacie relacji S, składająca się z krotek t(S) oryginalnego argumentu relacji, które spełniają warunek wyboru P t. Oczywiste jest, że aby zastosować jakiś warunek do krotki, konieczne jest podstawienie wartości atrybutów krotki zamiast nazw atrybutów. Aby lepiej zrozumieć, jak działa ta operacja, spójrzmy na przykład. Niech zostanie podany następujący schemat relacji: S: Sesja (nr dziennika ocen, nazwisko, przedmiot, ocena). Przyjmijmy następujący warunek wyboru: P = (Temat = „Informatyka” i ocena > 3). Musimy wyodrębnić z początkowego operandu relacji te krotki, które zawierają informacje o studentach, którzy zaliczyli przedmiot „Informatyka” o co najmniej trzy punkty. Niech otrzymamy również następującą krotkę z tej relacji: t0(S) ∈ r(S): {(Dziennik ocen: 100), (Nazwisko: 'Iwanow'), (Temat: 'Bazy danych'), (Wynik: 5)}; Stosowanie naszego warunku wyboru do krotki t0otrzymujemy: P t0 = („Bazy danych” = „Informatyka” i 5 > 3); W tej konkretnej krotce warunek wyboru nie jest spełniony. Ogólnie wynik tej konkretnej próbki σ<Temat = 'Informatyka' i Ocena > 3 > Sesja pojawi się tabela „Sesja”, w której pozostaną wiersze spełniające warunek wyboru. 2. Jednoargumentowa operacja projekcji Inną standardową operacją jednoargumentową, którą będziemy studiować, jest operacja projekcji. Operacja projekcji jest operacją wybierania kolumn z tabeli reprezentującej relację według jakiegoś atrybutu. Mianowicie, maszyna wybiera te atrybuty (czyli dosłownie te kolumny) oryginalnej relacji operandu, które zostały określone w rzucie. operator projekcji oznaczone przez [S'] lub π . Tutaj S' jest podschematem pierwotnego schematu relacji S, tj. niektórych jej kolumn. Co to znaczy? Oznacza to, że S' ma mniej atrybutów niż S, ponieważ w S' pozostały tylko te atrybuty, dla których spełniony był warunek rzutowania. A w tabeli reprezentującej relację r(S' ) jest tyle wierszy, ile jest w tabeli r(S), a kolumn jest mniej, ponieważ pozostają tylko te, które odpowiadają pozostałym atrybutom. Zatem operator rzutowania π< S'> zastosowany do relacji r(S) powoduje powstanie nowej relacji o innym schemacie relacji r(S' ), składającej się z rzutów t(S) [S' ] krotek pierwotna relacja. Jak definiuje się te projekcje krotek? Występ dowolnej krotki t(S) pierwotnej relacji r(S) do podukładu S' określa następujący wzór: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. Należy zauważyć, że zduplikowane krotki są wykluczone z wyniku, tj. w tabeli nie będzie zduplikowanych wierszy reprezentujących nowy. Mając to wszystko na uwadze, operacja projekcji w zakresie systemów zarządzania bazami danych wyglądałaby tak: π r(S) π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t r}; Spójrzmy na przykład ilustrujący działanie operacji pobierania. Niech relacja „sesja” i schemat tej relacji zostaną podane: S: Sesja (numer księgi szkolnej, nazwisko, przedmiot, ocena); Interesują nas tylko dwa atrybuty z tego schematu, a mianowicie „Dziennik ocen #” i „Nazwisko” ucznia, więc podschemat S będzie wyglądał tak: S' : (Numer księgi metrykalnej, Nazwisko). Konieczne jest rzutowanie początkowej zależności r(S) na podukład S'. Następnie daj nam krotkę t0(S) z pierwotnej relacji: t0(S) ∈ r(S): {(Dziennik ocen: 100), (Nazwisko: 'Iwanow'), (Temat: 'Bazy danych'), (Wynik: 5)}; Stąd rzut tej krotki na dany podobwód S' będzie wyglądał tak: t0(S) S': {(Numer księgi rachunkowej: 100), (Nazwisko: „Iwanow”)}; Jeśli mówimy o operacji projekcji w kategoriach tabel, to projekcją Session [numer dziennika ocen, nazwisko] pierwotnej relacji jest tabela Session, z której usuwane są wszystkie kolumny oprócz dwóch: numer dziennika ocen i nazwisko. Ponadto wszystkie zduplikowane wiersze również zostały usunięte. 3. Jednoargumentowa operacja zmiany nazwy A ostatnią jednoargumentową operacją, której się przyjrzymy, jest operacja zmiany nazwy atrybutu. Jeśli mówimy o relacji jako tabeli, to operacja zmiany nazwy jest potrzebna, aby zmienić nazwy wszystkich lub niektórych kolumn. zmień nazwę operatora wygląda tak: ρ<φ>, tutaj φ - zmiana nazwy funkcji. Funkcja ta ustanawia korespondencję jeden do jednego pomiędzy nazwami atrybutów schematu S i Ŝ, gdzie odpowiednio S jest schematem oryginalnej relacji, a Ŝ jest schematem relacji ze zmienionymi atrybutami. Tak więc operator ρ<φ> zastosowany do relacji r(S) daje nową relację ze schematem Ŝ, składającą się z krotek oryginalnej relacji z jedynie zmienionymi atrybutami. Napiszmy operację zmiany nazw atrybutów pod kątem systemów zarządzania bazami danych: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t r}; Oto przykład użycia tej operacji: Rozważmy znaną nam już relację Sesja ze schematem: S: Sesja (numer księgi szkolnej, nazwisko, przedmiot, ocena); Wprowadźmy nowy schemat relacji, z różnymi nazwami atrybutów, które chcielibyśmy widzieć zamiast istniejących: Ŝ : (Nr ZK, Nazwisko, Temat, Punktacja); Na przykład klient bazy danych chciał zobaczyć inne nazwiska w Twojej nieszablonowej relacji. Aby zrealizować to zamówienie, musisz zaprojektować następującą funkcję zmiany nazwy: φ : (numer księgi, Nazwisko, Przedmiot, Ocena) → (Nr ZK, Nazwisko, Przedmiot, Punktacja); W rzeczywistości tylko dwa atrybuty muszą zostać zmienione, więc dozwolone jest napisanie następującej funkcji zmiany nazwy zamiast obecnej: φ : (numer księgi ocen, klasa) → (nr ZK, punktacja); Dalej, niech już znana krotka należąca do relacji sesji zostanie również podana: t0(S) ∈ r(S): {(Dziennik ocen: 100), (Nazwisko: 'Iwanow'), (Temat: 'Bazy danych'), (Wynik: 5)}; Zastosuj operator zmiany nazwy do tej krotki: ρ<φ>t0(S): {(ZK#: 100), (Nazwisko: 'Iwanow'), (Temat: 'Bazy danych'), (Wynik: 5)}; Jest to więc jedna z krotek naszej relacji, której atrybuty zostały zmienione. W ujęciu tabelarycznym stosunek ρ < numer dziennika ocen, klasa → "Nr ZK, Wynik > Sesja - jest to nowa tabela uzyskana z tabeli relacji „Session” poprzez zmianę nazwy określonych atrybutów. 4. Własności operacji jednoargumentowych Operacje jednoargumentowe, jak wszystkie inne, mają pewne właściwości. Rozważmy najważniejsze z nich. Pierwszą właściwością operacji jednoargumentowego wyboru, projekcji i zmiany nazwy jest właściwość charakteryzująca stosunek kardynalności relacji. (Przypomnijmy, że kardynalność to liczba krotek w takiej lub innej relacji). Jasne jest, że rozważamy tutaj odpowiednio relację początkową i relację uzyskaną w wyniku zastosowania tej lub innej operacji. Należy zauważyć, że wszystkie właściwości operacji jednoargumentowych wynikają bezpośrednio z ich definicji, dzięki czemu można je łatwo wyjaśnić, a nawet, w razie potrzeby, wyprowadzić niezależnie. Tak więc: 1) stosunek mocy: a) dla operacji selekcji: | σ r |≤ |r|; b) dla operacji projekcji: | r[S'] | ≤ |r|; c) dla operacji zmiany nazwy: | ρ<φ>r | = |r|; W sumie widzimy, że dla dwóch operatorów, a mianowicie dla operatora selekcji i operatora projekcji, moc pierwotnych relacji - operandów jest większa niż moc relacji otrzymanych z oryginalnych przez zastosowanie odpowiednich operacji. Dzieje się tak, ponieważ wybór towarzyszący tym dwóm operacjom wyboru i projektu wyklucza niektóre wiersze lub kolumny, które nie spełniają warunków wyboru. W przypadku, gdy wszystkie wiersze lub kolumny spełniają warunki, nie ma spadku potęgi (czyli liczby krotek), więc nierówność we wzorach nie jest ścisła. W przypadku operacji zmiany nazwy siła relacji nie ulega zmianie, ponieważ przy zmianie nazw żadne krotki nie są wykluczone z relacji; 2) nieruchomość idempotentna: a) dla operacji pobierania próbek: σ σ r = σ ; b) dla operacji rzutowania: r [S'] [S'] = r [S']; c) w przypadku operacji zmiany nazwy, w ogólnym przypadku, własność idempotentności nie ma zastosowania. Ta właściwość oznacza, że zastosowanie tego samego operatora dwa razy z rzędu do dowolnej relacji jest równoznaczne z zastosowaniem go raz. Ogólnie rzecz biorąc, do operacji zmiany nazwy atrybutów relacji można zastosować tę właściwość, ale ze specjalnymi zastrzeżeniami i warunkami. Własność idempotencji jest bardzo często wykorzystywana do uproszczenia formy wyrażenia i sprowadzenia go do bardziej ekonomicznej, rzeczywistej postaci. A ostatnią właściwością, którą rozważymy, jest właściwość monotoniczności. Warto zauważyć, że w każdych warunkach wszystkie trzy operatory są monotoniczne; 3) właściwość monotoniczności: a) dla operacji pobierania: r1 ⊆ r2 σ r1 ⇒ σ r2; b) dla operacji projekcji: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) dla operacji zmiany nazwy: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; Pojęcie monotoniczności w algebrze relacyjnej jest podobne do tego samego pojęcia ze zwykłej algebry ogólnej. Wyjaśnijmy: jeśli początkowo relacje r1 i r2 były ze sobą powiązane w taki sposób, że r ⊆ r2, to nawet po zastosowaniu dowolnego z trzech operatorów wyboru, projekcji lub zmiany nazwy ta relacja zostanie zachowana. Wykład nr 5. Algebra relacyjna. Operacje binarne 1. Operacje sumy, przecięcia, różnicy Wszelkie operacje mają swoje własne reguły stosowalności, których należy przestrzegać, aby wyrażenia i akcje nie straciły znaczenia. Operacje teoretyzowania mnogości binarnych sumy, przecięcia i różnicy mogą być stosowane tylko do dwóch relacji z konieczności z tym samym schematem relacji. Wynikiem takich operacji binarnych będą relacje składające się z krotek spełniających warunki operacji, ale o takim samym schemacie relacji jak operandy. 1. Результатом działalność związkowa dwie relacje r1(S) i r2(S) będzie nowa relacja r3(S) składający się z tych krotek relacji r1(S) i r2(S), które należą do co najmniej jednej z pierwotnych relacji i mają ten sam schemat relacji. Zatem przecięcie tych dwóch relacji to: r3(S) = r1(S) r2(S) = {t(S) | t∈r1 t ∈r2}; Dla jasności oto przykład w zakresie tabel: Niech podane zostaną dwie relacje: r1(S):
r2(S):
Widzimy, że schematy pierwszej i drugiej relacji są takie same, tylko mają różną liczbę krotek. Związek tych dwóch relacji będzie relacją r3(S), co będzie odpowiadać poniższej tabeli: r3(S) = r1(S) r2(S):
Tak więc schemat relacji S nie uległ zmianie, wzrosła tylko liczba krotek. 2. Przejdźmy do rozważenia następnej operacji binarnej - operacje na skrzyżowaniach dwie relacje. Jak wiemy z geometrii szkolnej, wynikowa relacja będzie zawierała tylko te krotki relacji pierwotnych, które występują jednocześnie w obu relacjach r1(S) i r2(S) (ponownie, zwróć uwagę na ten sam wzorzec relacji). Operacja przecięcia dwóch relacji będzie wyglądać tak: r4(S) = r1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; I znowu rozważmy wpływ tej operacji na relacje przedstawione w postaci tabel: r1(S):
r2(S):
Zgodnie z definicją operacji przez przecięcie relacji r1(S) i r2(S) będzie nowa relacja r4(S), którego widok tabeli wyglądałby tak: r4(S) = r1(S)∩r2(S):
Rzeczywiście, jeśli spojrzymy na krotki pierwszej i drugiej relacji początkowej, jest tylko jedna wspólna wśród nich: {b, 2}. Stała się jedyną krotką nowej relacji r4(S). 3. Operacja różnicy dwie relacje definiuje się w podobny sposób jak w poprzednich operacjach. Relacje operandowe, tak jak w poprzednich operacjach, muszą mieć te same schematy relacji, wtedy wynikowa relacja będzie zawierała wszystkie krotki pierwszej relacji, których nie ma w drugiej, tj.: r5(S) = r1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; Znane już relacje r1(S) i r2(S), w widoku tabelarycznym wyglądającym tak: r1(S):
r2(S):
Rozważymy oba operandy w działaniu przecięcia dwóch relacji. Wówczas, zgodnie z tą definicją, wynikowa relacja r5(S) będzie wyglądać tak: r5(S) = r1(S)\r2(S):
Rozważane operacje binarne są podstawowe, inne operacje, bardziej złożone, są na nich oparte. 2. Produkt kartezjański i operacje łączenia naturalnego Operacja iloczyn kartezjański i operacja sprzężenia naturalnego są operacjami binarnymi typu product i są oparte na operacji łączenia dwóch relacji, którą omówiliśmy wcześniej. Chociaż działanie operacji iloczynu kartezjańskiego może wydawać się wielu osobom znajome, to jednak zaczniemy od operacji iloczynu naturalnego, ponieważ jest to przypadek bardziej ogólny niż pierwsza operacja. Rozważ więc naturalną operację łączenia. Należy od razu zauważyć, że operandami tej akcji mogą być relacje z różnymi schematami, w przeciwieństwie do trzech binarnych operacji sumy, przecięcia i zmiany nazwy. Jeśli rozważymy dwie relacje o różnych schematach relacji r1(S1) i r2(S2), wtedy oni naturalny związek będzie nowa relacja r3(S3), który będzie składał się tylko z tych krotek operandów, które pasują na przecięciu schematów relacji. W związku z tym schemat nowej relacji będzie większy niż którykolwiek ze schematów relacji pierwotnych, ponieważ jest to ich połączenie, „sklejanie”. Nawiasem mówiąc, krotki identyczne w dwóch relacjach operandowych, zgodnie z którymi zachodzi to „sklejanie”, są nazywane możliwość podłączenia. Napiszmy definicję operacji łączenia naturalnego w języku formuł systemów zarządzania bazami danych: r3(S3) = r1(S1) x r2(S2) = {t(S1 S2) | t[S1] ∈ r1 &t(S2) ∈ r2}; Rozważmy przykład, który dobrze ilustruje pracę naturalnego połączenia, jego „sklejenia”. Niech dwie relacje r1(S1) i r2(S2), w formie tabelarycznej reprezentacji, odpowiednio, równe: r1(S1):
r2(S2):
Widzimy, że te relacje mają krotki, które pokrywają się na przecięciu schematów S1 i S2 relacje. Wymieńmy je: 1) krotka {a, 1} relacji r1(S1) dopasowuje krotkę {1, x} relacji r2(S2); 2) krotka {b, 1} z r1(S1) pasuje również do krotki {1, x} z r2(S2); 3) krotka {c, 3} jest taka sama jak krotka {3, z}. Stąd, przy sprzężeniu naturalnym, nowa relacja r3(S3) uzyskuje się przez „sklejenie” dokładnie tych krotek. Więc r3(S3) w widoku tabeli będzie wyglądać tak: r3(S3) = r1(S1) x r2(S2):
Okazuje się z definicji: schemat S3 nie pokrywa się ze schematem S1, ani ze schematem S2, „skleiliśmy” dwa oryginalne schematy, przecinając krotki, aby uzyskać ich naturalne sprzężenie. Pokażmy schematycznie, jak krotki są łączone podczas stosowania operacji łączenia naturalnego. Niech relacja r1 ma formę warunkową:
A stosunek r2 - pogląd:
Wtedy ich naturalny związek wyglądałby tak:
Widzimy, że „sklejanie” relacji-argumentów zachodzi według tego samego schematu, który podaliśmy wcześniej na przykładzie. operacja Połączenie kartezjańskie jest szczególnym przypadkiem operacji sprzężenia naturalnego. Dokładniej mówiąc, rozważając wpływ operacji iloczynu kartezjańskiego na relacje, celowo zakładamy, że w tym przypadku możemy mówić tylko o nieprzecinających się schematach relacji. W wyniku zastosowania obu operacji uzyskuje się relacje ze schematami równymi unii schematów relacji operandowych, tylko wszystkie możliwe pary ich krotek wchodzą w iloczyn kartezjański dwóch relacji, ponieważ schematy operandów w żadnym wypadku nie powinny się przecinać. Zatem na podstawie powyższego piszemy wzór matematyczny na działanie iloczynu kartezjańskiego: r4(S4) = r1(S1) x r2(S2) = {t(S1 S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 S2= ∅; Przyjrzyjmy się teraz przykładowi, aby pokazać, jak będzie wyglądał wynikowy schemat relacji przy zastosowaniu operacji iloczynu kartezjańskiego. Niech dwie relacje r1(S1) i r2(S2), które są przedstawione w formie tabelarycznej w następujący sposób: r1(S1):
r2(S2):
Widzimy więc, że żadna z krotek relacji r1(S1) i r2(S2), w rzeczywistości nie pokrywają się na ich przecięciu. Dlatego w otrzymanej relacji r4(S4) spadną wszystkie możliwe pary krotek relacji pierwszego i drugiego operandu. Dostać: r4(S4) = r1(S1) x r2(S2):
Otrzymaliśmy nowy schemat relacji r4(S4) nie przez „sklejanie” krotek, jak w poprzednim przypadku, ale przez wyliczenie wszystkich możliwych różnych par krotek, które nie pasują do siebie na przecięciu oryginalnych schematów. Ponownie, podobnie jak w przypadku sprzężenia naturalnego, podajemy schematyczny przykład działania operacji iloczynu kartezjańskiego. Niech r1 ustawić w następujący sposób:
A stosunek r2 dany:
Wtedy ich iloczyn kartezjański można schematycznie przedstawić w następujący sposób:
W ten sposób otrzymujemy zależność wynikową przy zastosowaniu operacji iloczynu kartezjańskiego. 3. Własności operacji binarnych Z powyższych definicji binarnych operacji sumy, przecięcia, różnicy, iloczynu kartezjańskiego i sprzężenia naturalnego wynikają własności. 1. Ilustruje pierwsza właściwość, podobnie jak w przypadku operacji jednoargumentowych: stosunek mocy relacje: 1) dla działalności związku: |r1 r2| ≤ |r1| + |r2|; 2) dla operacji skrzyżowania: |r1 r2 | ≤ min(|r1|, |r2|); 3) dla operacji różnicy: |r1 \r2| ≤ |r1|; 4) dla operacji wyrobu kartezjańskiego: |r1 xr2| = |r1| |r2|; 5) dla operacji łączenia naturalnego: |r1 xr2| ≤ |r1| |r2|. Stosunek potęg, jak pamiętamy, charakteryzuje, jak zmienia się liczba krotek w relacjach po zastosowaniu tej lub innej operacji. Więc co widzimy? Moc stowarzyszenia dwie relacje r1 i r2 mniej niż suma mocy pierwotnych relacji-operandów. Dlaczego to się dzieje? Chodzi o to, że po scaleniu pasujące krotki znikają, zachodząc na siebie. Odnosząc się więc do przykładu, który rozważaliśmy po przejściu tej operacji, widać, że w pierwszej relacji były dwie krotki, w drugiej trzy, a w wynikowej cztery, czyli mniej niż pięć (suma moce relacji-operandów). Przez pasującą krotkę {b, 2} te relacje są „sklejane”. Moc wynikowa skrzyżowania dwie relacje są mniejsze lub równe minimalnej liczności oryginalnych relacji operandowych. Przejdźmy do definicji tej operacji: tylko te krotki, które są obecne w obu początkowych relacjach, dostają się do relacji wynikowej. Oznacza to, że liczność nowej relacji nie może przekroczyć liczności argumentu relacji, którego liczba krotek jest najmniejsza z nich. A moc wyniku może być równa tej minimalnej kardynalności, ponieważ przypadek jest zawsze dozwolony, gdy wszystkie krotki relacji o niższej kardynalności pokrywają się z niektórymi krotkami drugiego operandu relacji. W przypadku operacji różnice wszystko jest banalne. Rzeczywiście, jeśli wszystkie krotki, które są również obecne w drugiej relacji, zostaną „odjęte” od pierwszego argumentu relacji, to ich liczba (i w konsekwencji ich moc) zmniejszy się. W przypadku, gdy żadna krotka z pierwszej relacji nie pasuje do żadnej krotki z drugiej relacji, tj. nie ma nic do „odjęcia”, jej moc nie zmniejszy się. Co ciekawe, jeśli operacja Produkt kartezjański potęga relacji wynikowej jest dokładnie równa iloczynowi potęg dwóch relacji operandowych. Oczywiste jest, że dzieje się tak, ponieważ wszystkie możliwe pary krotek pierwotnych relacji są zapisywane w wyniku i nic nie jest wykluczone. I wreszcie operacja naturalne połączenie uzyskuje się relację, której potęga jest większa lub równa iloczynowi potęg dwóch pierwotnych relacji. Znowu dzieje się tak, ponieważ relacje operandów są „sklejane” przez pasujące krotki, a niepasujące są całkowicie wykluczone z wyniku. 2. Własność idempotentności: 1) dla działania związku: r ∪ r = r; 2) dla operacji przecięcia: r ∩ r = r; 3) dla operacji różnicowej: r \ r ≠ r; 4) dla operacji produktu kartezjańskiego (w ogólnym przypadku właściwość nie ma zastosowania); 5) для операции естественного соединения: r x r = r. Co ciekawe, własność idempotentności nie jest prawdziwa dla wszystkich powyższych operacji, a dla działania produktu kartezjańskiego w ogóle nie ma zastosowania. Rzeczywiście, jeśli połączysz, przetniesz lub naturalnie połączysz jakąkolwiek relację ze sobą, to się nie zmieni. Ale jeśli odejmiesz od relacji dokładnie jej równej, wynikiem będzie pusta relacja. 3. Własność przemienności: 1) dla działalności związku: r1 r2 = r2 r1; 2) dla operacji skrzyżowania: r r = r r; 3) dla operacji różnicy: r1 \r2 r2 \r1; 4) dla operacji wyrobu kartezjańskiego: r1 xr2 = r2 xr1; 5) dla operacji łączenia naturalnego: r1 xr2 = r2 xr1. Właściwość przemienności obowiązuje dla wszystkich operacji z wyjątkiem operacji różnicy. Łatwo to zrozumieć, ponieważ ich skład (krotki) nie zmienia się od zmiany relacji w miejscach. A przy stosowaniu operacji różnicy ważne jest, która z relacji operandowych jest pierwsza, ponieważ zależy to od tego, które krotki, których relacji będą traktowane jako odniesienia, to znaczy, z którymi krotkami będą porównywane inne krotki w celu wykluczenia. 4. Właściwość stowarzyszenia: 1) dla działalności związku: (r1 r2)∪r3 = r1 (r2 r3); 2) dla operacji skrzyżowania: (r1 r2)∩r3 = r1 (r2 r3); 3) dla operacji różnicy: (r1 \r2)\r3 r1 \ (R2 \r3); 4) dla operacji wyrobu kartezjańskiego: (r1 xr2) x r3 = r1 x (r2 xr3); 5) dla operacji łączenia naturalnego: (r1 xr2) x r3 = r1 x (r2 xr3). I znowu widzimy, że właściwość jest wykonywana dla wszystkich operacji z wyjątkiem operacji różnicy. Wyjaśnia się to w taki sam sposób, jak w przypadku zastosowania własności przemienności. Ogólnie rzecz biorąc, operacje sumy, przecięcia, różnicy i naturalnego sprzężenia nie mają znaczenia, w jakim porządku są relacje operandowe. Ale kiedy relacje są sobie „odbierane”, dominującą rolę odgrywa porządek. Na podstawie powyższych własności i rozumowania można wyciągnąć następujący wniosek: ostatnie trzy własności, a mianowicie własność idempotentności, przemienności i asocjatywności, są prawdziwe dla wszystkich operacji, które rozważaliśmy, z wyjątkiem operacji różnicy dwóch relacji , w przypadku którego żadna z trzech wskazanych właściwości nie była w ogóle zaspokojona, a tylko w jednym przypadku właściwość została uznana za nie przydatną. 4. Opcje operacji połączenia Wykorzystując jako podstawę jednoargumentowe operacje selekcji, projekcji, zmiany nazwy i binarne operacje sumy, przecięcia, różnicy, iloczynu kartezjańskiego i sprzężenia naturalnego rozważane wcześniej (wszystkie z nich są ogólnie nazywane operacje połączenia), możemy wprowadzić nowe operacje wywodzące się z powyższych pojęć i definicji. Ta czynność nazywa się kompilacją. dołącz opcje operacji. Pierwszym takim wariantem operacji łączenia jest operacja połączenie wewnętrzne zgodnie z określonymi warunkami połączenia. Operacja sprzężenia wewnętrznego, przez pewien określony warunek, jest definiowana jako operacja pochodna od operacji iloczynu kartezjańskiego i selekcji. Napiszmy definicję formuły tej operacji: r1(S1) X P r2(S2) = σ (r1 xr2), S1 S2 = ; Tutaj P = P<S1 S2> - warunek nałożony na połączenie dwóch schematów pierwotnych relacji-operandów. To przez ten warunek krotki są wybierane z relacji r1 i r2 w wynikową relację. Należy zauważyć, że operację sprzężenia wewnętrznego można zastosować do relacji z różnymi schematami relacji. Te schematy mogą być dowolne, ale w żadnym wypadku nie powinny się przecinać. Krotki oryginalnych relacji operandów, które są wynikiem operacji sprzężenia wewnętrznego, są nazywane krotki, które można łączyć. Aby wizualnie zilustrować działanie operacji sprzężenia wewnętrznego, podamy następujący przykład. Daj nam dwie relacje r1(S1) i r2(S2) z różnymi schematami relacji: r1(S1):
r2(S2):
Poniższa tabela poda wynik zastosowania operacji sprzężenia wewnętrznego przy warunku P = (b1 = b2). r1(S1) X P r2(S2):
Widzimy więc, że „sklejenie” dwóch tabel reprezentujących relację rzeczywiście miało miejsce właśnie dla tych krotek, w których spełniony jest warunek operacji sprzężenia wewnętrznego P = (b1 = b2). Teraz, w oparciu o wprowadzoną już operację łączenia wewnętrznego, możemy wprowadzić operację lewe sprzężenie zewnętrzne и prawe sprzężenie zewnętrzne. Wyjaśnijmy. Wynik operacji left external join jest wynikiem wewnętrznego sprzężenia, uzupełnionego niepołączonymi krotkami lewego źródłowego operandu relacji. Podobnie wynik prawej operacji sprzężenia zewnętrznego jest definiowany jako wynik operacji sprzężenia wewnętrznego rozszerzonej o niepołączalne krotki prawego operandu relacji źródłowego. Pytanie, w jaki sposób uzupełniane są powstałe relacje operacji lewego i prawego sprzężenia zewnętrznego, jest dość oczekiwane. Krotki jednego operandu relacji są uzupełniane na schemacie innego operandu relacji Wartości zerowe. Warto zauważyć, że wprowadzone w ten sposób operacje lewego i prawego sprzężenia zewnętrznego są operacjami pochodnymi z operacji sprzężenia wewnętrznego. Aby zapisać ogólne wzory dla operacji lewego i prawego sprzężenia zewnętrznego, przeprowadzimy kilka dodatkowych konstrukcji. Daj nam dwie relacje r1(S1) i r2(S2) z różnymi schematami relacji S1 i S2, które się nie przecinają. Skoro już ustaliliśmy, że operacje lewego i prawego sprzężenia wewnętrznego są pochodnymi, możemy otrzymać następujące wzory pomocnicze do wyznaczania operacji lewego sprzężenia zewnętrznego: 1) r3 (S2 S1) ≔ r1(S1) X Pr2(S2); r 3 (S2 S1) jest po prostu wynikiem sprzężenia wewnętrznego relacji r1(S1) i r2(S2). Lewe sprzężenie zewnętrzne jest operacją pochodną sprzężenia wewnętrznego, dlatego zaczynamy od niego nasze konstrukcje; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Tak więc za pomocą operacji rzutowania jednoargumentowego wybraliśmy wszystkie złączone krotki lewego początkowego argumentu relacji r1(S1). Wynik jest oznaczony r4(S1) dla łatwości użytkowania; 3) r5 (S1) ≔ r1(S1)\r4(S1); Tutaj r1(S1) to wszystkie krotki lewego argumentu relacji źródłowej, a r4(S1) - własne krotki, tylko połączone. Tak więc, korzystając z binarnego działania różnicy, względem r5(S1) otrzymaliśmy wszystkie niełączone krotki relacji lewego operandu; 4) r6(S2)≔{∅(S2)}; {∅(S2)} to nowa relacja ze schematem (S2) zawierający tylko jedną krotkę i składający się z wartości Null. Dla wygody oznaczyliśmy ten stosunek jako r6(S2); 5) r7 (S2 S1) ≔ r5(S1) x r6(S2); Tutaj wzięliśmy niepołączone krotki relacji lewego operandu (r5(S1)) i uzupełniłem je na schemacie drugiego argumentu relacji S2 Wartości zerowe, czyli kartezjański pomnożył relację złożoną z tych bardzo niepołączalnych krotek przez relację r6(S2) określone w ust. XNUMX; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 S1); To jest lewe sprzężenie zewnętrzne, uzyskany, jak widać, przez połączenie iloczynu kartezjańskiego pierwotnych relacji-argumentów r1 i r2 i relacje r7 (S2 ∪ S1) określone w ust. XNUMX. Teraz mamy wszystkie niezbędne obliczenia, aby określić nie tylko działanie lewego sprzężenia zewnętrznego, ale przez analogię i określić działanie prawego sprzężenia zewnętrznego. Więc: 1) operacja lewe sprzężenie zewnętrzne w ścisłej formie wygląda to tak: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \ (R1 x P r2) [S1]) x {∅(S2)}]; 2) operacja prawe sprzężenie zewnętrzne jest definiowany w podobny sposób jak lewe sprzężenie zewnętrzne i ma następującą postać: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \ (R1 x P r2) [S2]) x {∅(S1)}]; Te dwie operacje pochodne mają tylko dwie właściwości, o których warto wspomnieć. 1. Własność przemienności: 1) dla operacji sprzężenia zewnętrznego lewego: r1(S1) →x P r2(S2) ≠ r2(S2) →x P r1(S1); 2) dla prawidłowej operacji sprzężenia zewnętrznego: r1(S1) ←x P r2(S2) ≠ r2(S2) ←x P r1(S1) Widzimy więc, że własność przemienności nie jest spełniona dla tych operacji w formie ogólnej, ale operacje lewego i prawego sprzężenia zewnętrznego są wzajemnie odwrotne do siebie, tj. prawdziwe jest poniższe: 1) dla operacji sprzężenia zewnętrznego lewego: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) dla prawidłowej operacji sprzężenia zewnętrznego: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. Główną właściwością lewego i prawego sprzężenia zewnętrznego jest to, że zezwalają przywrócić początkowy argument relacji zgodnie z końcowym wynikiem konkretnej operacji złączenia, tj. wykonywane są następujące czynności: 1) dla operacji sprzężenia zewnętrznego lewego: r1(S1) = (r1 →x P r2) [S1]; 2) dla prawidłowej operacji sprzężenia zewnętrznego: r2(S2) = (r1 ←x P r2) [S2]. Widzimy zatem, że pierwszy oryginalny operand relacji może zostać przywrócony z wyniku operacji złączenia lewo-prawo, a dokładniej, przez zastosowanie do wyniku tego złączenia (r1 xr2) jednoargumentowa operacja rzutowania na schemat S1,[S1]. I podobnie, drugi pierwotny operand relacji może zostać przywrócony przez zastosowanie prawego sprzężenia zewnętrznego (r1 xr2) jednoargumentowa operacja rzutowania na schemat relacji S2. Podajmy przykład bardziej szczegółowego rozważenia operacji lewego i prawego sprzężenia zewnętrznego. Przedstawmy znane już relacje r1(S1) i r2(S2) z różnymi schematami relacji: r1(S1):
r2(S2):
Niepołączalna krotka lewej relacji-operandu r2(S2) jest krotką {d, 4}. Zgodnie z definicją to oni powinni uzupełnić wynik wewnętrznego połączenia dwóch początkowych relacji-argumentów. Warunek sprzężenia wewnętrznego relacji r1(S1) i r2(S2) również zostawiamy to samo: P = (b1 = b2). Następnie wynik operacji lewe sprzężenie zewnętrzne pojawi się następująca tabela: r1(S1) →x P r2(S2):
Rzeczywiście, jak widzimy, w wyniku działania lewego sprzężenia zewnętrznego wynik operacji sprzężenia wewnętrznego został uzupełniony o niełączne krotki lewego, tj. w naszym przypadku pierwszą relację- argument. Uzupełnianie krotki w schemacie drugiego (prawego) źródłowego argumentu relacji z definicji następowało za pomocą wartości Null. I podobny do wyniku prawe sprzężenie zewnętrzne tak samo jak poprzednio, warunek P = (b1 = b2) pierwotnych relacji-argumentów r1(S1) i r2(S2) to poniższa tabela: r1(S1) ←x P r2(S2):
Rzeczywiście, w tym przypadku wynik operacji złączenia wewnętrznego powinien zostać uzupełniony krotkami niemożliwymi do złączenia, w naszym przypadku drugim początkowym operandem relacji. Taka krotka, jak nietrudno zauważyć, w drugiej relacji r2(S2) jeden, mianowicie {2, y}. Następnie działamy na definicji operacji prawego sprzężenia zewnętrznego, uzupełniamy krotkę pierwszego (lewego) operandu w schemacie pierwszego operandu wartościami Null. Na koniec spójrzmy na trzecią wersję powyższych operacji łączenia. Pełna operacja łączenia zewnętrznego. Tę operację można uznać nie tylko za operację pochodną operacji sprzężenia wewnętrznego, ale także jako sumę operacji sprzężenia zewnętrznego lewego i prawego. Pełna operacja łączenia zewnętrznego jest definiowana jako wynik uzupełnienia tego samego sprzężenia wewnętrznego (jak w przypadku definicji lewego i prawego sprzężenia zewnętrznego) niepołączonymi krotkami zarówno lewego, jak i prawego początkowego połączenia operandu. Na podstawie tej definicji podajemy formułę tej definicji: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ (r1 ←x P r2); Pełna operacja sprzężenia zewnętrznego ma również właściwość podobną do operacji lewego i prawego sprzężenia zewnętrznego. Tylko ze względu na pierwotny wzajemny charakter operacji pełnego sprzężenia zewnętrznego (w końcu została ona zdefiniowana jako suma operacji lewego i prawego sprzężenia zewnętrznego), wykonuje własność przemienności: r1(S1) ↔x P r2(S2)=r2(S2) ↔ x P r1(S1); Aby zakończyć rozważanie opcji dla operacji sprzężenia, spójrzmy na przykład ilustrujący operację pełnego sprzężenia zewnętrznego. Wprowadzamy dwie relacje r1(S1) i r2(S2) i warunek sprzężenia. Pozwól r1(S1)
r2(S2):
I niech warunek połączenia relacji r1(S1) i r2(S2) będzie: P = (b1 = b2), jak w poprzednich przykładach. Wtedy wynik operacji pełnego sprzężenia zewnętrznego relacji r1(S1) i r2(S2) przy warunku P = (b1 = b2) będzie następująca tabela: r1(S1) ↔x P r2(S2):
Widzimy więc, że pełna operacja sprzężenia zewnętrznego jasno uzasadnia swoją definicję jako sumę wyników operacji lewego i prawego sprzężenia zewnętrznego. Wynikowa relacja operacji sprzężenia wewnętrznego jest uzupełniana przez jednocześnie niepołączalne krotki jako lewe (pierwsze, r1(S1)) i w prawo (drugi, r2(S2)) oryginalnego operandu relacji. 5. Operacje pochodne Rozważaliśmy więc różne warianty operacji łączenia, a mianowicie operacje łączenia wewnętrznego, łączenia lewego, prawego i pełnego zewnętrznego, które są pochodnymi ośmiu pierwotnych operacji algebry relacyjnej: jednoargumentowych operacji wyboru, rzutowania, zmiany nazwy i operacji binarnych zjednoczenie, przecięcie, różnica, iloczyn kartezjański i połączenie naturalne. Ale nawet wśród tych oryginalnych operacji są przykłady operacji pochodnych. 1. Na przykład operacja skrzyżowania dwa stosunki jest pochodną działania różnicy tych samych dwóch stosunków. Pokażmy to. Operację skrzyżowania można wyrazić następującym wzorem: r1(S)∩r2(S) = r1 \r1 \r2 lub, co daje ten sam wynik: r1(S)∩r2(S) = r2 \r2 \r1; 2. Innym przykładem operacji bazowej wywodzącej się z ośmiu oryginalnych operacji jest operacja naturalne połączenie. W swojej najbardziej ogólnej postaci operacja ta wywodzi się z operacji binarnej iloczynu kartezjańskiego i jednoargumentowych operacji wybierania, rzutowania i zmiany nazwy atrybutów. Jednak z kolei operacja złączenia wewnętrznego jest operacją pochodną tej samej operacji iloczynu kartezjańskiego relacji. Dlatego, aby pokazać, że operacja sprzężenia naturalnego jest operacją pochodną, rozważmy następujący przykład. Porównajmy poprzednie przykłady operacji sprzężenia naturalnego i sprzężenia wewnętrznego. Daj nam dwie relacje r1(S1) i r2(S2), które będą działać jako operandy. Są równe: r1(S1):
r2(S2):
Jak już wcześniej otrzymaliśmy, wynikiem działania naturalnego złączenia tych relacji będzie tablica o następującej postaci: r3(S3) ≔ r1(S1) x r2(S2):
I wynik wewnętrznego sprzężenia tych samych relacji r1(S1) i r2(S2) przy warunku P = (b1 = b2) będzie następująca tabela: r4(S4) ≔ r1(S1) X P r2(S2):
Porównajmy te dwa wyniki, powstałe nowe relacje r3(S3) i r4(S4). Oczywiste jest, że operacja złączenia naturalnego jest wyrażana przez operację złączenia wewnętrznego, ale, co najważniejsze, z warunkiem złączenia o specjalnej formie. Napiszmy wzór matematyczny, który opisuje działanie operacji sprzężenia naturalnego jako pochodną operacji sprzężenia wewnętrznego. r1(S1) x r2(S2) = { ρ<ϕ1>R1 x E ρ<ϕ2>r2}[S1 S2], gdzie E - stan połączenia krotki; E= ∀a ∈S1 S2 [IsNull(b1) & IsNull(2) ∪b1 = b2]; b1 =1 (nazwa(a)), b2 =2 (Nazwij)); Oto jeden z zmiana nazw funkcji ϕ1 jest identyczna i inna funkcja zmiany nazwy (mianowicie ϕ2) zmienia nazwy atrybutów, w których przecinają się nasze schematy. Warunek łączności E dla krotek jest zapisany w formie ogólnej, z uwzględnieniem możliwego wystąpienia wartości Null, ponieważ operacja złączenia wewnętrznego (jak wspomniano powyżej) jest operacją pochodną z iloczynu kartezjańskiego dwóch relacji i operacji jednoargumentowego wyboru. 6. Wyrażenia algebry relacyjnej Pokażmy, jak rozważane wcześniej wyrażenia i operacje algebry relacyjnej można wykorzystać w praktycznym działaniu różnych baz danych. Niech na przykład mamy do dyspozycji fragment jakiejś komercyjnej bazy danych: Dostawcy (Kod dostawcy, nazwa dostawcy, miasto dostawcy); Narzędzia (Kod narzędzia, Имя инструмента,...); Dostawy (Kod dostawcy, kod części); Podkreślone nazwy atrybutów[1] są kluczowymi (tj. identyfikującymi) atrybutami, każdy w swojej własnej relacji. Załóżmy, że my, jako twórcy tej bazy danych i przechowujący informacje w tej sprawie, jesteśmy zobowiązani do uzyskania nazw dostawców (Supplier Name) i ich lokalizacji (Supplier City) w przypadku, gdy dostawcy ci nie dostarczają żadnych narzędzi ogólna nazwa „szczypce”. W celu określenia wszystkich dostawców spełniających to wymaganie w naszej możliwie bardzo dużej bazie danych, piszemy kilka wyrażeń algebry relacyjnej. 1. Tworzymy naturalne połączenie relacji „Dostawcy” i „Dostawcy” w celu dopasowania do każdego dostawcy kodów dostarczanych przez niego części. Nową relację - wynik zastosowania operacji łączenia naturalnego - dla wygody dalszej aplikacji oznaczamy r1. Поставщики x Поставки ≔ r1 (Kod dostawcy, nazwa dostawcy, miasto dostawcy, W nawiasach wymieniliśmy wszystkie atrybuty relacji biorących udział w tej operacji łączenia naturalnego. Widzimy, że atrybut „Vendor ID” jest zduplikowany, ale w rekordzie podsumowania transakcji każda nazwa atrybutu powinna pojawić się tylko raz, czyli: Поставщики x Поставки ≔ r1 (kod dostawcy, nazwa dostawcy, miasto dostawcy, kod przyrządu); 2. ponownie tworzymy naturalny związek, tylko tym razem związek uzyskany w akapicie pierwszym i relację Instrumenty. Robimy to, aby dopasować nazwę tego narzędzia do każdego kodu narzędzia uzyskanego w poprzednim akapicie. r1 x Инструменты [Код инструмента, Имя инструмента] ≔ r2 (Kod dostawcy, nazwa dostawcy, miasto dostawcy, Otrzymany wynik będzie oznaczony r2, zduplikowane atrybuty są wykluczone: r1 x Инструменты [Код инструмента, Имя инструмента] ≔ r2 (kod dostawcy, nazwa dostawcy, miasto dostawcy, kod przyrządu, nazwa przyrządu); Zauważ, że bierzemy tylko dwa atrybuty z relacji Narzędzia: "Kod narzędzia" i "Nazwa narzędzia". Aby to zrobić, my, jak widać z zapisu relacji r2, zastosował operację odwzorowania jednoargumentowego: Narzędzia [Kod narzędzia, Nazwa narzędzia], tj. jeśli relacja Narzędzia byłaby przedstawiona jako tabela, wynikiem tej operacji odwzorowania byłyby dwie pierwsze kolumny z nagłówkami „Kod narzędzia” i „Narzędzie nazwa "odpowiednio". Warto zauważyć, że pierwsze dwa kroki, które już rozważyliśmy, są dość ogólne, to znaczy, że można je wykorzystać do realizacji dowolnych innych żądań. Ale kolejne dwa punkty z kolei reprezentują konkretne kroki w celu osiągnięcia konkretnego zadania, jakie przed nami postawiono. 3. Napisz jednoargumentową operację wyboru według warunku <"Nazwa narzędzia" = "Szczypce"> w odniesieniu do stosunku r2uzyskane w poprzednim akapicie. A my z kolei stosujemy jednoargumentową operację projekcji [Supplier Code, Supplier Name, Supplier City] do wyniku tej operacji, aby uzyskać wszystkie wartości tych atrybutów, ponieważ musimy uzyskać te informacje na podstawie zamówienie. Tak więc: (σ<Nazwa narzędzia = "Szczypce"> r2) [Kod dostawcy, nazwa dostawcy, miasto dostawcy] ≔ r3 (Kod dostawcy, nazwa dostawcy, miasto dostawcy, kod narzędzia, nazwa narzędzia). W otrzymanym stosunku, oznaczonym przez r3, tylko ci dostawcy (ze wszystkimi swoimi danymi identyfikacyjnymi) okazali się dostarczać narzędzia o ogólnej nazwie „szczypce”. Ale na mocy zamówienia musimy wyróżnić tych dostawców, którzy wręcz przeciwnie nie dostarczają takich narzędzi. Przejdźmy zatem do kolejnego kroku naszego algorytmu i zapiszmy ostatnie wyrażenie algebry relacyjnej, które da nam informacje, których szukamy. 4. Najpierw rozróżniamy relację „Dostawcy” od relacji r3, a po zastosowaniu tej operacji binarnej stosujemy operację projekcji jednoargumentowej na atrybutach „Nazwa dostawcy” i „Miasto dostawcy”. (Dostawcy\r3) [Nazwa dostawcy, miasto dostawcy] ≔ r4 (kod dostawcy, nazwa dostawcy, miasto dostawcy); Wynik jest oznaczony r4, ta relacja zawierała tylko te krotki oryginalnej relacji „Dostawcy”, które odpowiadają stanowi naszego zamówienia. Pokazaliśmy więc, jak za pomocą wyrażeń i operacji algebry relacyjnej można wykonywać wszelkiego rodzaju działania z dowolnymi bazami danych, wykonywać różne rozkazy itp. Wykład nr 6. Język SQL Podajmy najpierw trochę tła historycznego. Język SQL, zaprojektowany do interakcji z bazami danych, pojawił się w połowie lat siedemdziesiątych. (pierwsze publikacje pochodzą z 1970 roku) i został opracowany przez IBM w ramach eksperymentalnego projektu systemu zarządzania relacyjnymi bazami danych. Oryginalna nazwa języka to SEQUEL (Structured English Język zapytań) - tylko częściowo odzwierciedla istotę tego języka. Początkowo, zaraz po jego wynalezieniu iw pierwotnym okresie funkcjonowania języka SQL, jego nazwa była skrótem od frazy Structured Query Language, co tłumaczy się jako „Structured Query Language”. Oczywiście język koncentrował się głównie na wygodnym i zrozumiałym dla użytkowników formułowaniu zapytań do relacyjnych baz danych. Ale w rzeczywistości prawie od samego początku był to kompletny język bazodanowy, zapewniający, oprócz możliwości formułowania zapytań i manipulowania bazami danych, następujące cechy: 1) sposoby definiowania i manipulowania schematem bazy danych; 2) środki do definiowania ograniczeń i wyzwalaczy integralności (o których będzie mowa później); 3) sposób definiowania widoków bazy danych; 4) sposoby definiowania struktur warstwy fizycznej, które wspomagają sprawną realizację żądań; 5) sposoby autoryzacji dostępu do relacji i ich pól. W języku tym brakowało możliwości jawnej synchronizacji dostępu do obiektów bazy danych od strony transakcji równoległych: od samego początku zakładano, że niezbędna synchronizacja jest wykonywana niejawnie przez system zarządzania bazą danych. Obecnie SQL nie jest już skrótem, ale nazwą niezależnego języka. Ponadto, obecnie strukturalny język zapytań jest zaimplementowany we wszystkich komercyjnych systemach zarządzania relacyjnymi bazami danych i prawie we wszystkich DBMS, które pierwotnie nie były oparte na podejściu relacyjnym. Wszystkie firmy produkcyjne twierdzą, że ich implementacja jest zgodna ze standardem SQL, a w rzeczywistości zaimplementowane dialekty Structured Query Language są bardzo zbliżone. Nie osiągnięto tego od razu. Cechą większości nowoczesnych komercyjnych systemów zarządzania bazami danych, która utrudnia porównywanie istniejących dialektów języka SQL, jest brak jednolitego opisu języka. Zazwyczaj opis jest rozproszony w różnych podręcznikach i mieszany z opisem funkcji językowych specyficznych dla systemu, które nie są bezpośrednio związane z ustrukturyzowanym językiem zapytań. Niemniej jednak można powiedzieć, że podstawowy zestaw instrukcji SQL, który zawiera instrukcje do określania schematu bazy danych, pobierania i manipulowania danymi, autoryzacji dostępu do danych, obsługi osadzania SQL w językach programowania oraz dynamicznych instrukcji SQL, jest dobrze ugruntowany w wdrożenia komercyjne i mniej więcej zgodne ze standardem. Z biegiem czasu i pracami nad Structured Query Language udało się osiągnąć standard jasnej standaryzacji składni i semantyki instrukcji pobierania danych, manipulacji danymi i naprawiania ograniczeń integralności bazy danych. Określono sposoby definiowania kluczy podstawowych i obcych relacji oraz tzw. ograniczeń sprawdzania integralności, które są podzbiorem sprawdzanych natychmiastowo ograniczeń integralności SQL. Narzędzia do definiowania kluczy obcych ułatwiają formułowanie wymagań tzw. referencyjnej integralności baz danych (o czym porozmawiamy później). Wymóg ten, powszechny w relacyjnych bazach danych, można by również sformułować na podstawie ogólnego mechanizmu ograniczeń integralności SQL, ale sformułowanie oparte na koncepcji klucza obcego jest prostsze i bardziej zrozumiałe. Biorąc to wszystko pod uwagę, obecnie język zapytań strukturalnych to nie tylko nazwa jednego języka, ale nazwa całej klasy języków, ponieważ pomimo istniejących standardów, zaimplementowane są różne dialekty języka zapytań strukturalnych w różnych systemach zarządzania bazami danych, które oczywiście mają jedną wspólną podstawę. 1. Instrukcja Select jest podstawową instrukcją języka zapytań strukturalnych Centralne miejsce w języku zapytań strukturalnych SQL zajmuje instrukcja Select, która realizuje najbardziej wymaganą operację podczas pracy z bazami danych - zapytania. Operator Select ocenia zarówno relacyjne, jak i pseudorelacyjne wyrażenia algebry. W tym kursie rozważymy implementację tylko jednoargumentowych i binarnych operacji algebry relacyjnej, które już omówiliśmy, a także implementację zapytań z wykorzystaniem tzw. podzapytań. Przy okazji należy zauważyć, że w przypadku pracy z operacjami algebry relacyjnej, w powstałych relacjach mogą pojawić się zduplikowane krotki. Nie ma ścisłego zakazu występowania duplikatów wierszy w relacjach w regułach strukturalnego języka zapytań (w przeciwieństwie do zwykłej algebry relacyjnej), więc nie jest konieczne wykluczanie duplikatów z wyniku. Przyjrzyjmy się więc podstawowej strukturze instrukcji Select. Jest dość prosty i zawiera następujące standardowe obowiązkowe wyrażenia: Wybierz ... Od ... Where... ; W miejsce wielokropka w każdej linii powinny być relacje, atrybuty i warunki danej bazy danych oraz zadania dla niej. W najbardziej ogólnym przypadku podstawowa struktura Select powinna wyglądać tak: Wybierz wybierz kilka atrybutów Cena Od z takiego związku Gdzie z takimi a takimi warunkami próbkowania krotek Wybieramy zatem atrybuty ze schematu powiązań (nagłówki niektórych kolumn), jednocześnie wskazując z jakich relacji (a podobno może być ich kilka) dokonujemy wyboru i wreszcie na podstawie jakich warunków zatrzymujemy nasz wybór niektóre krotki. Należy zauważyć, że odwołania do atrybutów są tworzone przy użyciu ich nazw. W ten sposób uzyskuje się następujące: algorytm pracy ta podstawowa instrukcja Select: 1) zapamiętywane są warunki wyboru krotek z relacji; 2) sprawdza się, które krotki spełniają określone właściwości. Takie krotki są zapamiętywane; 3) wyprowadzane są atrybuty wymienione w pierwszym wierszu podstawowej struktury instrukcji Select wraz z ich wartościami. (Jeśli mówimy o tabelarycznej formie relacji, to zostaną wyświetlone te kolumny tabeli, których nagłówki zostały wymienione jako niezbędne atrybuty; oczywiście kolumny nie zostaną wyświetlone w całości, w każdej z nich tylko te krotki które spełniły wymienione warunki, pozostaną.) Rozważmy przykład. Daj nam następującą relację r1, jako fragment jakiejś księgarni:
Otrzymajmy również następujące wyrażenie z instrukcją Select: Wybierz Tytuł książki, Autor książki Cena Od r1 Gdzie Cena książki > 200; Wynikiem tego operatora będzie następujący fragment krotki: (Telefon komórkowy, S. King). (W dalszej części rozważymy wiele przykładów implementacji zapytań wykorzystujących tę podstawową strukturę i szczegółowo przeanalizujemy jej zastosowanie). 2. Operacje jednoargumentowe w ustrukturyzowanym języku zapytań W tej sekcji rozważymy, w jaki sposób znane już jednoargumentowe operacje wyboru, projekcji i zmiany nazwy są implementowane w ustrukturyzowanym języku zapytań przy użyciu operatora Select. Należy zauważyć, że jeśli wcześniej mogliśmy pracować tylko z pojedynczymi operacjami, to nawet pojedyncza instrukcja Select w ogólnym przypadku pozwala nam zdefiniować całe wyrażenie algebry relacyjnej, a nie tylko jedną operację. Przejdźmy więc bezpośrednio do analizy reprezentacji operacji jednoargumentowych w języku zapytań strukturalnych. 1. Операция выборки. Operacja wyboru w SQL jest realizowana przez instrukcję Select o następującej postaci: Wybierz wszystkie atrybuty Cena Od nazwa relacji Gdzie warunek wyboru; Tutaj zamiast pisać "wszystkie atrybuty", możesz użyć znaku "*". W strukturalnej teorii języka zapytań ta ikona oznacza wybranie wszystkich atrybutów ze schematu relacji. Warunek wyboru tutaj (i we wszystkich innych implementacjach operacji) jest zapisany jako wyrażenie logiczne ze standardowymi spójnikami not (not) i (i) lub (or). Atrybuty relacji są określane przez ich nazwy. Rozważ przykład. Zdefiniujmy następujący schemat relacji: wyniki w nauce (Numer dziennika ocen, semestr, kod przedmiotu, Ocena, Data); Tutaj, jak wspomniano wcześniej, podkreślone atrybuty tworzą klucz relacji. Skomponujmy instrukcję Select o następującej postaci, która implementuje jednoargumentową operację wyboru: Wybierz * Od wyników w nauce Gdzie Gradebook # = 100 i Semestr = 6; Oczywiste jest, że w wyniku tego operatora maszyna wyświetli postępy studenta z numerem rekordu stu na szóstym semestrze. 2. Операция проекции. Operacja projekcji w Structured Query Language jest jeszcze łatwiejsza do zaimplementowania niż operacja pobierania. Przypomnijmy, że podczas stosowania operacji rzutowania nie są wybierane wiersze (jak podczas stosowania operacji zaznaczania), ale kolumny. Dlatego wystarczy wymienić nagłówki wymaganych kolumn (tj. nazwy atrybutów) bez określania żadnych dodatkowych warunków. W sumie otrzymujemy operator o następującej postaci: Wybierz lista nazw atrybutów Cena Od nazwa relacji; Po zastosowaniu tej instrukcji maszyna zwróci te kolumny tabeli relacji, których nazwy zostały określone w pierwszym wierszu instrukcji Select. Jak wspomnieliśmy wcześniej, nie jest konieczne wykluczanie zduplikowanych wierszy i kolumn z wynikowej relacji. Ale jeśli w zamówieniu lub zadaniu wymagane jest wyeliminowanie duplikatów, należy skorzystać ze specjalnej opcji języka zapytań strukturalnych - odrębny. Ta opcja ustawia automatyczną eliminację zduplikowanych krotek z relacji. Po zastosowaniu tej opcji instrukcja Select będzie wyglądać tak: Wybierz odrębna lista nazw atrybutów Cena Od nazwa relacji; В языке SQL существует специальное обозначение для необязательных элементов выражений - квадратные скобки [...]. Поэтому в самом общем виде операция проекции будет выглядеть следующим образом: Wybierz [wyraźna] lista nazw atrybutów Cena Od nazwa relacji; Jeśli jednak wynik zastosowania operacji gwarantuje, że nie będzie zawierał duplikatów lub duplikaty są nadal dopuszczalne, wówczas opcja odrębny lepiej nie precyzować, aby nie zaśmiecać rekordu, np. ze względu na wydajność operatora. Rozważmy przykład ilustrujący możliwość XNUMX% pewności w przypadku braku duplikatów. Niech zostanie podany znany nam schemat relacji: wyniki w nauce (Numer dziennika ocen, semestr, kod przedmiotu, Ocena, Data). Niech zostanie podana następująca instrukcja Select: Wybierz Numer dziennika ocen, semestr, kod przedmiotu Cena Od wyniki w nauce; Tutaj łatwo zauważyć, że trzy atrybuty zwracane przez operator tworzą klucz relacji. Dlatego opcja odrębny staje się zbędne, ponieważ gwarantuje brak duplikatów. Wynika to z wymogu dotyczącego kluczy zwanego ograniczeniem unikalnym. Właściwość tę rozważymy bardziej szczegółowo później, ale jeśli atrybut jest kluczem, nie ma w nim duplikatów. 3. Операция переименования. Operacja zmiany nazwy atrybutów w ustrukturyzowanym języku zapytań jest dość prosta. Mianowicie ucieleśnia go w rzeczywistości następujący algorytm: 1) na liście nazw atrybutów frazy Select wymienione są te atrybuty, które wymagają zmiany nazwy; 2) specjalne słowo kluczowe as jest dodawane do każdego określonego atrybutu; 3) po każdym wystąpieniu słowa as wskazuje się nazwę odpowiedniego atrybutu, na który należy zmienić oryginalną nazwę. Zatem biorąc pod uwagę wszystkie powyższe, zdanie odpowiadające operacji zmiany nazwy atrybutów będzie wyglądać tak: Wybierz имя атрибута 1 as новое имя атрибута 1,... Cena Od nazwa relacji; Pokażmy na przykładzie, jak działa ten operator. Niech schemat relacji, który już nam znamy, zostanie podany: wyniki w nauce (Numer dziennika ocen, semestr, kod przedmiotu,Ocena, Data); Zróbmy polecenie zmiany nazw niektórych atrybutów, mianowicie zamiast "Numer księgi rachunkowej" powinno być "Numer rachunku" a zamiast "Wynik" - "Wynik". Zapiszmy, jak będzie wyglądać instrukcja Select, która implementuje tę operację zmiany nazwy: Wybierz Dziennik ocen jako numer dziennika ocen, semestr, kod przedmiotu, ocena jako wynik, data Cena Od wyniki w nauce; W związku z tym wynikiem zastosowania tego operatora będzie nowy schemat relacji, który różni się od oryginalnego schematu relacji „Osiągnięcie” nazwami dwóch atrybutów. 3. Operacje binarne w języku zapytań strukturalnych Podobnie jak operacje jednoargumentowe, operacje binarne mają również własną implementację w ustrukturyzowanym języku zapytań lub SQL. Rozważmy więc implementację w tym języku operacji binarnych, które już przeszliśmy, a mianowicie operacje sumy, przecięcia, różnicy, iloczynu kartezjańskiego, sprzężenia naturalnego, sprzężenia wewnętrznego i lewego, prawego, pełnego sprzężenia zewnętrznego. 1. Операция объединения. W celu realizacji operacji łączenia dwóch relacji konieczne jest jednoczesne użycie dwóch operatorów Select, z których każdy odpowiada jednemu z pierwotnych relacji-operandów. Do tych dwóch podstawowych instrukcji Select należy zastosować specjalną operację Unia. Biorąc pod uwagę wszystkie powyższe, zapiszmy, jak będzie wyglądała operacja łączenia przy użyciu semantyki ustrukturyzowanego języka zapytań: Wybierz lista nazw atrybutów relacji 1 Cena Od nazwa relacji 1 Unia Wybierz lista nazw atrybutów relacji 2 Cena Od nazwa relacji 2; Należy zauważyć, że listy nazw atrybutów dwóch łączonych relacji muszą odwoływać się do atrybutów zgodnych typów i być wymienione w spójnej kolejności. Jeśli to wymaganie nie zostanie spełnione, żądanie nie może zostać spełnione, a komputer wyświetli komunikat o błędzie. Warto jednak zauważyć, że same nazwy atrybutów w tych związkach mogą się różnić. W takim przypadku do wynikowej relacji przypisywane są nazwy atrybutów określone w pierwszej instrukcji Select. Musisz również wiedzieć, że użycie operacji Union automatycznie wyklucza wszystkie zduplikowane krotki z wynikowej relacji. Dlatego, jeśli chcesz, aby wszystkie zduplikowane wiersze zostały zachowane w wyniku końcowym, zamiast operacji Union, powinieneś zastosować modyfikację tej operacji - operację Unia wszystkich. W takim przypadku operacja łączenia dwóch relacji będzie wyglądać tak: Wybierz lista nazw atrybutów relacji 1 Cena Od nazwa relacji 1 Unia wszystkich Wybierz lista nazw atrybutów relacji 2 Cena Od nazwa relacji 2; W takim przypadku zduplikowane krotki nie zostaną usunięte z wynikowej relacji. Wykorzystując wspomnianą wcześniej notację dla elementów opcjonalnych i opcji w instrukcjach Select piszemy najogólniejszą formę operacji łączenia dwóch relacji w ustrukturyzowanym języku zapytań: Wybierz lista nazw atrybutów relacji 1 Cena Od nazwa relacji 1 Unia [Wszystkie] Wybierz lista nazw atrybutów relacji 2 Cena Od nazwa relacji 2; 2. Операция пересечения. Operacja przecięcia i operacja różnicy dwóch relacji w ustrukturyzowanym języku zapytań zaimplementowana jest w podobny sposób (rozważamy najprostszą metodę reprezentacji, ponieważ im prostsza metoda, tym bardziej ekonomiczna, bardziej trafna, a tym samym najbardziej cieszący się popytem). Tak więc przeanalizujemy sposób realizacji operacji skrzyżowania za pomocą Klucze. Ta metoda wiąże się z udziałem dwóch konstrukcji Select, ale nie są one równe (jak w reprezentacji operacji sumowania), jedna z nich jest niejako „podkonstrukcją”, „podcyklem”. Taki operator jest zwykle nazywany podzapytanie. Załóżmy więc, że mamy dwa schematy relacji (R1 i R2), z grubsza zdefiniowane w następujący sposób: R1 (ключ,...) и R2 (ключ,...); Podczas nagrywania tej operacji skorzystamy również z opcji specjalnej in, co dosłownie oznacza „w” lub (jak w tym konkretnym przypadku) „zawarte w”. Tak więc, biorąc pod uwagę wszystkie powyższe, operacja przecięcia dwóch relacji przy użyciu strukturalnego języka zapytań zostanie napisana w następujący sposób: Wybierz * Cena Od R1 Gdzie kluczem (Wybierz ключ Od R2); Widzimy więc, że podzapytanie w tym przypadku będzie operatorem w nawiasach. To podzapytanie w naszym przypadku zwraca listę kluczowych wartości relacji R2. I, jak wynika z naszej notacji operatorów, z analizy warunku wyboru tylko krotki relacji R wpadną w wynikową relację1, którego klucz znajduje się na liście kluczy relacji R2. Oznacza to, że w końcowej relacji, jeśli przypomnimy sobie definicję przecięcia dwóch relacji, pozostaną tylko krotki należące do obu relacji. 3. Операция разности. Jak wspomniano wcześniej, jednoargumentowe działanie różnicy dwóch relacji jest realizowane podobnie do operacji przecięcia. Tutaj oprócz głównego zapytania z operatorem Select stosowane jest drugie, pomocnicze zapytanie – tzw. podzapytanie. Ale w przeciwieństwie do realizacji poprzedniej operacji, podczas realizacji operacji różnicy konieczne jest użycie innego słowa kluczowego, a mianowicie nie w, co w dosłownym tłumaczeniu oznacza „nie w” lub (jak wypada tłumaczyć w naszym rozważanym przypadku) – „nie jest w”. Niech więc, podobnie jak w poprzednim przykładzie, mamy dwa schematy relacji (R1 i R2), w przybliżeniu podane przez: R1 (ключ,...) и R2 (ключ,...); Jak widać, atrybuty kluczowe są ponownie ustawiane wśród atrybutów tych relacji. W ten sposób otrzymujemy następujący formularz do reprezentowania operacji różnicy w ustrukturyzowanym języku zapytań: Wybierz * Cena Od R1 Gdzie ключ nie w (Wybierz ключ Cena Od R2); Zatem tylko te krotki relacji R1, którego klucz nie znajduje się na liście kluczy relacji R2. Jeśli weźmiemy pod uwagę zapis dosłownie, to tak naprawdę okazuje się, że z relacji R1 "odjąłem" stosunek R2. Stąd wnioskujemy, że warunek wyboru w tym operatorze jest napisany poprawnie (przecież dokonywana jest definicja różnicy dwóch relacji), a użycie kluczy, tak jak w przypadku realizacji operacji przecięcia, jest w pełni uzasadnione . Najczęstsze są dwa zastosowania „metody kluczowej”, które widzieliśmy. Na tym kończy się badanie użycia kluczy w konstrukcji operatorów reprezentujących relacje. Wszystkie pozostałe operacje binarne algebry relacyjnej są zapisywane w inny sposób. 4. Działanie kartezjańskiego produktu Jak pamiętamy z poprzednich wykładów, iloczyn kartezjański dwóch argumentów relacji składa się jako zbiór wszystkich możliwych par nazwanych wartości krotek na atrybutach. Dlatego w ustrukturyzowanym języku zapytań operacja produktu kartezjańskiego jest implementowana za pomocą sprzężenia krzyżowego, oznaczanego słowem kluczowym połączenie krzyżowe, co dosłownie tłumaczy się jako „połączenia krzyżowe” lub „połączenia krzyżowe”. W strukturze reprezentującej operację iloczynu kartezjańskiego w Structured Query Language występuje tylko jeden operator Select i ma on następującą postać: Wybierz * Cena Od R1 połączenie krzyżowe R2 Tutaj r1 i R2 - nazwy początkowych relacji-operandów. Opcja połączenie krzyżowe zapewnia, że wynikowa relacja będzie zawierała wszystkie atrybuty (wszystkie, ponieważ pierwszy wiersz operatora zawiera znak „*”) odpowiadający wszystkim parom krotek relacji R1 i R2. Bardzo ważne jest, aby pamiętać o jednej cesze wdrożenia kartezjańskiego działania produktu. Cecha ta jest konsekwencją definicji operacji binarnej iloczynu kartezjańskiego. Przypomnij sobie: r4(S4) = r1(S1) x r2(S2) = {t(S1 S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 S2= ; Jak widać z powyższej definicji, pary krotek są tworzone z koniecznie nie przecinającymi się schematami relacji. Dlatego podczas pracy w strukturalnym języku zapytań SQL niezmiennie obowiązuje wymóg, aby początkowe relacje operandów nie miały zgodnych nazw atrybutów. Ale jeśli te relacje nadal mają te same nazwy, obecną sytuację można łatwo rozwiązać za pomocą operacji zmiany nazwy atrybutu, czyli w takich przypadkach wystarczy użyć opcji as, o którym wspomniano wcześniej. Rozważmy przykład, w którym musimy znaleźć iloczyn kartezjański dwóch relacji, które mają pasujące nazwy atrybutów. Tak więc, biorąc pod uwagę następujące relacje: R1 (A, B), R2 (PNE); Widzimy, że atrybuty R1.B i R2.B mają te same nazwy. Mając to na uwadze, instrukcja Select, która implementuje tę operację produktu kartezjańskiego w ustrukturyzowanym języku zapytań, będzie wyglądać tak: Wybierz A, R1.B as B1, r2.B as B2, C Cena Od R1 połączenie krzyżowe R2; Tak więc, używając opcji rename as, maszyna nie będzie miała „pytań” o pasujące nazwy dwóch oryginalnych relacji operandów. 5. Operacje łączenia wewnętrznego Na pierwszy rzut oka może wydawać się dziwne, że rozważamy operację sprzężenia wewnętrznego przed operacją sprzężenia naturalnego, ponieważ gdy przechodziliśmy przez operacje binarne, wszystko było odwrotnie. Jednak analizując wyrażenia operacji w ustrukturyzowanym języku zapytań, można dojść do wniosku, że operacja złączenia naturalnego jest szczególnym przypadkiem operacji złączenia wewnętrznego. Dlatego racjonalne jest rozpatrywanie tych operacji właśnie w tej kolejności. Więc najpierw przypomnijmy sobie definicję operacji sprzężenia wewnętrznego, którą przeszliśmy wcześniej: r1(S1) X P r2(S2) = σ (r1 xr2), S1 ∩ S2 = . Dla nas w tej definicji szczególnie ważne jest to, że rozważane schematy relacji-argumentów S1 i S2 nie mogą się przecinać. Aby zaimplementować operację sprzężenia wewnętrznego w ustrukturyzowanym języku zapytań, istnieje specjalna opcja połączenie wewnętrzne, co w dosłownym tłumaczeniu z angielskiego oznacza „inner join” lub „inner join”. Instrukcja Select w przypadku operacji sprzężenia wewnętrznego będzie wyglądać tak: Wybierz * Cena Od R1 połączenie wewnętrzne R2; Tutaj, jak poprzednio, R1 i R2 - nazwy początkowych relacji-operandów. Podczas realizacji tej operacji schematy argumentów relacji nie mogą się przecinać. 6. Naturalna operacja łączenia Jak już powiedzieliśmy, operacja złączenia naturalnego jest szczególnym przypadkiem operacji złączenia wewnętrznego. Czemu? Tak, ponieważ podczas akcji łączenia naturalnego krotki pierwotnych relacji operandowych są łączone według specjalnego warunku. Mianowicie, przez warunek równości krotek na przecięciu relacji-argumentów, przy działaniu operacji złączenia wewnętrznego, taka sytuacja nie mogła być dopuszczona. Ponieważ rozważana przez nas operacja złączenia naturalnego jest szczególnym przypadkiem operacji złączenia wewnętrznego, do jej realizacji używana jest ta sama opcja, co w przypadku poprzedniej rozważanej operacji, tj. opcja połączenie wewnętrzne. Skoro jednak przy kompilacji operatora Select dla operacji złączenia naturalnego konieczne jest również uwzględnienie warunku równości krotek pierwotnych relacji operandowych na przecięciu ich schematów, to oprócz wskazanej opcji słowo kluczowe jest stosowany on. Przetłumaczone z angielskiego dosłownie oznacza „włączone”, aw związku z naszym znaczeniem można je przetłumaczyć jako „z zastrzeżeniem”. Ogólna forma instrukcji Select do wykonywania operacji łączenia naturalnego jest następująca: Wybierz * Cena Od nazwa relacji 1 połączenie wewnętrzne nazwa relacji 2 on warunek równości krotek; Rozważmy przykład. Niech podane zostaną dwie relacje: R1 (A, B, C), R2 (B, C, D); Naturalną operację łączenia tych relacji można zaimplementować za pomocą następującego operatora: Wybierz A, R1.B, R1.PŁYTA CD Cena Od R1 połączenie wewnętrzne R2 on R1.B=R2.B i R1.C=R2.C W wyniku tej operacji w wyniku zostaną wyświetlone atrybuty określone w pierwszym wierszu operatora Select, odpowiadające krotkom równym na określonym przecięciu. Należy zauważyć, że odwołujemy się tutaj do wspólnych atrybutów B i C, a nie tylko z nazwy. Trzeba to zrobić nie z tego samego powodu, co w przypadku realizacji operacji produktu kartezjańskiego, ale dlatego, że w przeciwnym razie nie będzie jasne, do której relacji się odnoszą. Co ciekawe, użyte sformułowanie warunku złączenia (R1.B=R2.B i R1.C=R2.C) zakłada, że wspólne atrybuty połączonych relacji o wartości Null są niedozwolone. Jest to od samego początku wbudowane w system Structured Query Language. 7. Lewa operacja łączenia zewnętrznego Wyrażenie SQL struktury zapytania języka operacji lewego sprzężenia zewnętrznego jest uzyskiwane z implementacji operacji sprzężenia naturalnego przez zastąpienie słowa kluczowego wewnętrzny na słowo kluczowe lewy zewnętrzny. Zatem w języku zapytań strukturalnych operacja ta będzie zapisana w następujący sposób: Wybierz * Cena Od nazwa relacji 1 lewe sprzężenie zewnętrzne nazwa relacji 2 on warunek równości krotek; 8. Prawe połączenie zewnętrzne operacji Strukturalne wyrażenie języka zapytań dla operacji prawego sprzężenia zewnętrznego jest uzyskiwane z wykonania operacji sprzężenia naturalnego przez zastąpienie słowa kluczowego wewnętrzny na słowo kluczowe prawo zewnętrzne. Otrzymujemy więc, że w języku zapytań strukturalnych SQL działanie prawego sprzężenia zewnętrznego zostanie zapisane w następujący sposób: Wybierz * Cena Od nazwa relacji 1 prawe sprzężenie zewnętrzne nazwa relacji 2 on warunek równości krotek; 9. Pełna operacja łączenia zewnętrznego Wyrażenie Structured Query Language dla operacji pełnego sprzężenia zewnętrznego jest uzyskiwane, tak jak w poprzednich dwóch przypadkach, z wyrażenia dla operacji sprzężenia naturalnego przez zastąpienie słowa kluczowego wewnętrzny na słowo kluczowe pełny zewnętrzny. Zatem w języku zapytań strukturalnych operacja ta będzie zapisana w następujący sposób: Wybierz * Cena Od nazwa relacji 1 pełne złącze zewnętrzne nazwa relacji 2 on warunek równości krotek; Bardzo wygodne jest, że opcje te są wbudowane w semantykę języka zapytań strukturalnych SQL, ponieważ w przeciwnym razie każdy programista musiałby je wyprowadzać niezależnie i wprowadzać do każdej nowej bazy danych. 4. Korzystanie z podzapytań Jak można zrozumieć z omówionego materiału, pojęcie „podzapytania” w języku ustrukturyzowanych zapytań jest pojęciem podstawowym i ma dość szerokie zastosowanie (czasami, nawiasem mówiąc, są one również nazywane zapytaniami SQL. Rzeczywiście, praktyka programowania i praca z bazami danych pokazuje, że kompilacja systemu podzapytań do rozwiązywania różnych powiązanych zadań - czynność, która jest znacznie bardziej satysfakcjonująca w porównaniu z niektórymi innymi metodami pracy z ustrukturyzowanymi informacjami. Dlatego rozważmy przykład, aby lepiej zrozumieć działania z podzapytaniami, ich kompilację I użyć. Niech będzie następujący fragment pewnej bazy danych, z której można korzystać w każdej instytucji edukacyjnej: Przedmiotów (Kod produktu, Nazwa przedmiotu); Studenci (numer księgi metrykalnej, imię i nazwisko); Sesja (Код предмета, № зачетной книжки, Gatunek); Sformułujmy zapytanie SQL, które zwraca instrukcję wskazującą numer dziennika ocen ucznia, nazwisko i inicjały oraz ocenę z przedmiotu o nazwie „Bazy danych”. Uczelnie muszą otrzymywać takie informacje zawsze i na czas, dlatego poniższe zapytanie jest prawdopodobnie najpopularniejszą jednostką programistyczną korzystającą z takich baz danych. Dla wygody załóżmy dodatkowo, że atrybuty „Nazwisko”, „Imię” i „Patronimiczny” nie dopuszczają wartości Null i nie są puste. Wymóg ten jest całkiem zrozumiały i logiczny, ponieważ pierwszymi danymi dotyczącymi nowego ucznia wprowadzanymi do bazy danych dowolnej instytucji edukacyjnej są dane dotyczące jego nazwiska, imienia i nazwiska. I jest rzeczą oczywistą, że w takiej bazie danych nie może być wpisu, który zawiera dane o uczniu, a jednocześnie jego nazwisko jest nieznane. Należy zauważyć, że atrybut „Nazwa elementu” schematu relacji „Elementy” jest kluczem, więc jak wynika z definicji (więcej na ten temat w dalszej części), wszystkie nazwy elementów są unikatowe. Jest to również zrozumiałe bez wyjaśniania reprezentacji klucza, ponieważ wszystkie przedmioty nauczane w instytucji edukacyjnej muszą mieć i mieć różne nazwy. Teraz, zanim zaczniemy kompilować tekst samego operatora, wprowadzimy dwie funkcje, które przydadzą się nam w dalszej pracy. Najpierw będziemy potrzebować funkcji Trym, jest napisane Trim ("string"), co oznacza, że argumentem tej funkcji jest łańcuch. Do czego służy ta funkcja? Zwracają sam argument bez spacji na początku i na końcu tej linii, tj. funkcja ta jest używana na przykład w przypadkach: Trim ("Bogucharnikov") lub Trim ("Maksimenko"), gdy po lub przed argumentami są warte kilka dodatkowych miejsc. Po drugie, konieczne jest również uwzględnienie funkcji Left, która jest napisana Left (ciąg, liczba), tj. Funkcja ma już dwa argumenty, z których jeden jest, jak poprzednio, ciągiem. Drugim argumentem jest liczba, która wskazuje, ile znaków z lewej strony ciągu powinno zostać wypisanych w wyniku. Na przykład wynik operacji: Lewo („Michaił, 1”) + „”. + Lewo ("Zinowicz, 1") będą inicjały „M.Z.” To do wyświetlenia inicjałów uczniów użyjemy tej funkcji w naszym zapytaniu. Zacznijmy więc kompilować żądane zapytanie. Najpierw zróbmy małe zapytanie pomocnicze, którego następnie użyjemy w zapytaniu głównym, głównym: Wybierz Numer dziennika ocen, klasa Cena Od Sesja Gdzie Kod towaru = (Wybierz Kod produktu Cena Od obiekty Gdzie Nazwa elementu = "Bazy danych") as "Szacunki" Bazy danych "; Użycie tutaj opcji jako oznacza, że mamy alias na to zapytanie "Oszacowania bazy danych". Zrobiliśmy to dla wygody dalszej pracy z tą prośbą. Następnie w tym zapytaniu podzapytanie: Wybierz Kod produktu Cena Od obiekty Gdzie Nazwa elementu = "Bazy danych"; pozwala wybrać z relacji „Sesja” te krotki, które odnoszą się do rozważanego tematu, czyli do baz danych. Co ciekawe, to wewnętrzne podzapytanie może zwrócić tylko jedną wartość, ponieważ atrybut „Nazwa elementu” jest kluczem relacji „Pozycje”, czyli wszystkie jego wartości są unikalne. Całe zapytanie „Wyniki „Baza danych” pozwala wybrać z relacji „Sesje” dane dotyczące tych uczniów (ich numery dziennika ocen i oceny), które spełniają warunek określony w podzapytaniu, tj. informacje o przedmiocie o nazwie „Baza danych”. Teraz wykonamy główne żądanie, korzystając z już otrzymanych wyników. Wybierz Studenci. numer księgi metrykalnej, Trym (Nazwisko) + „ ” + Lewa (Nazwa, 1) + "." + Lewa (Patronimiczny, 1) + "."as Imię i nazwisko, Szacunki „Bazy danych”. Gatunek Cena Od studentów połączenie wewnętrzne ( Wybierz Numer dziennika ocen, klasa Cena Od Sesja Gdzie Kod towaru = (Wybierz Kod produktu Cena Od obiekty Gdzie Nazwa elementu = "Bazy danych") ) tak jak „Szacunki” Bazy danych”. on Studenci. Dziennik ocen # = Oceny z bazy danych. Numer księgi rekordów. Tak więc najpierw wymieniamy atrybuty, które będą musiały zostać wyświetlone po zakończeniu zapytania. Należy wspomnieć, że atrybut „Numer dziennika ocen” pochodzi z relacji Uczniowie, stąd atrybuty „Nazwisko”, „Imię” i „Patronimiczny”. To prawda, że ostatnie dwa atrybuty nie są w pełni wydedukowane, ale tylko pierwsze litery. Wspominamy również o atrybucie „Wynik” z zapytania „Wynik bazy danych”, które wprowadziliśmy wcześniej. Wszystkie te atrybuty wybieramy z połączenia wewnętrznego relacji „Studenci” i zapytania „Oceny bazy danych”. To sprzężenie wewnętrzne, jak widać, jest przez nas przyjmowane pod warunkiem równości numerów księgi metrykalnej. W wyniku tej operacji łączenia wewnętrznego oceny są dodawane do relacji Uczniowie. Należy zauważyć, że ponieważ atrybuty „Nazwisko”, „Imię” i „Patronimiczny” według warunku nie zezwalają na wartości zerowe i nie są puste, formuła obliczeniowa zwraca atrybut „Nazwa” (Trym (Nazwisko) + „ ” + Lewa (Nazwa, 1) + "." + Lewa (Patronimiczny, 1) + "."as Imię i nazwisko), odpowiednio, nie wymaga dodatkowych kontroli, jest uproszczone. Wykład nr 7. Podstawowe relacje Jak już wiemy, bazy danych są swego rodzaju kontenerem, którego głównym celem jest przechowywanie danych prezentowanych w postaci relacji. Musisz wiedzieć, że w zależności od charakteru i struktury relacje dzielą się na: 1) podstawowe relacje; 2) виртуальные отношения. Relacje widoku podstawowego zawierają tylko niezależne dane i nie mogą być wyrażane w kategoriach innych relacji bazy danych. W komercyjnych systemach zarządzania bazami danych podstawowe relacje są zwykle określane po prostu jako stoły w przeciwieństwie do reprezentacji odpowiadających pojęciu relacji wirtualnych. Na tym kursie rozważymy szczegółowo tylko podstawowe relacje, główne techniki i zasady pracy z nimi. 1. Podstawowe typy danych Typy danych, takie jak relacje, dzielą się na podstawowy и wirtualny. (O wirtualnych typach danych omówimy nieco później; temu tematowi poświęcimy osobny rozdział.) Podstawowe typy danych - są to dowolne typy danych, które są wstępnie zdefiniowane w systemach zarządzania bazami danych, czyli domyślnie tam obecne (w przeciwieństwie do typu danych zdefiniowanego przez użytkownika, który przeanalizujemy od razu po przejściu przez bazowy typ danych). Zanim przejdziemy do rozważenia rzeczywistych podstawowych typów danych, wymieniamy ogólnie, jakie typy danych występują: 1) dane liczbowe; 2) dane logiczne; 3) dane tekstowe; 4) dane określające datę i godzinę; 5) dane identyfikacyjne. Domyślnie systemy zarządzania bazami danych wprowadziły kilka najpopularniejszych typów danych, z których każdy należy do jednego z wymienionych typów danych. Zadzwońmy do nich. 1. w liczbowy rozróżnia się typ danych: 1) Liczba całkowita. To słowo kluczowe zwykle oznacza typ danych typu integer; 2) Real, odpowiadający rzeczywistemu typowi danych; 3) Dziesiętny (n, m). To jest dziesiętny typ danych. Co więcej, w zapisie n jest liczbą, która określa całkowitą liczbę cyfr liczby, a m pokazuje, ile ich znaków znajduje się po przecinku; 4) Pieniądze lub Waluta, wprowadzone specjalnie w celu wygodnej reprezentacji danych typu monetarnego. 2. w logiczny typ danych zwykle przydziela tylko jeden typ podstawowy, jest to Logiczny. 3. Strunowy typ danych ma cztery podstawowe typy (czyli oczywiście te najczęściej spotykane): 1) Bit(n). Są to ciągi bitów o stałej długości n; 2) Warbit(n). Są to również ciągi bitów, ale o zmiennej długości nieprzekraczającej n bitów; 3) Znak(n). Są to ciągi znaków o stałej długości n; 4) Varchar(n). Są to ciągi znaków o zmiennej długości nieprzekraczającej n znaków. 4. Typ data i godzina obejmuje następujące podstawowe typy danych: 1) Data - typ danych daty; 2) Czas - typ danych wyrażający porę dnia; 3) Data-czas to typ danych, który wyraża zarówno datę, jak i godzinę. 5. Identyfikacja Typ danych zawiera tylko jeden typ zawarty domyślnie w systemie zarządzania bazą danych, czyli GUID (Globally Unique Identifier). Należy zauważyć, że wszystkie podstawowe typy danych mogą mieć warianty różnych zakresów reprezentacji danych. Na przykład warianty czterobajtowego typu danych całkowitych mogą być ośmiobajtowymi (bigint) i dwubajtowymi (małymi) typami danych. Porozmawiajmy osobno o podstawowym typie danych GUID. Ten typ przeznaczony jest do przechowywania szesnastobajtowych wartości tzw. globalnie unikalnego identyfikatora. Wszystkie różne wartości tego identyfikatora są generowane automatycznie po wywołaniu specjalnej wbudowanej funkcji Nowy identyfikator(). To oznaczenie pochodzi od pełnej angielskiej frazy New Identification, która dosłownie oznacza „nową wartość identyfikatora”. Każda wartość identyfikatora generowana na określonym komputerze jest unikatowa na wszystkich wyprodukowanych komputerach. Identyfikator GUID służy w szczególności do organizowania replikacji bazy danych, czyli tworzenia kopii niektórych istniejących baz danych. Takie identyfikatory GUID mogą być używane przez programistów baz danych wraz z innymi podstawowymi typami. Pośrednią pozycję pomiędzy typem GUID a innymi typami bazowymi zajmuje inny specjalny typ bazowy - typ licznik. Do oznaczenia danych tego typu używane jest specjalne słowo kluczowe. Licznik(x0, x), co dosłownie tłumaczy z angielskiego i oznacza „licznik”. Parametr x0 ustawia wartość początkową, a ∆x - krok przyrostu. Wartości tego typu Licznika są koniecznie liczbami całkowitymi. Należy zauważyć, że praca z tym podstawowym typem danych zawiera szereg bardzo interesujących funkcji. Na przykład wartości tego typu Licznik nie są ustawione, jak przywykliśmy do pracy ze wszystkimi innymi typami danych, są generowane na żądanie, podobnie jak dla wartości typu globalnie unikalnego identyfikatora. Niezwykłe jest również to, że typ licznika można określić tylko podczas definiowania tabeli i tylko wtedy! Tego typu nie można używać w kodzie. Należy również pamiętać, że przy definiowaniu tabeli typ licznika można określić tylko dla jednej kolumny. Wartości danych licznika są generowane automatycznie po wstawieniu wierszy. Co więcej, to generowanie odbywa się bez powtórzeń, dzięki czemu licznik zawsze jednoznacznie identyfikuje każdą linię. Stwarza to jednak pewne niedogodności podczas pracy z tabelami zawierającymi dane liczników. Jeśli np. zmienią się dane w relacji podanej przez tabelę i trzeba je usunąć lub zamienić, wartości liczników mogą łatwo „pomylić karty”, zwłaszcza jeśli pracuje niedoświadczony programista. Podajmy przykład ilustrujący taką sytuację. Niech podana zostanie poniższa tabela przedstawiająca jakąś relację, w której wpisuje się cztery wiersze:
Licznik automatycznie nadawał każdej nowej linii unikalną nazwę. A teraz usuńmy drugą i czwartą linię z tabeli, a następnie dodajmy jedną dodatkową linię. Te operacje spowodują następujące przekształcenie tabeli źródłowej:
W ten sposób licznik usunął drugą i czwartą linię wraz z ich unikalnymi nazwami i nie „przepisał” ich do nowych linii, jak można by się spodziewać. Co więcej, system zarządzania bazą danych nigdy nie pozwoli na ręczną zmianę wartości licznika, podobnie jak nie pozwoli na jednoczesne zadeklarowanie kilku liczników w jednej tabeli. Zazwyczaj licznik jest używany jako surogat, czyli sztuczny klucz w tabeli. Warto wiedzieć, że unikalne wartości czterobajtowego licznika z szybkością generowania jednej wartości na sekundę przetrwają ponad 100 lat. Pokażmy, jak to jest obliczane: 1 rok = 365 dni * 24 h * 60 s * 60 s < 366 dni * 24 h * 60 s * 60 s < 225 s. 1 sekunda > 2-25 rok. 24*8 wartości / 1 wartość/sekundę = 232 c > 27 rok > 100 lat. 2. Niestandardowy typ danych Niestandardowy typ danych różni się od wszystkich typów podstawowych tym, że nie był pierwotnie wbudowany w system zarządzania bazą danych, ani nie został zadeklarowany jako domyślny typ danych. Ten typ może stworzyć dowolny użytkownik i programista baz danych zgodnie z własnymi żądaniami i wymaganiami. Zatem typ danych zdefiniowany przez użytkownika jest podtypem pewnego typu podstawowego, to znaczy jest typem podstawowym z pewnymi ograniczeniami dotyczącymi zestawu dozwolonych wartości. W notacji pseudokodowej niestandardowy typ danych jest tworzony przy użyciu następującej standardowej instrukcji: Utwórz podtyp nazwa podtypu Rodzaj Nieruchomości nazwa typu podstawowego As ograniczenie podtypu; Czyli w pierwszym wierszu musimy podać nazwę naszego nowego, zdefiniowanego przez użytkownika typu danych, w drugim - który z istniejących podstawowych typów danych przyjęliśmy jako model, tworząc własny, a w trzecim - te ograniczenia, które musimy dodać do istniejących ograniczeń na zestaw wartości bazowego typu danych - próbka. Ograniczenia podtypów są zapisywane jako warunek zależny od nazwy definiowanego podtypu. Aby lepiej zrozumieć, jak działa instrukcja Create, rozważmy następujący przykład. Załóżmy, że musimy stworzyć własny wyspecjalizowany typ danych, na przykład do pracy w poczcie. Będzie to typ do pracy z danymi, takimi jak numery kodów pocztowych. Nasze liczby będą się różnić od zwykłych sześciocyfrowych liczb dziesiętnych tym, że mogą być tylko dodatnie. Napiszmy operator, aby utworzyć podtyp, którego potrzebujemy: Utwórz podtyp Kod pocztowy Rodzaj Nieruchomości dziesiętny(6, 0) As Kod pocztowy > 0. Dlaczego wybraliśmy dziesiętny(6, 0)? Przypominając zwykłą formę indeksu, widzimy, że takie liczby muszą składać się z sześciu liczb całkowitych od zera do dziewięciu. Dlatego przyjęliśmy typ dziesiętny jako podstawowy typ danych. Warto zauważyć, że ogólnie warunek nałożony na bazowy typ danych, tj. ograniczenie podtypu, może zawierać spójniki logiczne nie i, lub, ogólnie rzecz biorąc, być wyrazem dowolnej złożoności. Zdefiniowane w ten sposób niestandardowe podtypy danych mogą być swobodnie używane wraz z innymi podstawowymi typami danych zarówno w kodzie programu, jak i przy definiowaniu typów danych w kolumnach tabeli, tj. podstawowe typy danych i typy danych użytkownika są całkowicie równe podczas pracy z nimi. W wizualnym środowisku programistycznym pojawiają się na listach prawidłowych typów wraz z innymi podstawowymi typami danych. Prawdopodobieństwo, że możemy potrzebować nieudokumentowanego (zdefiniowanego przez użytkownika) typu danych podczas projektowania własnej bazy danych, jest dość wysokie. Rzeczywiście, domyślnie do systemu zarządzania bazą danych wszyte są tylko najbardziej popularne typy danych, odpowiednie odpowiednio do rozwiązywania najczęstszych zadań. Podczas kompilowania tematycznych baz danych jest prawie niemożliwe obejście się bez zaprojektowania własnych typów danych. Ale, co ciekawe, z równym prawdopodobieństwem może być konieczne usunięcie utworzonego przez nas podtypu, aby nie zaśmiecać i nie komplikować kodu. W tym celu systemy zarządzania bazami danych mają zwykle wbudowany specjalny operator. upuszczać, co oznacza „usuń”. Ogólna forma tego operatora do usuwania niepotrzebnych typów niestandardowych jest następująca: Podtyp upuszczania nazwa typu niestandardowego; Niestandardowe typy danych są ogólnie zalecane dla podtypów, które są wystarczająco ogólne. 3. Wartości domyślne Systemy zarządzania bazami danych mogą mieć możliwość tworzenia dowolnych wartości domyślnych lub, jak się je nazywa, wartości domyślnych. Ta operacja w każdym środowisku programistycznym ma dość dużą wagę, ponieważ w prawie każdym zadaniu może być konieczne wprowadzenie stałych, niezmiennych wartości domyślnych. Aby utworzyć domyślny w systemach zarządzania bazami danych, wykorzystywana jest funkcja znana nam już z przejścia typu danych zdefiniowanego przez użytkownika Stwórz. Tylko w przypadku tworzenia wartości domyślnej używane jest również dodatkowe słowo kluczowe domyślnym, co oznacza „domyślny”. Innymi słowy, aby utworzyć wartość domyślną w istniejącej bazie danych, musisz użyć następującej instrukcji: Utwórz domyślną domyślna nazwa As stałe wyrażenie; Oczywiste jest, że w miejsce stałej wartości podczas stosowania tego operatora należy wpisać wartość lub wyrażenie, które chcemy uczynić wartością domyślną lub wyrażeniem. I oczywiście musimy zdecydować, pod jaką nazwą będzie nam wygodnie używać go w naszej bazie danych i wpisać tę nazwę w pierwszym wierszu operatora. Należy zauważyć, że w tym konkretnym przypadku ta instrukcja Create jest zgodna ze składnią Transact-SQL wbudowaną w system Microsoft SQL Server. Więc co mamy? Wydedukowaliśmy, że wartością domyślną jest nazwana stała przechowywana w bazach danych, podobnie jak jej obiekt. W wizualnym środowisku programistycznym wartości domyślne pojawiają się na liście podświetlonych wartości domyślnych. Oto przykład tworzenia wartości domyślnej. Załóżmy, że do poprawnego działania naszej bazy danych konieczne jest, aby jakaś wartość w niej funkcjonowała w znaczeniu nieograniczonego życia czegoś. Następnie należy wpisać na listę wartości tej bazy danych wartość domyślną, która spełnia to wymaganie. Może to być konieczne, choćby dlatego, że za każdym razem, gdy napotkasz to dość nieporęczne wyrażenie w tekście kodu, bardzo niewygodne będzie ponowne napisanie go. Dlatego użyjemy powyższej instrukcji Create, aby utworzyć wartość domyślną, w znaczeniu nieograniczonego życia czegoś. Utwórz domyślną "bez limitu czasu" As ‘9999-12-31 23: 59:59’ Wykorzystano tu również składnię Transact-SQL, zgodnie z którą wartości stałych daty i czasu (w tym przypadku „9999-12-31 23:59:59”) są zapisywane jako ciągi znaków o określonym kierunku. Interpretacja ciągów znaków jako wartości daty i godziny jest określana przez kontekst, w którym ciągi są używane. Na przykład w naszym konkretnym przypadku najpierw w linii stałej jest wpisana wartość graniczna roku, a następnie czas. Jednak pomimo całej swojej użyteczności, wartości domyślne, takie jak typ danych zdefiniowany przez użytkownika, mogą czasami wymagać ich usunięcia. Systemy zarządzania bazami danych zwykle mają specjalny wbudowany predykat, podobny do operatora, który usuwa bardziej zdefiniowany przez użytkownika typ danych, który nie jest już potrzebny. To jest predykat Spadek a sam operator wygląda tak: Upuść domyślne nazwa domyślna; 4. Wirtualne atrybuty Wszystkie atrybuty w systemach zarządzania bazami danych są podzielone (przez absolutną analogię z relacjami) na podstawowe i wirtualne. Tak zwana podstawowe atrybuty to zapisane atrybuty, które muszą być użyte więcej niż raz, dlatego zaleca się ich zapisywanie. A z kolei wirtualne atrybuty nie są przechowywane, ale obliczane atrybuty. Co to znaczy? Oznacza to, że wartości tzw. atrybutów wirtualnych nie są faktycznie przechowywane, ale są na bieżąco przeliczane na podstawie atrybutów bazowych za pomocą podanych formuł. W takim przypadku domeny obliczonych atrybutów wirtualnych są określane automatycznie. Podajmy przykład tabeli definiującej relację, w której dwa atrybuty są zwyczajne, podstawowe, a trzeci atrybut wirtualny. Zostanie ona obliczona według specjalnie wprowadzonego wzoru.
Widzimy więc, że atrybuty „Waga Kg” i „Cena Rub za Kg” są atrybutami podstawowymi, ponieważ mają zwykłe wartości i są przechowywane w naszej bazie danych. Ale atrybut „Koszt” jest atrybutem wirtualnym, ponieważ jest ustalany przez formułę jego obliczania i nie będzie faktycznie przechowywany w bazie danych. Warto zauważyć, że ze względu na swój charakter atrybuty wirtualne nie mogą przyjmować wartości domyślnych, a ogólnie sama koncepcja wartości domyślnej atrybutu wirtualnego jest bez znaczenia, a zatem nie ma zastosowania. Trzeba też mieć świadomość, że choć dziedziny wirtualnych atrybutów są określane automatycznie, to czasami trzeba zmienić rodzaj obliczonych wartości z istniejącego na inny. W tym celu język systemów zarządzania bazami danych posiada specjalny predykat Convert, za pomocą którego można przedefiniować typ wyliczanego wyrażenia. Convert to tak zwana funkcja konwersji typu jawnego. Jest napisany w następujący sposób: konwertować (typ danych, wyrażenie); Wyrażenie będące drugim argumentem funkcji Convert zostanie obliczone i wyprowadzone jako takie dane, których typ wskazuje pierwszy argument funkcji. Rozważ przykład. Załóżmy, że musimy obliczyć wartość wyrażenia „2 * 2”, ale musimy to wypisać nie jako liczbę całkowitą „4”, ale jako ciąg znaków. Aby wykonać to zadanie, piszemy następującą funkcję Convert: konwertować (Char(1), 2*2). Widzimy więc, że ten zapis funkcji Convert da dokładnie taki wynik, jakiego potrzebujemy. 5. Pojęcie kluczy Podczas deklarowania schematu relacji bazowej można podać deklaracje wielu kluczy. Spotkaliśmy się z tym już wiele razy. Na koniec nadszedł czas, aby omówić bardziej szczegółowo, czym są klucze relacji, a nie ograniczać się do ogólnych fraz i przybliżonych definicji. Podajmy więc ścisłą definicję klucza relacji. Klucz schematu relacji jest podschematem oryginalnego schematu, składającym się z co najmniej jednego atrybutu, dla którego jest zadeklarowany warunek wyjątkowości wartości w krotkach relacji. Aby zrozumieć, czym jest warunek wyjątkowości lub, jak to się nazywa, unikalne ograniczenie, zacznijmy od definicji krotki i jednoargumentowej operacji rzutowania krotki na podukład. Przynieśmy je: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - definicja krotki, t(S) [S'] = {t(a) | a def (t) S'}, S' ⊆ S jest definicją operacji rzutowania jednoargumentowego; Jasne jest, że rzutowanie krotki na podschemat odpowiada podłańcuchowi wiersza tabeli. Czym dokładnie jest ograniczenie unikalności kluczowego atrybutu? Deklaracja klucza K dla schematu relacji S prowadzi do sformułowania następującego warunku niezmiennego, zwanego, jak już powiedzieliśmy, ograniczenie unikalności i oznaczony jako: Inw < K → S > r(S): Inv < K → S > r(S) = ∀t1, T2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S)), K S; Zatem to ograniczenie jednoznaczności Inv < K → S > r(S) klucza K oznacza, że jeśli dowolne dwie krotki t1 oraz t2, należące do relacji r(S), są równe w rzucie na klucz K, to z konieczności pociąga to za sobą równość tych dwóch krotek i w rzucie na cały schemat relacji S. Innymi słowy, wszystkie wartości krotek należących do kluczowych atrybutów są unikalne, niepowtarzalne w ich relacji. Drugim ważnym wymogiem dla klucza relacji jest: wymóg redundancji. Co to znaczy? To wymaganie oznacza, że żaden ścisły podzbiór klucza nie musi być unikatowy. Na poziomie intuicyjnym jasne jest, że kluczowym atrybutem jest ten atrybut relacji, który jednoznacznie i precyzyjnie identyfikuje każdą krotkę relacji. Na przykład w następującej relacji podanej przez tabelę:
Kluczowym atrybutem jest atrybut „Gradebook #”, ponieważ różni uczniowie nie mogą mieć tego samego numeru dziennika ocen, tj. ten atrybut podlega unikalnemu ograniczeniu. Ciekawe, że w schemacie dowolnej relacji mogą wystąpić różne klucze. Wymieniamy główne typy kluczy: 1) prosty klucz to klucz składający się z jednego i nie więcej atrybutów. Na przykład w arkuszu egzaminacyjnym z danego przedmiotu prostym kluczem jest numer karty kredytowej, ponieważ może on jednoznacznie zidentyfikować każdego ucznia; 2) klucz złożony to klucz składający się z dwóch lub więcej atrybutów. Na przykład kluczem złożonym na liście sal lekcyjnych jest numer budynku i numer sali lekcyjnej. W końcu nie jest możliwe jednoznaczne utożsamienie każdej publiczności z jednym z tych atrybutów, a całkiem łatwo jest to zrobić z ich całością, to znaczy z kluczem złożonym; 3) super klucz jest dowolnym nadzbiorem dowolnego klucza. Dlatego sam schemat relacji jest z pewnością superkluczem. Z tego możemy wywnioskować, że każda relacja teoretycznie ma co najmniej jeden klucz, a może mieć ich kilka. Jednak deklarowanie superklucza w miejsce normalnego klucza jest logicznie nielegalne, ponieważ wiąże się z rozluźnieniem automatycznie wymuszonego ograniczenia unikalności. W końcu super klucz, chociaż ma właściwość unikalności, nie ma właściwości braku nadmiarowości; 4) główny klucz jest po prostu kluczem, który został zadeklarowany jako pierwszy podczas definiowania relacji bazowej. Ważne jest, aby zadeklarować jeden i tylko jeden klucz podstawowy. Ponadto atrybuty klucza podstawowego nigdy nie mogą przyjmować wartości null. Podczas tworzenia relacji bazowej we wpisie pseudokodu klucz podstawowy jest oznaczony klucz podstawowy aw nawiasie nazwa atrybutu, którym jest ten klucz; 5) klawisze kandydujące to wszystkie inne klucze zadeklarowane po kluczu podstawowym. Jakie są główne różnice między kluczami kandydującymi a kluczami podstawowymi? Po pierwsze, może istnieć kilka kluczy kandydujących, podczas gdy klucz podstawowy, jak wspomniano powyżej, może być tylko jeden. Po drugie, jeśli atrybuty klucza podstawowego nie mogą przyjmować wartości Null, warunek ten nie jest nakładany na atrybuty kluczy kandydujących. W pseudokodzie podczas definiowania relacji bazowej klucze kandydujące są deklarowane za pomocą słów Klucz kandydata a następnie w nawiasach, tak jak w przypadku deklarowania klucza głównego, podawana jest nazwa atrybutu, którym jest dany klucz kandydujący; 6) klucz zewnętrzny jest kluczem zadeklarowanym w relacji bazowej, który odwołuje się również do klucza podstawowego lub kandydującego tej samej lub innej relacji bazowej. W tym przypadku relacja, do której odnosi się klucz obcy, nazywana jest referencją (lub rodzic) nastawienie. Relacja zawierająca klucz obcy nazywa się dziecko. W pseudokodzie klucz obcy jest oznaczony jako klucz obcy, w nawiasach bezpośrednio po tych słowach podawana jest nazwa atrybutu tej relacji, który jest kluczem obcym, a po nim zapisywane jest słowo kluczowe referencje („odnosi się do”) i określ nazwę relacji bazowej oraz nazwę atrybutu, do którego odnosi się ten konkretny klucz obcy. Również podczas tworzenia relacji bazowej dla każdego klucza obcego zapisywany jest warunek zwany ograniczenie integralności referencyjnej, ale omówimy to szczegółowo później. Wykład nr 8 Przedmiotem tego wykładu będzie dość szczegółowe omówienie operatora tworzenia relacji bazowych. Przeanalizujemy samego operatora w zapisie pseudokodowym, przeanalizujemy wszystkie jego elementy i ich pracę, przeanalizujemy metody modyfikacji, czyli zmiany podstawowych relacji. 1. Symbole metajęzykowe Przy opisie konstrukcji składniowych użytych do pisania podstawowego operatora tworzenia relacji w pseudokodzie stosuje się różne metody. symbole metajęzykowe. Są to wszelkiego rodzaju nawiasy otwierające i zamykające, różne kombinacje kropek i przecinków, jednym słowem symbole, z których każdy ma swoje znaczenie i ułatwia programiście pisanie kodu. Wprowadźmy i wyjaśnijmy znaczenie głównych symboli metajęzykowych, które są najczęściej używane w projektowaniu podstawowych relacji. Więc: 1) znak metajęzykowy „{}”. Konstrukcje składniowe w nawiasach klamrowych są obowiązkowe jednostki składniowe. Podczas definiowania relacji bazowej wymaganymi elementami są na przykład atrybuty bazowe; bez deklarowania atrybutów podstawowych nie można zaprojektować relacji. Dlatego podczas pisania podstawowego operatora tworzenia relacji w pseudokodzie, podstawowe atrybuty są wymienione w nawiasach klamrowych; 2) symbol metajęzykowy „[]”. W tym przypadku jest odwrotnie: konstrukcje składniowe w nawiasach kwadratowych reprezentują opcjonalny elementy składni. Z kolei opcjonalne jednostki syntaktyczne w podstawowym operatorze tworzenia relacji są wirtualnymi atrybutami klucza podstawowego, kandydującego i obcego. Tutaj oczywiście są też subtelności, ale o nich porozmawiamy później, gdy przejdziemy bezpośrednio do projektowania operatora do tworzenia relacji bazowej; 3) symbol metajęzykowy „|”. Ten symbol dosłownie oznacza "lub", podobnie jak analogiczny symbol w matematyce. Użycie tego symbolu metajęzykowego oznacza, że należy wybierać między dwiema lub większą liczbą konstrukcji oddzielonych odpowiednio tym symbolem; 4) symbol metajęzykowy „…”. Elipsa umieszczona bezpośrednio po jednostkach syntaktycznych oznacza możliwość powtórzenia te elementy składniowe poprzedzające symbol metajęzykowy; 5) symbol metajęzykowy „,..”. Ten symbol oznacza prawie to samo, co poprzedni. Tylko przy użyciu symbolu metajęzykowego „,..”, powtórzenie występują konstrukcje składniowe Oddzielone przecinkamico jest często znacznie wygodniejsze. Mając to na uwadze, możemy mówić o równoważności następujących dwóch konstrukcji składniowych: jednostka [, jednostka]... и jednostka,.. ; 2. Przykład tworzenia podstawowej relacji we wpisie pseudokodowym Teraz, gdy wyjaśniliśmy znaczenie głównych symboli metajęzykowych używanych podczas pisania operatora tworzenia relacji bazowych w pseudokodzie, możemy przejść do faktycznego rozważenia samego tego operatora. Jak można zrozumieć z powyższych odniesień, operator do tworzenia relacji bazowej we wpisie pseudokodu zawiera deklaracje atrybutów bazowych i wirtualnych, kluczy podstawowych, kandydujących i obcych. Ponadto, jak zostanie pokazane i wyjaśnione powyżej, operator ten obejmuje również ograniczenia wartości atrybutów i ograniczenia krotek, a także tak zwane ograniczenia integralności referencyjnej. Pierwsze dwa ograniczenia, a mianowicie ograniczenie wartości atrybutu i ograniczenie krotki, są deklarowane po specjalnym zastrzeżonym słowie ZOBACZ. Ograniczenia integralności referencyjnej mogą być dwojakiego rodzaju: na aktualizacji, co oznacza „podczas aktualizacji” i po usunięciu, co oznacza „po usunięciu”. Co to znaczy? Oznacza to, że podczas aktualizowania lub usuwania atrybutów relacji, do których odwołuje się klucz obcy, należy zachować integralność stanu. (Porozmawiamy o tym później.) Sam operator tworzenia relacji bazy jest używany przez nas już przestudiowany - operator Stwórz, tylko w celu stworzenia podstawowej relacji, słowo kluczowe jest dodawane stół ("nastawienie"). No i oczywiście, ponieważ sama relacja jest większa i obejmuje wszystkie omówione wcześniej konstrukcje, a także nowe konstrukcje dodatkowe, operator create będzie robił duże wrażenie. Zapiszmy więc w pseudokodzie ogólną postać operatora służącego do tworzenia podstawowych relacji: Utwórz tabelę nazwa relacji bazowej { nazwa atrybutu podstawowego typ wartości atrybutu podstawowego ZOBACZ (limit wartości atrybutu) {Null | Nie jest zerem} domyślnym (domyślna wartość) },.. [nazwa wirtualnego atrybutu as (wzór obliczeniowy) ],.. [,ZOBACZ (ograniczenie krotki)] [,klucz podstawowy (nazwa atrybutu...)] [,Klucz kandydata (nazwa atrybutu,..)]... [,klucz obcy (nazwa atrybutu,..) referencje nazwa relacji odniesienia (nazwa atrybutu,...) przy aktualizacji { Ogranicz | Kaskada | Ustaw zero} po usunięciu { Ogranicz | Kaskada | Ustaw zero} ] ... Widzimy więc, że można zadeklarować kilka podstawowych i wirtualnych atrybutów, kluczy kandydujących i obcych, ponieważ po odpowiednich konstrukcjach składniowych znajduje się symbol metajęzykowy „,..” Po deklaracji klucza podstawowego ten symbol nie występuje, ponieważ relacje bazowe, jak wspomniano wcześniej, dopuszczają tylko jeden klucz podstawowy. Następnie przyjrzyjmy się bliżej mechanizmowi deklaracji. podstawowe atrybuty. Opisując dowolny atrybut w operatorze tworzenia relacji bazowej, w ogólnym przypadku podaje się jego nazwę, typ, ograniczenia dotyczące jego wartości, flagę ważności wartości Null oraz wartości domyślne. Łatwo zauważyć, że typ atrybutu i jego ograniczenia wartości określają jego domenę, czyli dosłownie zbiór poprawnych wartości dla tego konkretnego atrybutu. Ograniczenie wartości atrybutu jest zapisywany jako warunek zależny od nazwy atrybutu. Oto mały przykład ułatwiający zrozumienie tego materiału: Utwórz tabelę nazwa relacji bazowej Kurs liczba całkowita ZOBACZ (1 <= Kurs i Kurs <= 5; Tutaj warunek „1 <= Nagłówek i Nagłówek <= 5” wraz z definicją typu danych typu integer naprawdę całkowicie warunkuje zbiór dozwolonych wartości atrybutu, czyli dosłownie jego domeny. Flaga wartości Null (Null | not Null) zabrania (nie Null) lub odwrotnie zezwala (Null) na pojawienie się wartości Null wśród wartości atrybutów. Biorąc pod uwagę właśnie omówiony przykład, mechanizm stosowania flag NULL-validity jest następujący: Utwórz tabelę nazwa relacji bazowej Kurs liczba całkowita ZOBACZ (1 <= Kurs i Kurs <= 5); Nie jest zerem; Tak więc numer kursu studenta nigdy nie może być pusty, nie może być nieznany kompilatorom baz danych i nie może nie istnieć. Wartości domyślne (domyślnym (wartość domyślna)) są używane podczas wstawiania krotki do relacji, jeśli wartości atrybutów nie są jawnie ustawione w instrukcji INSERT. Warto zauważyć, że wartości domyślne mogą być również wartościami Null, o ile wartości Null dla tego konkretnego atrybutu są deklarowane jako prawidłowe. Rozważmy teraz definicję wirtualny atrybut w operatorze tworzenia relacji bazy. Jak powiedzieliśmy wcześniej, ustawienie wirtualnego atrybutu polega na ustaleniu formuły jego obliczania za pomocą innych atrybutów bazowych. Rozważmy przykład deklarowania wirtualnego atrybutu „Pocieranie o koszt”. w postaci formuły zależnej od podstawowych atrybutów „Waga Kg” i „Cena Rub./Kg”. Utwórz tabelę nazwa relacji bazowej Waga (kg Typ wartości atrybutu podstawowego Waga Kg ZOBACZ (ograniczenie wartości atrybutu Waga Kg) Nie jest zerem domyślnym (domyślna wartość) Cena, pocierać. na kg typ wartości podstawowego atrybutu Cena Rub. na kg ZOBACZ (ograniczenie wartości atrybutu Cena rub. za kg) Nie jest zerem domyślnym (domyślna wartość) ... Koszt, pocierać. as (Waga Kg * Cena Rub. za Kg) Nieco wcześniej przyjrzeliśmy się ograniczeniom atrybutów, które zostały zapisane jako warunki zależne od nazw atrybutów. Rozważmy teraz drugi rodzaj ograniczeń deklarowanych podczas tworzenia relacji bazowej, a mianowicie ograniczenia krotek. Co to jest ograniczenie krotki, czym różni się od ograniczenia atrybutu? Ograniczenie krotki jest również zapisywane jako warunek zależny od nazwy atrybutu podstawowego, ale tylko w przypadku ograniczenia krotki warunek może zależeć od wielu nazw atrybutów w tym samym czasie. Rozważmy przykład ilustrujący mechanizm pracy z ograniczeniami krotek: Utwórz tabelę nazwa relacji bazowej Minimalna waga kg wartość typ podstawowego atrybutu min Waga Kg ZOBACZ (ograniczenie wartości atrybutu min Waga Kg) Nie jest zerem domyślnym (domyślna wartość) maksymalna waga kg wartość typ atrybut bazowy max Waga Kg ZOBACZ (ograniczenie wartości atrybutu max Waga Kg) Nie jest zerem domyślnym (domyślna wartość) ZOBACZ (0 < min Waga kg i minimalna waga kg < maksymalna waga kg); Zatem nałożenie ograniczenia na krotkę sprowadza się do zastąpienia wartościami krotki nazwami atrybutów. Przejdźmy do rozważenia podstawowego operatora tworzenia relacji. Raz zadeklarowane atrybuty podstawowe i wirtualne mogą, ale nie muszą być zadeklarowane. klucze: podstawowy, kandydat i zewnętrzny. Jak powiedzieliśmy wcześniej, podschemat relacji bazowej, która w innej (lub tej samej) relacji bazowej odpowiada kluczowi głównemu lub kandydującemu w kontekście pierwszej relacji, nazywa się klucz obcy. Klucze obce reprezentują mechanizm linku krotki niektórych relacji na krotki innych relacji, czyli występują deklaracje klucza obcego związane z nałożeniem wspomnianych już tzw. ograniczenia integralności referencyjnej. (To ograniczenie będzie tematem następnego wykładu, ponieważ integralność stanu (tj. integralność wymuszona przez ograniczenia integralności) ma kluczowe znaczenie dla powodzenia relacji bazowej i całej bazy danych.) Z kolei deklarowanie kluczy podstawowych i kandydujących nakłada odpowiednie ograniczenia unikalności na podstawowy schemat relacji, o którym mówiliśmy wcześniej. I na koniec należy powiedzieć o możliwości usunięcia relacji bazowej. Często w praktyce projektowania baz danych konieczne jest usunięcie starej, niepotrzebnej relacji, aby nie zaśmiecać kodu programu. Można to zrobić za pomocą znanego już operatora Spadek. W swojej pełnej ogólnej postaci operator usuwania relacji bazowej wygląda tak: Upuść stół nazwa relacji bazowej; 3. Ograniczenie integralności według stanu Ograniczenie integralności obiekt danych relacyjnych od jest tak zwanym niezmiennikiem danych. Jednocześnie integralność należy z całą pewnością odróżnić od bezpieczeństwa, co z kolei oznacza ochronę danych przed nieuprawnionym dostępem do nich w celu ujawnienia, modyfikacji lub zniszczenia danych. Ogólnie rzecz biorąc, ograniczenia integralności dotyczące relacyjnych obiektów danych są klasyfikowane według poziomów hierarchii te same obiekty danych relacyjnych (hierarchia obiektów danych relacyjnych jest sekwencją zagnieżdżonych pojęć: "atrybut - krotka - relacja - baza danych"). Co to znaczy? Oznacza to, że ograniczenia integralności zależą od: 1) na poziomie atrybutów – z wartości atrybutów; 2) na poziomie krotki - z wartości krotki, tj. z wartości kilku atrybutów; 3) na poziomie relacji - z relacji, czyli z kilku krotek; 4) na poziomie bazy danych - z kilku relacji. Teraz pozostaje nam tylko bardziej szczegółowo rozważyć ograniczenia integralności dotyczące stanu każdego z powyższych pojęć. Ale najpierw podajmy koncepcje proceduralnego i deklaratywnego wsparcia dla ograniczeń integralności stanu. Tak więc obsługa ograniczeń integralności może być dwojakiego rodzaju: 1) proceduralny, czyli utworzony przez napisanie kodu programu; 2) deklaracyjny, tj. tworzone przez zadeklarowanie pewnych ograniczeń dla każdego z powyższych pojęć zagnieżdżonych. Deklaratywna obsługa ograniczeń integralności jest zaimplementowana w kontekście instrukcji Create do tworzenia relacji bazowej. Porozmawiajmy o tym bardziej szczegółowo. Zacznijmy rozważać zbiór ograniczeń od dołu naszej hierarchicznej drabiny relacyjnych obiektów danych, czyli od pojęcia atrybutu. Ograniczenie poziomu atrybutu obejmuje: 1) ograniczenia dotyczące rodzaju wartości atrybutów. Na przykład warunek liczby całkowitej dla wartości, tj. warunek liczby całkowitej dla atrybutu „Kurs” z jednej z omówionych wcześniej relacji bazowych; 2) ograniczenie wartości atrybutu, zapisane jako warunek zależny od nazwy atrybutu. Przykładowo analizując tę samą podstawową relację jak w poprzednim akapicie widzimy, że w tej relacji również istnieje ograniczenie wartości atrybutów za pomocą opcji ZOBACZ, tj.: ZOBACZ (1 <= Kurs i Kurs <= 5); 3) Ograniczenie na poziomie atrybutu obejmuje ograniczenia wartości Null zdefiniowane przez dobrze znaną flagę ważności (Null) lub odwrotnie, niedopuszczalność (nie Null) wartości Null. Jak wspomnieliśmy wcześniej, pierwsze dwa ograniczenia definiują ograniczenie domeny atrybutu, czyli wartość jego zestawu definicji. Ponadto, zgodnie z hierarchiczną drabiną relacyjnych obiektów danych, musimy mówić o krotkach. Więc, ograniczenie na poziomie krotki redukuje się do ograniczenia krotki i jest zapisywane jako warunek zależny od nazw kilku podstawowych atrybutów schematu relacji, tj. to ograniczenie integralności stanu jest znacznie mniejsze i prostsze niż podobne, tylko odpowiadające atrybutowi. I znowu, przydałoby się przywołać przykład podstawowej relacji, przez którą przeszliśmy wcześniej, która ma ograniczenie krotki, którego potrzebujemy teraz, a mianowicie: ZOBACZ (0 < min Waga kg i minimalna waga kg < maksymalna waga kg); I wreszcie, ostatnią istotną koncepcją w kontekście ograniczenia integralności państwa jest koncepcja poziomu relacji. Jak powiedzieliśmy wcześniej, ograniczenie na poziomie relacji obejmuje ograniczenie wartości podstawowych (klucz podstawowy) i kandydat (Klucz kandydata) Klucze. Ciekawe, że ograniczenia nałożone na bazy danych nie są już ograniczeniami integralności stanu, ale ograniczeniami integralności referencyjnej. 4. Ograniczenia integralności referencyjnej Tak więc ograniczenie na poziomie bazy danych obejmuje ograniczenie integralności referencyjnej klucza obcego (klucz obcy). Wspomnieliśmy już o tym krótko, gdy mówiliśmy o ograniczeniach integralności referencyjnej podczas tworzenia relacji bazowej i kluczy obcych. Teraz nadszedł czas, aby omówić tę koncepcję bardziej szczegółowo. Jak powiedzieliśmy wcześniej, klucz obcy zadeklarowanej relacji bazowej odnosi się do klucza głównego lub kandydującego jakiejś innej (najczęściej) relacji bazowej. Przypomnijmy, że w tym przypadku relacja, do której odwołuje się klucz obcy, nazywa się odniesienie lub rodzicielski, ponieważ w pewnym sensie "odradza się" jeden atrybut lub wiele atrybutów w relacji bazowej odniesienia. A z kolei relacja zawierająca klucz obcy nazywa się dziecko, również z oczywistych powodów. Co to jest ograniczenie integralności referencyjnej? I polega na tym, że każda wartość klucza obcego relacji podrzędnej musi koniecznie odpowiadać wartości dowolnego klucza relacji nadrzędnej, chyba że wartość klucza obcego zawiera wartości Null w jakichkolwiek atrybutach. Krotki relacji potomnej, które naruszają ten warunek, nazywane są wiszące. Rzeczywiście, jeśli klucz obcy relacji potomnej odnosi się do atrybutu, który w rzeczywistości nie istnieje w relacji nadrzędnej, to nie odnosi się do niczego. To właśnie tych sytuacji należy unikać w każdy możliwy sposób, a to oznacza zachowanie integralności referencyjnej. Ale wiedząc, że żadna baza danych nigdy nie pozwoli na utworzenie nieaktualnej krotki, programiści upewniają się, że w bazie danych nie ma początkowo nieaktualnych krotek i że wszystkie dostępne klucze odnoszą się do bardzo rzeczywistego atrybutu relacji nadrzędnej. Niemniej jednak zdarzają się sytuacje, w których wiszące krotki powstają już podczas działania bazy danych. Jakie są te sytuacje? Wiadomo, że gdy krotki są usuwane z relacji rodzica lub gdy wartość klucza krotki relacji rodzica jest aktualizowana, integralność referencyjna może zostać naruszona, tj. Mogą wystąpić zwisające krotki. Aby wykluczyć możliwość ich wystąpienia podczas deklarowania wartości klucza obcego, określa się jedno z poniższych: trzy do dyspozycji przepisy zachowanie integralności referencyjnej, stosowanej odpowiednio przy aktualizacji wartości klucza w relacji nadrzędnej (tj. jak wspomnieliśmy wcześniej, na aktualizacji) lub podczas usuwania krotki z relacji rodzica (po usunięciu). Należy zauważyć, że dodanie nowej krotki do relacji rodzicielskiej nie może z oczywistych względów naruszyć integralności referencyjnej. W końcu, gdyby ta krotka została właśnie dodana do relacji bazowej, żaden atrybut nie mógłby się do niej wcześniej odnosić z powodu jej braku! Więc jakie są te trzy zasady, które są używane do zachowania integralności referencyjnej w bazach danych? Wymieńmy je. 1. ograniczaćLub reguła ograniczeń. Jeśli podczas ustawiania naszej relacji bazowej, deklarując klucze obce w ograniczeniu integralności referencyjnej, zastosowaliśmy tę zasadę jej utrzymywania, to aktualizacja klucza w relacji rodzica lub usunięcie krotki z relacji rodzica po prostu nie może być wykonane, jeśli ta krotka jest do którego odwołuje się co najmniej jedna krotka relacji potomnej, tj. operacja ograniczać kategorycznie zabrania wykonywania jakichkolwiek czynności, które mogłyby prowadzić do pojawienia się wiszących krotek. Zastosowanie tej zasady ilustrujemy następującym przykładem. Niech podane zostaną dwie relacje: Postawa rodzicielska
związek dziecka
Widzimy, że krotki relacji podrzędnych (2,...) i (2,...) odnoszą się do krotki relacji nadrzędnej (..., 2), a krotka relacji podrzędnej (3,...) odnosi się do ( ..., 3) postawa rodzicielska. Krotka (100,...) relacji podrzędnej jest zawieszona i nie jest prawidłowa. Tutaj tylko krotki relacji nadrzędnej (..., 1) i (..., 4) umożliwiają aktualizację wartości kluczy i usuwanie krotek, ponieważ nie odwołuje się do nich żaden z kluczy obcych relacji podrzędnej. Skomponujmy operator do tworzenia podstawowej relacji, który zawiera deklarację wszystkich powyższych kluczy: Utwórz tabelę Postawa rodzicielska Główny klucz Liczba całkowita Nie jest zerem klucz podstawowy (Główny klucz) Utwórz tabelę związek dziecka Klucz_obcy Liczba całkowita Null klucz obcy (klucz_obcy) referencje Relacja z rodzicami (klucz_podstawowy) podczas aktualizacji Ogranicz usuń Ogranicz 2. kaskadaLub zasada modyfikacji kaskadowej. Jeżeli deklarując klucze obce w naszej relacji bazowej zastosowaliśmy zasadę zachowania integralności referencyjnej kaskada, a następnie zaktualizowanie klucza w relacji rodzica lub usunięcie krotki z relacji rodzica powoduje, że odpowiednie klucze i krotki relacji podrzędnej są automatycznie aktualizowane lub usuwane. Spójrzmy na przykład, aby lepiej zrozumieć, jak działa reguła kaskadowej modyfikacji. Podajmy podstawowe relacje, które już znamy z poprzedniego przykładu: Postawa rodzicielska
и związek dziecka
Załóżmy, że zaktualizujemy kilka krotek w tabeli definiującej relację „Relacja nadrzędna”, a mianowicie zastąpimy krotkę (..., 2) krotką (..., 20), czyli otrzymamy nową relację: Postawa rodzicielska
I niech jednocześnie w oświadczeniu o tworzeniu naszej relacji bazowej „Relacja podrzędna” przy deklarowaniu kluczy obcych zastosowaliśmy zasadę zachowania integralności referencyjnej kaskada, czyli operator tworzący naszą relację bazową wygląda tak: Utwórz tabelę Postawa rodzicielska Główny klucz Liczba całkowita Nie jest zerem klucz podstawowy (Główny klucz) Utwórz tabelę związek dziecka Klucz_obcy Liczba całkowita Null klucz obcy (klucz_obcy) referencje Relacja z rodzicami (klucz_podstawowy) o aktualizacji Kaskada po usunięciu kaskady Co zatem dzieje się z relacją potomną, gdy relacja rodzica jest aktualizowana w sposób opisany powyżej? Przyjmie następującą formę: związek dziecka
Tak więc rzeczywiście zasada kaskada zapewnia kaskadową aktualizację wszystkich krotek w relacji podrzędnej w odpowiedzi na aktualizacje relacji rodzicielskiej. 3. Ustaw zeroLub zerowa reguła przypisania. Jeżeli w oświadczeniu o tworzeniu naszej relacji bazowej, deklarując klucze obce, stosujemy zasadę zachowania integralności referencyjnej Ustaw zero, wówczas aktualizacja klucza relacji nadrzędnej lub usunięcie krotki z relacji nadrzędnej pociąga za sobą automatyczne przypisanie wartości Null do tych atrybutów klucza obcego relacji podrzędnej, które dopuszczają wartości Null. Dlatego reguła ma zastosowanie, jeśli takie atrybuty istnieją. Spójrzmy na przykład, którego używaliśmy już wcześniej. Załóżmy, że mamy dwie podstawowe relacje: „Rodzicielstwo”
związek dziecka
Jak widać, atrybuty relacji potomnych dopuszczają wartości Null, stąd zasada Ustaw zero ma zastosowanie w tym konkretnym przypadku. Załóżmy teraz, że krotka (..., 1) została usunięta z relacji nadrzędnej, a krotka (..., 2) została zaktualizowana, jak w poprzednim przykładzie. Zatem relacja nadrzędna przyjmuje następującą postać: Postawa rodzicielska
Następnie biorąc pod uwagę fakt, że deklarując klucze obce relacji potomnej zastosowaliśmy zasadę zachowania integralności referencyjnej Ustaw zero, relacja potomna będzie wyglądać tak: związek dziecka
Do krotki (..., 1) nie odwoływał się żaden klucz relacji podrzędnej, więc jej usunięcie nie ma żadnych konsekwencji. Sam operator tworzenia relacji bazowej przy użyciu reguły Ustaw zero przy deklarowaniu kluczy obcych relacja wygląda tak: Utwórz tabelę Postawa rodzicielska Główny klucz Liczba całkowita Nie jest zerem klucz podstawowy (Główny klucz) Utwórz tabelę związek dziecka Klucz_obcy Liczba całkowita Null klucz obcy (klucz_obcy) referencje Relacja z rodzicami (klucz_podstawowy) po aktualizacji Ustaw Null przy usuwaniu Ustaw Null Widzimy więc, że obecność trzech różnych reguł zachowania integralności referencyjnej zapewnia, że w frazach na aktualizacji и po usunięciu funkcje mogą się różnić. Należy pamiętać i zrozumieć, że wstawianie krotek do relacji potomnej lub aktualizowanie kluczowych wartości relacji potomnych nie zostanie wykonane, jeśli prowadzi to do naruszenia integralności referencyjnej, tj. do pojawienia się tak zwanych wiszących krotek. Usunięcie krotek z relacji podrzędnej w żadnym wypadku nie może prowadzić do naruszenia integralności referencyjnej. Interesujące jest to, że relacja potomna może jednocześnie działać jako relacja rodzicielska z własnymi regułami zachowania integralności referencyjnej, jeśli klucze obce innych relacji bazowych odwołują się do niektórych jej atrybutów jako kluczy podstawowych. Jeśli programiści chcą mieć pewność, że integralność referencyjna jest wymuszana przez jakieś reguły inne niż powyższe standardowe reguły, to wsparcie proceduralne dla takich niestandardowych reguł zachowania integralności referencyjnej jest zapewnione za pomocą tzw. wyzwalaczy. Niestety szczegółowe rozważanie tej koncepcji nie sprowadza się do naszego toku wykładów. 5. Pojęcie indeksów Tworzenie kluczy w relacjach bazowych jest automatycznie połączone z tworzeniem indeksów. Zdefiniujmy pojęcie indeksu. Indeks - jest to systemowa struktura danych, która zawiera koniecznie uporządkowaną listę wartości klucza z linkami do tych krotek relacji, w której te wartości występują. W systemach zarządzania bazami danych istnieją dwa rodzaje indeksów: 1) proste,. Dla podschematu schematu relacji bazowej pobierany jest prosty indeks z pojedynczego atrybutu; 2) związek. W związku z tym indeks złożony jest indeksem podschematu składającego się z kilku atrybutów. Ale oprócz podziału na indeksy proste i złożone, w systemach zarządzania bazami danych istnieje podział indeksów na unikalne i nieunikalne. Więc: 1) wyjątkowy indeksy to indeksy odnoszące się co najwyżej do jednego atrybutu. Unikalne indeksy generalnie odpowiadają kluczowi podstawowemu relacji; 2) nieunikalny indeksy to indeksy, które mogą odpowiadać kilku atrybutom jednocześnie. Z kolei klucze nieunikalne najczęściej odpowiadają kluczom obcym relacji. Rozważmy przykład ilustrujący podział indeksów na unikalne i nieunikalne, czyli rozważmy następujące zależności zdefiniowane przez tabele:
Tutaj odpowiednio Klucz podstawowy jest kluczem podstawowym relacji, Klucz obcy jest kluczem obcym. Oczywiste jest, że w tych relacjach indeks atrybutu klucza podstawowego jest unikalny, ponieważ odpowiada kluczowi podstawowemu, czyli jednemu atrybutowi, a indeks atrybutu klucza obcego jest nieunikatowy, ponieważ odpowiada obcemu Klucze. A jego wartość „20” odpowiada zarówno pierwszemu, jak i trzeciemu wierszowi tabeli relacji. Ale czasami indeksy można tworzyć bez względu na klucze. Odbywa się to w systemach zarządzania bazami danych, aby wspierać wykonywanie operacji sortowania i wyszukiwania. Na przykład dychotomiczne wyszukiwanie wartości indeksu w krotkach zostanie zaimplementowane w systemach zarządzania bazami danych w dwudziestu iteracjach. Skąd wzięły się te informacje? Otrzymano je za pomocą prostych obliczeń, tj.: 106 = (103)2 = 220; Indeksy tworzy się w systemach zarządzania bazami danych za pomocą znanej nam już instrukcji Create, ale tylko z dodatkiem słowa kluczowego index. Taki operator wygląda tak: Utwórz indeks nazwa indeksu On nazwa relacji bazowej (nazwa atrybutu,...); Tutaj widzimy znajomy metajęzykowy symbol „,..” oznaczający możliwość powtórzenia argumentu oddzielonego przecinkiem, czyli indeks odpowiadający kilku atrybutom może być utworzony w tym operatorze. Jeśli chcesz zadeklarować unikalny indeks, dodajesz unikalne słowo kluczowe przed słowem indeksującym, a następnie cała instrukcja tworzenia w relacji indeksu bazowego staje się: Utwórz unikalny indeks nazwa indeksu On nazwa relacji bazowej (nazwa atrybutu); Wtedy w najogólniejszej postaci, jeśli przypomnimy sobie zasadę wyznaczania elementów opcjonalnych (symbol metajęzykowy []), operator tworzenia indeksu w relacji podstawowej będzie wyglądał tak: Utwórz [unikalny] indeks nazwa indeksu On nazwa relacji bazowej (nazwa atrybutu,...); Jeśli chcesz usunąć już istniejący indeks z relacji bazowej, użyj operatora Drop, również nam znanego: Indeks spadku {nazwa relacji bazowej. Nazwa indeksu},.. ; Dlaczego w tym miejscu jest używana kwalifikowana nazwa indeksu „nazwa relacji podstawowej. Nazwa indeksu”? Operator upuszczania indeksu zawsze używa swojej kwalifikowanej nazwy, ponieważ nazwa indeksu musi być unikatowa w ramach tej samej relacji, ale nie więcej. 6. Modyfikacja podstawowych relacji Aby skutecznie i wydajnie pracować z różnymi relacjami bazowymi, bardzo często programiści muszą w jakiś sposób zmodyfikować tę relację bazową. Jakie są główne wymagane opcje modyfikacji najczęściej spotykane w praktyce projektowania baz danych? Wymieńmy je: 1) wstawianie krotek. Bardzo często trzeba wstawić nowe krotki do już utworzonej relacji bazowej; 2) aktualizacja wartości atrybutów. A potrzeba tej modyfikacji w praktyce programistycznej jest jeszcze bardziej powszechna niż poprzednia, ponieważ gdy nadejdą nowe informacje o argumentach twojej bazy danych, nieuchronnie będziesz musiał zaktualizować niektóre stare informacje; 3) usunięcie krotek. I z mniej więcej równym prawdopodobieństwem konieczne staje się usunięcie z relacji bazowej tych krotek, których obecność w Twojej bazie danych nie jest już wymagana ze względu na otrzymane nowe informacje. Przedstawiliśmy więc główne punkty modyfikacji podstawowych relacji. Jak osiągnąć każdy z tych celów? W systemach zarządzania bazami danych najczęściej wbudowane są podstawowe operatory modyfikacji relacji. Opiszmy je we wpisie pseudokodowym: 1) wstaw operator w relację bazową nowych krotek. To jest operator wstawka. To wygląda tak: Włóż w nazwa relacji bazowej (nazwa atrybutu,...) Wartości (wartość atrybutu,..); Symbol metajęzykowy „,..” po nazwie atrybutu i wartości atrybutu mówi nam, że ten operator umożliwia jednoczesne dodanie wielu atrybutów do relacji bazowej. W takim przypadku należy podać nazwy atrybutów i wartości atrybutów oddzielone przecinkami w spójnej kolejności. Słowo kluczowe najnowszych w połączeniu z ogólną nazwą operatora wstawka oznacza „wstaw do” i wskazuje, w jakiej relacji atrybuty w nawiasach mają zostać wstawione. Słowo kluczowe Wartości w tym oświadczeniu i oznacza "wartości", "wartości", które są przypisane do tych nowo zadeklarowanych atrybutów; 2) teraz rozważ aktualizacja operatora wartości atrybutów w relacji bazowej. Ten operator nazywa się Aktualizacja, który jest tłumaczony z języka angielskiego i oznacza dosłownie „aktualizację”. Podajmy pełną ogólną postać tego operatora w notacji pseudokodowej i odszyfrujmy ją: Aktualizacja nazwa relacji bazowej Zestaw {nazwa atrybutu - wartość atrybutu},.. Gdzie stan; Tak więc w pierwszym wierszu operatora po słowie kluczowym Aktualizacja zapisywana jest nazwa relacji bazowej, w której mają być dokonywane aktualizacje. Słowo kluczowe Set jest tłumaczone z języka angielskiego jako „set”, a ten wiersz instrukcji określa nazwy aktualizowanych atrybutów oraz odpowiadające im wartości nowych atrybutów. Możliwa jest aktualizacja kilku atrybutów jednocześnie w jednym zestawieniu, co wynika z użycia symbolu metajęzykowego „,..”. W trzecim wierszu po słowie kluczowym Gdzie napisany jest warunek wskazujący dokładnie, które atrybuty tej relacji bazowej wymagają aktualizacji; 3) operator Usuńpozwalać usunąć dowolne krotki z relacji bazowej. Zapiszmy jego pełną formę w pseudokodzie i wyjaśnijmy znaczenie wszystkich poszczególnych jednostek składniowych: Usuń z nazwa relacji bazowej Gdzie stan; Słowo kluczowe od w połączeniu z nazwą operatora Usuń tłumaczy się jako „usuń z”. A po tych słowach kluczowych w pierwszym wierszu operatora wskazana jest nazwa relacji bazowej, z której należy usunąć wszelkie krotki. A w drugim wierszu operatora po słowie kluczowym Gdzie („gdzie”) wskazuje warunek, według którego wybierane są krotki, które nie są już wymagane w naszej relacji bazowej. Wykład nr 9. Zależności funkcjonalne 1. Ograniczenie zależności funkcjonalnej Ograniczenie unikalności narzucone przez deklaracje klucza głównego i kandydującego relacji jest szczególnym przypadkiem ograniczenia związanego z pojęciem zależności funkcjonalne. Aby wyjaśnić pojęcie zależności funkcjonalnej, rozważmy następujący przykład. Daj nam relację zawierającą dane o wynikach konkretnej sesji. Schemat tej relacji wygląda tak: Sesja (numer księgi metrykalnej, Imię i nazwisko, Temat, Gatunek); Atrybuty „Numer dziennika ocen” i „Temat” tworzą złożony (ponieważ dwa atrybuty są deklarowane jako klucz) klucz podstawowy tej relacji. Rzeczywiście, te dwa atrybuty mogą jednoznacznie określać wartości wszystkich innych atrybutów. Jednak oprócz ograniczenia unikalności związanego z tym kluczem, relacja musi koniecznie podlegać warunkowi, że jeden dziennik ocen jest wydawany jednej konkretnej osobie, a zatem w tym zakresie krotki o tym samym numerze dziennika muszą zawierać te same wartości atrybutów „Nazwisko” , „Imię i drugie imię”.
Jeśli po określonej sesji mamy następujący fragment pewnej bazy danych uczniów placówki oświatowej, to w krotkach o numerze dziennika ocen 100 atrybuty „Nazwisko”, „Imię” i „Patronimiczny” są takie same, a atrybuty „Temat” i „Ocena” – nie pasują do siebie (co jest zrozumiałe, ponieważ mówią o różnych przedmiotach i wykonaniu w nich). Oznacza to, że atrybuty „Nazwisko”, „Imię” i „Patronimiczny” funkcjonalnie zależny na atrybucie „Numer dziennika ocen”, natomiast atrybuty „Przedmiot” i „Ocena” są funkcjonalnie niezależne. Tak więc, zależność funkcjonalna jest jednowartościową zależnością umieszczoną w tabeli w systemach zarządzania bazami danych. Podajemy teraz ścisłą definicję zależności funkcjonalnej. Definicja: niech X, Y będą podschematami schematu relacji S, definiującymi na schemacie S diagram zależności funkcjonalnych X → Y (czytaj „X strzałka Y”). Zdefiniujmy funkcjonalne ograniczenia zależności inv<X → Y> jako stwierdzenie, że w odniesieniu do schematu S dowolne dwie krotki pasujące w projekcji na podschemat X muszą również pasować w projekcji do podschematu Y. Zapiszmy tę samą definicję w formie wzoru: Inw<X → Y> r(S) = t1, T2 r(t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; Co ciekawe, ta definicja wykorzystuje pojęcie operacji projekcji jednoargumentowej, z którą zetknęliśmy się wcześniej. Rzeczywiście, jak inaczej, jeśli nie użyjesz tej operacji, aby pokazać równość dwóch kolumn tabeli relacji, a nie wierszy, względem siebie? Dlatego pisaliśmy w kategoriach tej operacji, że koincydencja krotek w projekcji na jakiś atrybut lub kilka atrybutów (podschemat X) z pewnością pociągnie za sobą koincydencję tych samych kolumn-krotek na podschemacie Y w przypadku, gdy Y jest funkcjonalnie zależne od X . Warto zauważyć, że w przypadku funkcjonalnej zależności Y od X mówi się również, że X funkcjonalnie definiuje T czy co T funkcjonalnie zależny na X. W schemacie zależności funkcjonalnej X → Y podukład X nazywa się lewą stroną, a podukład Y prawą stroną. W praktyce projektowania baz danych schemat zależności funkcjonalnych jest powszechnie określany jako zależność funkcjonalna dla zwięzłości. Koniec definicji. W szczególnym przypadku, gdy prawa strona zależności funkcjonalnej, tj. podschemat Y, pasuje do całego schematu relacji, ograniczenie zależności funkcjonalnej staje się ograniczeniem unikalności klucza głównego lub kandydującego. Naprawdę: inv r(S) = ∀ t1, T2 r(t1[K] = t2 [K] → t1(S) = t2(S)), K S; Tyle, że przy definiowaniu zależności funkcjonalnej zamiast podschematu X trzeba przyjąć oznaczenie klucza K, a zamiast prawej strony zależności funkcjonalnej, podschematu Y, wziąć cały schemat relacji S, czyli w rzeczywistości ograniczenie unikalności kluczy relacji jest szczególnym przypadkiem ograniczenia zależności funkcjonalnej, gdy prawa strona jest równymi schematami zależności funkcjonalnej w całym schemacie relacji. Oto przykłady obrazu zależności funkcjonalnej: {Numer księgi rachunkowej} → {Nazwisko, Imię, Patronim}; {numer dziennika ocen, przedmiot} → {ocena}; 2. Reguły wnioskowania Armstronga Jeżeli jakakolwiek podstawowa relacja spełnia zdefiniowane wektorowo zależności funkcjonalne, to za pomocą różnych specjalnych reguł wnioskowania można uzyskać inne zależności funkcjonalne, które z pewnością spełni ta podstawowa relacja. Dobrym przykładem takich specjalnych reguł są reguły wnioskowania Armstronga. Zanim jednak przejdziemy do analizy samych reguł wnioskowania Armstronga, wprowadźmy nowy symbol metajęzykowy „├”, który nazywa się symbol meta-potwierdzenia pochodności. Ten symbol podczas formułowania reguł jest zapisywany między dwoma wyrażeniami składniowymi i wskazuje, że formuła po prawej stronie pochodzi z formuły po lewej stronie. Sformułujmy teraz same reguły wnioskowania Armstronga w postaci następującego twierdzenia. Twierdzenie. Obowiązują następujące reguły, zwane regułami wnioskowania Armstronga. Правило вывода 1. ├ X → X; Правило вывода 2. X → Y├ X ∪ Z → Y; Правило вывода 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Tutaj X, Y, Z, W są arbitralnymi podschematami schematu relacji S. Symbol metawyznaczenia derywacyjności oddziela listy przesłanek i listy twierdzeń (wniosków). 1. Pierwsza reguła wnioskowania nazywa się „refleksyjność” i brzmi następująco: „reguła jest dedukowana:„ X funkcjonalnie pociąga za sobą X ”. Jest to najprostsza z reguł wyprowadzania Armstronga. Wywodzi się dosłownie z powietrza. Warto zauważyć, że zależność funkcjonalna, która ma zarówno lewą, jak i prawą część, nazywa się zwrotny. Zgodnie z zasadą refleksyjności ograniczenie zależności refleksyjnej jest realizowane automatycznie. 2. Druga reguła wnioskowania nazywa się „uzupełnieniei brzmi następująco: „jeśli X funkcjonalnie określa Y, to wyprowadzana jest reguła: „połączenie podukładów X i Z funkcjonalnie pociąga za sobą Y”. Reguła uzupełniania pozwala rozwinąć lewą stronę ograniczenia zależności funkcjonalnej. 3. Trzecia reguła wnioskowania nazywa się „pseudoprzechodniość" i brzmi następująco: "jeśli podukład X funkcjonalnie pociąga za sobą podukład Y, a połączenie podukładów Y i W funkcjonalnie pociąga za sobą Z, to wyprowadza się reguła: "suma podukładów X i W funkcjonalnie określa podukład Z"". Reguła pseudoprzechodniości uogólnia regułę przechodniości odpowiadającą szczególnemu przypadkowi W: = 0. Podajmy formalny zapis tej reguły: X→Y, Y→Z ├X→Z. Należy zauważyć, że podane wcześniej przesłanki i wnioski zostały przedstawione w formie skróconej przez oznaczenia schematów zależności funkcjonalnych. W formie rozszerzonej odpowiadają następującym ograniczeniom zależności funkcjonalnych. Правило вывода 1. inv <X → X> r(S); Правило вывода 2. inv <X → Y> r(S) ⇒ inv <X ∪ Z → Y> r(S); Правило вывода 3. inv <X → Y> r(S) & inv <Y ∪ W → Z> r(S) ⇒ inv<X ∪ W → Z> r(S); Rysować dowód te reguły wnioskowania. 1. Dowód reguły refleksyjność wynika bezpośrednio z definicji ograniczenia zależności funkcjonalnej, gdy podschemat X zostaje zastąpiony przez podukład Y. Rzeczywiście, weźmy ograniczenie zależności funkcjonalnej: inv r(S) i podstawiamy do niego X zamiast Y, otrzymujemy: inv r(S) i to jest reguła zwrotności. Udowodniono zasadę zwrotności. 2. Dowód reguły uzupełnienie Zilustrujmy na diagramach zależności funkcjonalnej. Pierwszy diagram to diagram pakietów: przesłanka: X → Y
Drugi schemat: wniosek: X ∪ Z → Y
Niech krotki będą równe na X ∪ Z. Wtedy będą równe na X. Zgodnie z założeniem będą równe również na Y. Udowodniono zasadę uzupełniania zapasów. 3. Dowód reguły pseudoprzechodni zilustrujemy również na diagramach, których w tym konkretnym przypadku będą trzy. Pierwszy diagram to pierwsza przesłanka: przesłanka 1: X → Y
przesłanka 2: Y ∪ W → Z
I wreszcie trzeci diagram to diagram podsumowujący: wniosek: X ∪ W → Z
Niech krotki będą równe na X ∪ W. Wtedy będą równe zarówno na X, jak i W. Zgodnie z Założeniem 1, będą one również równe na Y. Stąd, zgodnie z Założeniem 2, będą równe również na Z. Udowodniono zasadę pseudoprzechodniości. Wszystkie zasady są sprawdzone. 3. Pochodne reguły wnioskowania Innym przykładem reguł, za pomocą których można w razie potrzeby wyprowadzić nowe reguły zależności funkcjonalnej, są tzw pochodne reguły wnioskowania. Jakie są te zasady, jak je uzyskać? Wiadomo, że jeśli inne są wydedukowane z pewnych już istniejących reguł za pomocą uzasadnionych metod logicznych, to te nowe reguły, zwane pochodne, może być używany razem z oryginalnymi regułami. Należy szczególnie zauważyć, że te bardzo arbitralne reguły są „pochodnymi” dokładnie od reguł wnioskowania Armstronga, przez które przeszliśmy wcześniej. Sformułujmy wyprowadzone reguły wyprowadzania zależności funkcjonalnych w postaci poniższego twierdzenia. Twierdzenie. Poniższe reguły pochodzą z reguł wnioskowania Armstronga. Правило вывода 1. ├ X ∪ Z → X; Правило вывода 2. X → Y, X → Z ├ X ∪ Y → Z; Правило вывода 3. X → Y ∪ Z ├ X → Y, X → Z; Tutaj X, Y, Z, W, podobnie jak w poprzednim przypadku, są dowolnymi podschematami schematu relacji S. 1. Pierwsza reguła pochodna nazywa się zasada trywialności i czyta tak: „Zasada jest wyprowadzona:„ połączenie podukładów X i Z funkcjonalnie pociąga za sobą X”. Zależność funkcjonalna, w której lewa strona jest podzbiorem prawej strony, nazywa się trywialny. Zgodnie z zasadą trywialności, trywialne ograniczenia zależności są automatycznie wymuszane. Co ciekawe, reguła trywialności jest uogólnieniem reguły zwrotności i podobnie jak ta ostatnia może być wyprowadzona bezpośrednio z definicji ograniczenia zależności funkcjonalnej. Fakt, że reguła ta jest wyprowadzona nie jest przypadkowy i wiąże się z kompletnością systemu reguł Armstronga. Nieco później porozmawiamy o kompletności systemu zasad Armstronga. 2. Druga reguła pochodna nazywa się zasada addytywności i brzmi następująco: „Jeżeli podukład X funkcjonalnie określa podukład Y, a X jednocześnie określa funkcjonalnie Z, to z tych reguł wyprowadza się następującą regułę: „X funkcjonalnie określa sumę podukładów Y i Z”. 3. Trzecia reguła pochodna nazywa się zasada rzutowania czy zasadaodwrócenie addytywnościBrzmi ona następująco: „Jeżeli podukład X funkcjonalnie określa połączenie podukładów Y i Z, to z tej reguły wyprowadza się następującą regułę: „X funkcjonalnie określa podukład Y i jednocześnie X określa funkcjonalnie podukład Z"", czyli rzeczywiście, ta reguła pochodna jest regułą odwróconej addytywności. Ciekawe, że reguły addytywności i rzutowania zastosowane do zależności funkcjonalnych z tymi samymi lewymi częściami pozwalają łączyć lub odwrotnie dzielić prawe części zależności. Przy konstruowaniu łańcuchów wnioskowania, po sformułowaniu wszystkich przesłanek, stosuje się zasadę przechodniości, aby we wniosku uwzględnić zależność funkcjonalną z prawą stroną. Rysować dowód wymienione arbitralne reguły wnioskowania. 1. Dowód reguły fidrygałki. Przeprowadźmy to, jak wszystkie kolejne dowody, krok po kroku: 1) mamy: X → X (z reguły refleksyjności wnioskowania Armstronga); 2) dalej mamy: X ∪ Z → X (uzyskane przez najpierw zastosowanie reguły uzupełniania wnioskowania Armstronga, a następnie w konsekwencji pierwszego kroku dowodu). Udowodniono zasadę trywialności. 2. Dokonamy weryfikacji reguły krok po kroku addytywność: 1) mamy: X → Y (jest to przesłanka 1); 2) mamy: X → Z (jest to przesłanka 2); 3) mamy: Y ∪ Z → Y ∪ Z (z reguły zwrotności wnioskowania Armstronga); 4) mamy: X ∪ Z → Y ∪ Z (otrzymane przez zastosowanie zasady pseudoprzechodniości wnioskowania Armstronga, a następnie w konsekwencji pierwszego i trzeciego kroku dowodu); 5) mamy: X ∪ X → Y ∪ Z (otrzymane przez zastosowanie reguły pseudoprzechodniości wnioskowania Armstronga, a następnie wynikające z drugiego i czwartego kroku); 6) mamy X → Y ∪ Z (z kroku piątego). Udowodniono zasadę addytywności. 3. И, наконец, проведем построение доказательства правила projekcyjność: 1) mamy: X → Y ∪ Z, X → Y ∪ Z (jest to założenie); 2) mamy: Y → Y, Z → Z (wyprowadzone z reguły zwrotności wnioskowania Armstronga); 3) mamy: Y ∪ z → y, Y ∪ z → Z (uzyskane z reguły uzupełniania wnioskowania Armstronga i następstwa z drugiego kroku dowodu); 4) mamy: X → Y, X → Z (uzyskane przez zastosowanie zasady pseudoprzechodniości wnioskowania Armstronga, a następnie w konsekwencji pierwszego i trzeciego kroku dowodu). Udowodniono zasadę projekcyjności. Wszystkie reguły wnioskowania o pochodnych są sprawdzone. 4. Kompletność systemu reguł Armstronga Niech F(S) będzie danym zbiorem zależności funkcjonalnych zdefiniowanych na schemacie relacji S. Oznacz przez inw ograniczenie narzucone przez ten zestaw zależności funkcjonalnych. Zapiszmy to: inv r(S) = ∀X → Y ∈F(S) [inv r(S)]. Tak więc ten zbiór ograniczeń nałożonych przez zależności funkcjonalne jest rozszyfrowywany następująco: dla dowolnej reguły z systemu zależności funkcjonalnych X → Y należącego do zbioru zależności funkcjonalnych F(S), ograniczenie zależności funkcjonalnych inv r(S) zdefiniowane na zbiorze relacji r(S). Niech jakaś relacja r(S) spełnia to ograniczenie. Stosując reguły wnioskowania Armstronga do zależności funkcjonalnych zdefiniowanych dla zbioru F(S), można uzyskać nowe zależności funkcjonalne, jak już powiedzieliśmy i udowodniliśmy wcześniej. I, co jest orientacyjne, relacja F(S) automatycznie spełni ograniczenia tych funkcjonalnych zależności, jak widać z rozszerzonej formy pisania reguł wnioskowania Armstronga. Przypomnij sobie ogólną formę tych rozszerzonych reguł wnioskowania: Правило вывода 1. inv < X → X > r(S); Правило вывода 2. inv <X → Y> r(S) ⇒ inw<X ∪ Z → Y> r(S); Правило вывода 3. inv <X → Y> r(S) & inv <Y ∪ W → Z> r(S) ⇒ inw<X ∪ W→Z>; Wracając do naszego rozumowania, uzupełnijmy zbiór F(S) nowymi zależnościami wyprowadzonymi z niego przy użyciu reguł Armstronga. Będziemy stosować tę procedurę uzupełniania, dopóki nie będziemy już otrzymywać nowych zależności funkcjonalnych. W wyniku tej konstrukcji otrzymamy nowy zestaw zależności funkcjonalnych, zwany zamknięcie zestaw F(S) i oznaczony F+(S). Rzeczywiście taka nazwa jest dość logiczna, bo my osobiście poprzez długą konstrukcję „zamknęliśmy” dla siebie zbiór istniejących zależności funkcjonalnych, dodając (stąd „+”) wszystkie nowe zależności funkcjonalne wynikające z już istniejących. Należy zauważyć, że ten proces konstruowania domknięcia jest skończony, ponieważ sam schemat relacji, na którym przeprowadzane są wszystkie te konstrukcje, jest skończony. Jest rzeczą oczywistą, że zamknięcie jest nadzbiorem zamykanego zestawu (w rzeczywistości jest większe!) i nie zmienia się w żaden sposób po ponownym zamknięciu. Jeśli zapiszemy to, co właśnie zostało powiedziane, w formie formuły, otrzymujemy: F(S) ⊆ F+(S), [F+(S)]+= F.+(S); Ponadto, z udowodnionej prawdziwości (tj. legalności, legitymizacji) reguł wnioskowania Armstronga i definicji domknięcia wynika, że każda relacja, która spełnia ograniczenia danego zbioru zależności funkcjonalnych, spełni warunek zależności należącej do domknięcia. . X → Y ∈ F+(S) ⇒ ∀r(S) [inw r(S) ⇒ inv r(S)]; Tak więc twierdzenie Armstronga o zupełności dla systemu reguł wnioskowania stwierdza, że implikację zewnętrzną można całkiem słusznie i uzasadnić zastąpić równoważnością. (Nie będziemy rozważać dowodu tego twierdzenia, ponieważ sam proces dowodu nie jest tak ważny w naszym szczególnym toku wykładów.) Wykład nr 10. Formy normalne 1. Znaczenie normalizacji schematu bazy danych Koncepcja, którą będziemy rozważać w tej części, jest związana z pojęciem zależności funkcjonalnych, tj. znaczenie normalizacji schematów baz danych jest nierozerwalnie związane z pojęciem ograniczeń narzucanych przez system zależności funkcjonalnych i w dużej mierze z tego pojęcia wynika. Punktem wyjścia każdego projektu bazy danych jest reprezentowanie domeny jako jednej lub więcej relacji, a na każdym etapie projektowania tworzony jest zestaw schematów relacji, które mają „ulepszone” właściwości. Zatem proces projektowania jest procesem normalizacji wzorców relacji, przy czym każda kolejna forma normalna ma właściwości, które są w pewnym sensie lepsze niż poprzednia. Każda forma normalna ma pewien zestaw ograniczeń, a relacja ma pewną formę normalną, jeśli spełnia swój własny zestaw ograniczeń. Przykładem jest ograniczenie pierwszej postaci normalnej - wartości wszystkich atrybutów relacji są niepodzielne. W teorii relacyjnych baz danych zwykle rozróżnia się następującą sekwencję form normalnych: 1) pierwsza normalna postać (1 NF); 2) druga postać normalna (2 NF); 3) trzecia postać normalna (3 NF); 4) normalna postać Boyce-Codda (BCNF); 5) czwarta postać normalna (4 NF); 6) piąta forma normalna lub forma normalna z rzutem (5 NF lub PJ/NF). (Ten kurs wykładów zawiera szczegółowe omówienie pierwszych czterech postaci normalnych podstawowych relacji, więc nie będziemy szczegółowo analizować czwartej i piątej postaci normalnej.) Główne właściwości form normalnych są następujące: 1) każda następna forma normalna jest w pewnym sensie lepsza niż poprzednia forma normalna; 2) przy przejściu do następnej postaci normalnej zachowane są właściwości poprzednich postaci normalnych. Proces projektowania opiera się na metodzie normalizacji, czyli dekompozycji relacji, która jest w poprzedniej postaci normalnej na dwie lub więcej relacji spełniających wymagania następnej postaci normalnej (spotkamy się z tym, gdy sami będziemy musieli znormalizować tę jedną w miarę przechodzenia przez materiał) lub innej podstawowej relacji). Jak wspomniano w podrozdziale dotyczącym tworzenia podstawowych relacji, podane zbiory zależności funkcjonalnych nakładają odpowiednie ograniczenia na schematy podstawowych relacji. Te ograniczenia są zazwyczaj wdrażane na dwa sposoby: 1) deklaratywnie, czyli deklarując różne typy kluczy podstawowych, kandydujących i obcych w relacji bazowej (jest to metoda najczęściej stosowana); 2) proceduralnie, czyli pisanie kodu programu (za pomocą tzw. wyzwalaczy wspomnianych powyżej). Za pomocą prostej logiki możesz zrozumieć sens normalizacji schematów baz danych. Normalizacja baz danych lub doprowadzenie baz danych do normalnej postaci oznacza zdefiniowanie takich schematów podstawowych relacji w celu zminimalizowania potrzeby pisania kodu programu, zwiększenia wydajności bazy danych i ułatwienia utrzymania integralności danych poprzez integralność stanową i referencyjną. Oznacza to, że kod i praca z nim są tak proste i wygodne, jak to tylko możliwe dla programistów i użytkowników. Aby wizualnie zademonstrować w porównaniu działanie nieznormalizowanej i znormalizowanej bazy danych, rozważmy następujący przykład. Miejmy relację bazową zawierającą informacje o wynikach sesji egzaminacyjnej. Rozważaliśmy już taką bazę danych wcześniej. W ten sposób 1 opcja schematy bazy danych. Sesja (numer księgi metrykalnej, Imię i nazwisko, Temat, Gatunek) W tej relacji, jak widać na obrazie schematu relacji bazowej, zdefiniowany jest złożony klucz podstawowy: Klucz podstawowy (numer księgi szkolnej, przedmiot); Również w tym zakresie ustalany jest system zależności funkcjonalnych: {Numer księgi rachunkowej} → {Nazwisko, Imię, Patronim}; Oto widok tabelaryczny niewielkiego fragmentu bazy danych z takim schematem relacji. Wykorzystaliśmy już ten fragment przy rozważaniu ograniczeń zależności funkcjonalnych, więc dość łatwo będzie nam zrozumieć ten temat na jego przykładzie.
Tutaj, aby zachować integralność danych według stanu, tj. spełnić ograniczenia systemu zależności funkcjonalnej {numer księgi klasowej} → {Nazwisko, Imię, Patronim} przy zmianie np. nazwiska, należy konieczne jest przejrzenie wszystkich krotek tej podstawowej relacji i sekwencyjne wprowadzanie niezbędnych zmian. Ponieważ jednak jest to dość uciążliwy i czasochłonny proces (zwłaszcza jeśli mamy do czynienia z bazą danych dużej instytucji edukacyjnej), twórcy systemów zarządzania bazami danych doszli do wniosku, że proces ten należy zautomatyzować, tj. , wykonane automatycznie. Teraz kontrolę nad spełnieniem tej (i każdej innej) zależności funkcjonalnej można zorganizować automatycznie za pomocą poprawnej deklaracji różnych kluczy w relacji bazowej oraz tzw. dekompozycji (czyli rozbicia czegoś na kilka niezależnych części) tej relacja. Podzielmy więc nasz istniejący schemat relacji „Session” na dwa schematy: schemat „Students”, który zawiera tylko informacje o uczniach danej instytucji edukacyjnej, oraz schemat „Session”, który zawiera informacje o ostatniej sesji. A potem zadeklarujemy klucze w taki sposób, abyśmy mogli łatwo uzyskać wszelkie potrzebne informacje. Pokażmy, jak będą wyglądać te nowe schematy relacji z ich kluczami. opcja 2 schematy bazy danych. Studenci (numer księgi metrykalnej, Imię i nazwisko), Klucz podstawowy (numer księgi ocen). Sesja (№ зачетной книжки, Предмет, Gatunek), Klucz podstawowy (numer księgi ocen, przedmiot), Referencje klucza obcego (numer dzienniczka) Studenci (numer dzienniczka). Co mamy teraz? W odniesieniu do „Uczniów” klucz podstawowy „Numer w dzienniku ocen” funkcjonalnie określa pozostałe trzy atrybuty: „Nazwisko”, „Imię” i „Patronimiczny”. A w odniesieniu do „sesji” złożony klucz podstawowy „dziennik ocen, przedmiot” również jednoznacznie, tj. dosłownie funkcjonalnie określa ostatni atrybut tego schematu relacji - „punktacja”. I ustalono związek między tymi dwiema relacjami: odbywa się to poprzez zewnętrzny klucz relacji „Sesje” „Dziennik ocen”, który odnosi się do atrybutu o tej samej nazwie w relacji „Uczniowie” i na żądanie, dostarcza wszystkich niezbędnych informacji. Pokażmy teraz, jak będą wyglądać relacje reprezentowane przez tabele odpowiadające drugiej opcji określenia odpowiednich schematów bazy danych.
Widzimy zatem, że celem normalizacji w zakresie ograniczeń narzucanych przez zależności funkcjonalne jest konieczność nałożenia wymaganych zależności funkcjonalnych na dowolną bazę danych za pomocą deklaracji różnych typów kluczy podstawowych, kandydujących i obcych relacji bazowych. 2. Pierwsza forma normalna (1NF) Na wczesnych etapach projektowania baz danych i opracowywania schematów zarządzania bazami danych, proste i jednoznaczne atrybuty były używane jako najbardziej produktywne i racjonalne jednostki kodu. Następnie używali atrybutów prostych i złożonych, a także atrybutów jednowartościowych i wielowartościowych. Wyjaśnijmy znaczenie każdego z tych pojęć. Составные атрибуты, в отличие от простых, - это атрибуты, составленные из нескольких простых атрибутов. Многозначные атрибуты, в отличие от однозначных, - это атрибуты, представляющие множество значений. Oto przykłady atrybutów prostych, złożonych, jednowartościowych i wielowartościowych. Rozważ poniższą tabelę przedstawiającą relację:
Tutaj atrybut „Telefon” jest prosty, jednoznaczny, a atrybut „Adres” jest prosty, ale wielowartościowy. Rozważmy teraz inną tabelę z różnymi atrybutami:
W tej relacji, reprezentowanej przez tabelę, atrybut „Telefony” jest prosty, ale wielowartościowy, a atrybut „Adresy” jest zarówno złożony, jak i wielowartościowy. Ogólnie możliwe są różne kombinacje atrybutów prostych lub złożonych. W różnych przypadkach tabele reprezentujące relacje mogą ogólnie wyglądać tak:
Normalizując podstawowe schematy relacji, programiści mogą używać jednego z czterech najpopularniejszych typów postaci normalnych: pierwsza postać normalna (1NF), druga postać normalna (2NF), trzecia postać normalna (3NF) lub postać normalna Boyce-Codd (NFBC) . Dla wyjaśnienia: skrót NF jest skrótem od angielskiej frazy Forma normalna. Formalnie oprócz powyższych istnieją inne rodzaje normalnych form, ale te są jednymi z najpopularniejszych. Obecnie twórcy baz danych starają się unikać atrybutów złożonych i wielowartościowych, aby nie komplikować pisania kodu, nie przeciążać jego struktury i nie dezorientować użytkowników. Z tych rozważań logicznie wynika definicja pierwszej postaci normalnej. Definicja. Każda relacja bazowa jest w pierwsza normalna forma wtedy i tylko wtedy, gdy schemat tej relacji zawiera tylko proste i tylko jednowartościowe atrybuty i koniecznie o tej samej semantyce. Aby wizualnie wyjaśnić różnice między relacjami znormalizowanymi i nieznormalizowanymi, rozważ przykład. Niech istnieje relacja nieznormalizowana o następującym schemacie. W ten sposób 1 opcja schematy relacji ze zdefiniowanym na nim prostym kluczem podstawowym: Pracownicy (numer personelu, Nazwisko, Imię, Patronim, Kod stanowiska, Telefony, Data przyjęcia lub zwolnienia); Klucz podstawowy (numer personelu); Wymieńmy, jakie błędy występują w tym schemacie zależności, tj. nazwiemy te znaki, które sprawiają, że ten schemat jest nieznormalizowany: 1) atrybut „Nazwisko Imię Patronimiczne” jest złożony, tj. złożony z niejednorodnych elementów; 2) atrybut „Telefony” jest wielowartościowy, tzn. jego wartość jest zbiorem wartości; 3) atrybut „Data przyjęcia lub zwolnienia” nie ma jednoznacznej semantyki, tj. w tym drugim przypadku nie jest jasne, jaka data jest wpisywana. Jeżeli np. wprowadzi się dodatkowy atrybut w celu doprecyzowania znaczenia daty, to wartość tego atrybutu będzie semantycznie czytelna, ale mimo to możliwe jest przechowywanie tylko jednej z podanych dat dla każdego pracownika. Co należy zrobić, aby przywrócić tę relację do normalnej postaci? Po pierwsze, konieczne jest podzielenie atrybutów złożonych na proste, aby wykluczyć te bardzo złożone atrybuty, a także atrybuty o złożonej semantyce. Po drugie, konieczne jest rozłożenie tej relacji, tj. konieczne jest rozbicie jej na kilka nowych niezależnych relacji w celu wykluczenia atrybutów wielowartościowych. Zatem biorąc pod uwagę wszystkie powyższe, po zredukowaniu relacji „Pracownicy” do pierwszej postaci normalnej lub 1NF poprzez jej dekompozycję, otrzymamy układ następujących relacji z ustawionymi na nich kluczami podstawowymi i obcymi. W ten sposób 2 opcja relacje: Pracownicy (numer personelu, Nazwisko, Imię, Patronim, Kod stanowiska, Data przyjęcia, Data zwolnienia); Klucz podstawowy (numer personelu); Telefony (№ табельный, Телефон); Klucz podstawowy (numer personelu, telefon); Referencje klucza obcego (numeru personelu) Pracownicy (numeru personelu); Więc co widzimy? Atrybut złożony „Nazwisko Imię Patronimiczny” nie jest już w naszej relacji, zamiast niego są trzy proste atrybuty „Nazwisko”, „Imię” i „Patronimiczny”, dlatego wykluczono ten powód „nienormalności” relacji . Ponadto zamiast atrybutu o niejasnej semantyce „Data zatrudnienia lub zwolnienia” mamy teraz dwa atrybuty „Data przyjęcia” i „Data zwolnienia”, z których każdy ma jednoznaczną semantykę. Dlatego też drugi powód, dla którego nasza relacja „Pracownicy” nie jest w normalnej formie, jest również bezpiecznie eliminowany. I wreszcie ostatni powód, dla którego relacja „Pracownicy” nie została znormalizowana, to obecność wielowartościowego atrybutu „Telefony”. Aby pozbyć się tego atrybutu, konieczne było rozłożenie całej relacji. W wyniku tej dekompozycji atrybut „Telefony” został generalnie wyłączony z pierwotnej relacji „Pracownicy”, ale powstała druga relacja – „Telefony”, w której występują dwa atrybuty: „numer pracownika” i „Telefon”. ", czyli wszystkie atrybuty - znowu proste, warunek przynależności do pierwszej formy normalnej jest spełniony. Te atrybuty „Numer pracownika” i „Telefon” tworzą złożony klucz podstawowy relacji „Telefony”, a atrybut „Numer pracownika” jest z kolei kluczem obcym, który odwołuje się do atrybutu o tej samej nazwie w kolumnie „Pracownicy”. " relacji, tj. w relacji " Telefony" atrybut klucza podstawowego "numer personelu" jest również kluczem obcym odnoszącym się do klucza podstawowego relacji "Pracownicy". W ten sposób zapewnione jest połączenie między tymi dwiema relacjami. Korzystając z tego linku, możesz wyświetlić całą listę swoich telefonów według numeru personelu dowolnego pracownika bez większego wysiłku i czasu bez uciekania się do stosowania atrybutów złożonych. Zauważ, że gdyby istniały zależności funkcjonalne w stosunku do systemu, to po wszystkich powyższych przekształceniach normalizacja nie zostałaby zakończona. Jednak w tym konkretnym przykładzie nie ma funkcjonalnych ograniczeń zależności, więc dalsza normalizacja tej relacji nie jest wymagana. 3. Druga forma normalna (2NF) Większe wymagania nakłada na relacje druga forma normalna, czyli 2NF. Dzieje się tak dlatego, że definicja drugiej formy normalnej relacji implikuje, w przeciwieństwie do pierwszej formy normalnej, istnienie systemu ograniczeń zależności funkcjonalnych. Definicja. Relacja bazowa jest w druga postać normalna względem danego zestawu zależności funkcjonalnych wtedy i tylko wtedy, gdy jest on w pierwszej normalnej postaci, a ponadto każdy atrybut niekluczowy jest w pełni funkcjonalnie zależny od każdego klucza. W tej definicji atrybut niekluczowy to dowolny atrybut relacji, który nie jest zawarty w żadnym podstawowym lub kandydującym kluczu relacji. Pełna zależność funkcjonalna od klucza oznacza brak zależności funkcjonalnej od jakiejkolwiek części tego klucza. Tak więc teraz, normalizując relację, musimy również monitorować spełnienie warunków, aby relacja była w pierwszej postaci normalnej, czyli upewnić się, że jej atrybuty są proste i jednoznaczne, a także spełnienie drugiego warunku dotyczącego ograniczenia zależności funkcjonalnych. Oczywiste jest, że relacje z prostymi kluczami (pierwotnym i kandydującym) mają z pewnością drugą normalną postać. Rzeczywiście, w tym przypadku uzależnienie od części klucza po prostu nie wydaje się możliwe, ponieważ klucz po prostu nie ma oddzielnych części. Teraz, podobnie jak we fragmencie poprzedniego tematu, rozważmy przykład nieznormalizowanego schematu relacji i samego procesu normalizacji. W ten sposób 1 opcja schematy relacji: Odbiorcy (№ корпуса, № аудитории, pow. m, nie. komendant służby korpusu); Klucz podstawowy (numer korpusu, numer publiczności); Ponadto zdefiniowano następujący układ zależności funkcjonalnych: {Nr korpusu} → {Nr komendanta służby korpusu}; Co widzimy? Spełnione są wszystkie warunki, aby ta relacja „Odbiorcy” pozostała w pierwszej postaci normalnej, ponieważ każdy atrybut tej relacji jest jednoznaczny i prosty. Jednak warunek, że każdy element niekluczowy musi być całkowicie funkcjonalnie zależny od klucza, nie jest spełniony. Czemu? Tak, ponieważ atrybut „Nr dowódcy sztabu korpusu” funkcjonalnie zależy nie od klucza złożonego „Nr korpusu, nr audiencji”, ale od części tego klucza, tj. od atrybutu „Nr korpusu”. Rzeczywiście, to przecież numer korpusu całkowicie określa, który konkretnie komendant jest do niego przydzielony, a z kolei liczebność komendanta korpusu nie może zależeć od numerów audytorium. Tym samym głównym zadaniem naszej normalizacji staje się zapewnienie, że klucze są rozłożone w taki sposób, aby w szczególności atrybut „Nie. Aby to osiągnąć, będziemy musieli ponownie zastosować, tak jak w poprzednim akapicie, dekompozycję relacji. Tak więc następujący system relacji, który jest 2 opcja Relacja „Odbiorcy” została właśnie uzyskana z oryginalnej relacji, rozkładając ją na kilka nowych niezależnych relacji: Korpus (Nr kadłuba, numer dowódcy personalnego korpusu); Klucz podstawowy (numer sprawy); Odbiorcy (№ корпуса, № аудитории, pow. m); Klucz podstawowy (numer korpusu, numer publiczności); Odwołania do klucza obcego (numer sprawy) Sprawy (numer sprawy); Co teraz widzimy? W odniesieniu do atrybutu niekluczowego „Korpus” „Numer osobowy dowódcy korpusu” w pełni funkcjonalnie zależy od klucza podstawowego „Numer korpusu”. Tutaj warunek znalezienia relacji w drugiej postaci normalnej jest w pełni spełniony. Przejdźmy teraz do rozważań nad drugą relacją – „Odbiorcy”. W odniesieniu do „Odbiorców” atrybut klucza podstawowego „Numer sprawy” jest również kluczem obcym, który odwołuje się do klucza podstawowego relacji „Przypadek”. W związku z tym atrybut niebędący kluczem „Powierzchnia mXNUMX” jest całkowicie zależny od całego złożonego klucza podstawowego „Budynek #, Audytorium #” i nie może nawet zależeć od żadnej z jego części. W ten sposób, rozkładając pierwotną relację, doszliśmy do wniosku, że wszystkie warunki z definicji drugiej postaci normalnej są w pełni spełnione. W tym przykładzie wszystkie wymagania dotyczące zależności funkcjonalnych są narzucane przez deklarację kluczy podstawowych (w tym przypadku nie ma kluczy kandydujących) i kluczy obcych. Dlatego nie jest wymagana dalsza normalizacja. 4. Trzecia forma normalna (3NF) Następna forma normalna, której się przyjrzymy, to trzecia forma normalna (lub 3NF). W przeciwieństwie do pierwszej postaci normalnej, a także drugiej postaci normalnej, trzecia implikuje przypisanie układu zależności funkcjonalnych wraz z relacją. Sformułujmy, jakie właściwości musi mieć relacja, aby można ją było sprowadzić do trzeciej postaci normalnej. Definicja. Relacja bazowa jest w trzecia postać normalna w odniesieniu do danego zestawu zależności funkcjonalnych wtedy i tylko wtedy, gdy jest on w drugiej postaci normalnej, a każdy atrybut niekluczowy jest w pełni funkcjonalnie zależny tylko od kluczy. Zatem wymagania trzeciej formy normalnej są silniejsze niż wymagania pierwszej i drugiej formy normalnej, nawet łącznie. W rzeczywistości, w trzeciej normalnej postaci, każdy atrybut niekluczowy zależy od klucza, od całego klucza i od niczego poza kluczem. Zilustrujmy proces sprowadzania nieznormalizowanej relacji do trzeciej postaci normalnej. Aby to zrobić, rozważmy przykład: relację, która nie jest w trzeciej postaci normalnej. W ten sposób 1 opcja schematy relacji „Pracownicy”: Pracownicy (numer personelu, nazwisko, imię, nazwisko, kod stanowiska, wynagrodzenie); Klucz podstawowy (numer personelu); Ponadto nad relacją „Pracownicy” ustawiony jest następujący system zależności funkcjonalnych: {Kod stanowiska} → {Wynagrodzenie}; Rzeczywiście, z reguły wysokość wynagrodzenia, tj. wysokość wynagrodzenia, zależy bezpośrednio od stanowiska, a zatem od jego kodu w odpowiedniej bazie danych. Dlatego ta relacja „Pracownicy” nie jest w trzeciej postaci normalnej, ponieważ okazuje się, że niekluczowy atrybut „Wynagrodzenie” jest całkowicie funkcjonalnie zależny od atrybutu „Kod stanowiska”, chociaż ten atrybut nie jest kluczowy. Co ciekawe, każda relacja sprowadza się do trzeciej formy normalnej w dokładnie taki sam sposób, jak do dwóch form poprzedzających tę, a mianowicie przez dekompozycję. Po rozłożeniu relacji „Pracownicy” otrzymujemy następujący system nowych relacji niezależnych: W ten sposób 2 opcja schematy relacji „Pracownicy”: Pozycje (Kod pozycji, Pensja); Klucz główny (kod pozycji); Pracownicy (numer personelu, Nazwisko, Imię, Patronim, Kod stanowiska); Klucz główny (kod pozycji); Odwołania klucza obcego (kod pozycji) Pozycje (kod pozycji); Teraz, jak widzimy, w odniesieniu do „Position” atrybut niekluczowy „Wynagrodzenie” jest całkowicie funkcjonalnie zależny od prostego klucza podstawowego „Kod pozycji” i tylko od tego klucza. Należy zauważyć, że w odniesieniu do „Pracownicy” wszystkie cztery atrybuty niekluczowe „Nazwisko”, „Imię”, „Patronimiczny” i „Kod stanowiska” są w pełni funkcjonalnie zależne od prostego klucza podstawowego „Numer zatrudnienia”. W związku z tym atrybut „Identyfikator pozycji” jest kluczem obcym, który odwołuje się do klucza podstawowego relacji „Pozycje”. W tym przykładzie wszystkie wymagania są narzucane przez zadeklarowanie prostych kluczy podstawowych i obcych, więc nie jest wymagana dalsza normalizacja. Warto wiedzieć, że w praktyce zwykle ogranicza się do sprowadzenia baz danych do trzeciej postaci normalnej. Jednocześnie niektóre funkcjonalne zależności atrybutów kluczowych od innych atrybutów tej samej relacji mogą nie zostać narzucone. Obsługa takich niestandardowych zależności funkcjonalnych realizowana jest za pomocą wspomnianych wcześniej wyzwalaczy (czyli proceduralnie poprzez napisanie odpowiedniego kodu programu). Ponadto wyzwalacze muszą działać z krotkami tej relacji. 5. Normalna forma Boyce-Codda (NFBC) Postać normalna Boyce-Codda występuje w „złożoności” zaraz po trzeciej postaci normalnej. Dlatego też normalna forma Boyce-Codda jest czasami nazywana po prostu silna trzecia forma normalna (lub wzmocniony 3 NF). Dlaczego jest wzmocniona? Sformułujemy definicję postaci normalnej Boyce-Codda: Definicja. Relacja bazowa jest w Postać normalna Boyce - Kodd wtedy i tylko wtedy, gdy jest w trzeciej normalnej postaci i nie tylko każdy atrybut niekluczowy jest w pełni funkcjonalnie zależny od dowolnego klucza, ale każdy atrybut klucza musi być w pełni funkcjonalnie zależny od dowolnego klucza. Tak więc wymóg, aby atrybuty niekluczowe faktycznie były zależne od całego klucza i tylko od klucza, dotyczy również atrybutów kluczowych. W relacji, która ma postać normalną Boyce-Codda, wszystkie zależności funkcjonalne w ramach relacji są narzucane przez deklarację kluczy. Jednak redukując relacje bazy danych do postaci Boyce-Codd, możliwe są sytuacje, w których zależności między atrybutami różnych relacji okazują się nienarzuconymi zależnościami funkcjonalnymi. Wspieranie takich zależności funkcjonalnych wyzwalaczami działającymi na krotkach o różnych relacjach jest trudniejsze niż w przypadku trzeciej postaci normalnej, gdy wyzwalacze działają na krotkach jednej relacji. Między innymi praktyka projektowania systemów zarządzania bazami danych pokazała, że nie zawsze możliwe jest sprowadzenie podstawowej relacji do postaci normalnej Boyce-Codda. Powodem zauważonych anomalii jest to, że wymagania drugiej postaci normalnej i trzeciej postaci normalnej nie wymagały minimalnej zależności funkcjonalnej od klucza podstawowego atrybutów będących składnikami innych możliwych kluczy. Ten problem został rozwiązany przez postać normalną, która historycznie nazywana jest postacią normalną Boyce-Codda i która jest udoskonaleniem trzeciej postaci normalnej w przypadku występowania kilku nakładających się możliwych kluczy. Ogólnie rzecz biorąc, normalizacja schematu bazy danych sprawia, że aktualizacje bazy danych są wydajniejsze dla systemu zarządzania bazą danych, ponieważ zmniejsza liczbę sprawdzeń i kopii zapasowych, które zachowują integralność bazy danych. Projektując relacyjną bazę danych, prawie zawsze uzyskuje się drugą normalną postać wszystkich relacji w bazie danych. W bazach danych, które są często aktualizowane, zwykle starają się zapewnić trzecią normalną formę relacji. Postać normalna Boyce'a-Codda cieszy się znacznie mniejszą uwagą, ponieważ w praktyce sytuacje, w których relacja ma kilka złożonych nakładających się kluczy kandydujących, są rzadkie. Wszystko to sprawia, że forma normalna Boyce-Codd nie jest zbyt wygodna w użyciu podczas tworzenia kodu programu, dlatego, jak wspomniano wcześniej, w praktyce programiści zwykle ograniczają się do przeniesienia swoich baz danych do trzeciej formy normalnej. Ma jednak również swoją dość ciekawą cechę. Chodzi o to, że sytuacje, w których relacja jest w trzeciej postaci normalnej, ale nie w postaci normalnej Boyce-Codda, są w praktyce niezwykle rzadkie, tj. po redukcji do trzeciej postaci normalnej zwykle wszystkie zależności funkcjonalne są narzucane przez deklaracje pierwotnej, kandydującej i klucze obce, więc nie ma potrzeby wyzwalania do obsługi zależności funkcjonalnych. Jednak nadal potrzebne są wyzwalacze do obsługi ograniczeń integralności, które nie są połączone zależnościami funkcjonalnymi. 6. Zagnieżdżanie normalnych form Co oznacza zagnieżdżanie normalnych form? Zagnieżdżanie normalnych form - jest to stosunek pojęć form osłabionych i wzmocnionych w stosunku do siebie. Zagnieżdżanie normalnych form wynika całkowicie z ich odpowiednich definicji. Wyobraźmy sobie diagram ilustrujący relację zagnieżdżenia znanych nam form normalnych:
Wyjaśnijmy pojęcia osłabionych i wzmocnionych form normalnych względem siebie na konkretnych przykładach. Pierwsza forma normalna jest osłabiona w stosunku do drugiej formy normalnej (a także w stosunku do wszystkich innych form normalnych). Rzeczywiście, przywołując definicje wszystkich form normalnych, przez które przeszliśmy, widzimy, że wymagania każdej formy normalnej zawierały wymóg przynależności do pierwszej formy normalnej (w końcu było to zawarte w każdej kolejnej definicji). Druga forma normalna jest silniejsza niż pierwsza forma normalna, ale słabsza niż trzecia forma normalna i normalna forma Boyce-Codda. W rzeczywistości przynależność do drugiej formy normalnej jest zawarta w definicji trzeciej, a sama druga forma z kolei obejmuje pierwszą formę normalną. Forma normalna Boyce-Codda jest wzmocniona nie tylko w stosunku do trzeciej formy normalnej, ale także w stosunku do wszystkich innych ją poprzedzających. Z kolei trzecia postać normalna jest osłabiona tylko w stosunku do postaci normalnej Boyce-Codda. Wykład nr 11. Projektowanie schematów baz danych Najpopularniejszym sposobem abstrahowania schematów baz danych przy projektowaniu na poziomie logicznym jest tzw model encji-relacji. Czasami jest również nazywany Model ER, gdzie ER jest skrótem od angielskiego wyrażenia Entity - Relationship, które dosłownie tłumaczy się jako "entity - relations". Elementami takich modeli są klasy encji, ich atrybuty i relacje. Podamy wyjaśnienia i definicje każdego z tych elementów. Klasa podmiotu jest jak bezmetodowa klasa obiektów w sensie programowania obiektowego. Podczas przechodzenia do warstwy fizycznej klasy jednostek są konwertowane na podstawowe relacje relacyjnej bazy danych dla określonych systemów zarządzania bazami danych. Podobnie jak same podstawowe relacje, mają swoje własne atrybuty. Podajmy dokładniejszą i bardziej rygorystyczną definicję przedstawionych przed chwilą obiektów. klasa nazywa się nazwanym opisem zbioru obiektów o wspólnych atrybutach, operacjach, relacjach i semantyce. Graficznie klasa jest zwykle przedstawiana jako prostokąt. Każda klasa musi mieć nazwę (ciąg tekstowy), która jednoznacznie odróżnia ją od wszystkich innych klas. atrybut klasy jest nazwaną właściwością klasy, która opisuje zestaw wartości, jakie mogą przyjmować instancje tej właściwości. Klasa może mieć dowolną liczbę atrybutów (w szczególności może nie mieć atrybutów). Właściwość wyrażona przez atrybut to właściwość modelowanej jednostki, która jest wspólna dla wszystkich obiektów danej klasy. Tak więc atrybut jest abstrakcją stanu obiektu. Każdy atrybut dowolnego obiektu klasy musi mieć jakąś wartość. Tak zwane relacje są realizowane za pomocą deklaracji kluczy obcych (podobne zjawiska spotkaliśmy już wcześniej), tj. w relacji deklarowane są klucze obce, które odnoszą się do kluczy podstawowych lub kandydujących jakiejś innej relacji. W ten sposób kilka różnych niezależnych podstawowych relacji jest „połączonych” w jeden system zwany bazą danych. Ponadto diagram, który stanowi graficzną podstawę modelu relacji encji, jest przedstawiony za pomocą zunifikowanego języka modelowania UML. Wiele książek jest poświęconych językowi modelowania obiektowego UML (lub Unified Modeling Language), z których wiele zostało przetłumaczonych na język rosyjski (a niektóre napisane przez rosyjskich autorów). Ogólnie rzecz biorąc, UML umożliwia modelowanie różnych typów systemów: czysto programowych, czysto sprzętowych, programowo-sprzętowych, mieszanych, wyraźnie obejmujących działalność człowieka itp. Ale między innymi, jak już wspomnieliśmy, język UML jest aktywnie wykorzystywany do projektowania relacyjnych baz danych. W tym celu wykorzystuje się niewielką część języka (diagramy klas), a nawet nie w całości. Z perspektywy projektowania relacyjnych baz danych możliwości modelowania nie różnią się zbytnio od możliwości diagramów ER. Chcieliśmy również pokazać, że w kontekście projektowania relacyjnych baz danych metody projektowania strukturalnego oparte na wykorzystaniu diagramów ER oraz metody obiektowe oparte na wykorzystaniu języka UML różnią się głównie jedynie terminologią. Model ER jest koncepcyjnie prostszy niż UML, ma mniej pojęć, terminów i opcji aplikacji. Jest to zrozumiałe, ponieważ różne wersje modeli ER zostały opracowane specjalnie do obsługi projektowania relacyjnych baz danych, a modele ER nie zawierają prawie żadnych funkcji, które wykraczałyby poza rzeczywiste potrzeby projektanta relacyjnych baz danych. UML należy do świata obiektów. Ten świat jest znacznie bardziej skomplikowany (jeśli chcesz, bardziej niezrozumiały, bardziej zagmatwany) niż świat relacyjny. Ponieważ UML może być używany do ujednoliconego modelowania obiektowego czegokolwiek, język ten zawiera mnóstwo pojęć, terminów i przypadków użycia, które są zbędne z perspektywy projektowania relacyjnych baz danych. Jeśli wydobędziemy z ogólnego mechanizmu diagramów klas to, co jest naprawdę wymagane do projektowania relacyjnych baz danych, to otrzymamy dokładnie diagramy ER z inną notacją i terminologią. Ciekawe, że podczas tworzenia nazw klas w UML dozwolona jest dowolna kombinacja liter, cyfr, a nawet znaków interpunkcyjnych. Jednak w praktyce zaleca się używanie krótkich i znaczących przymiotników i rzeczowników jako nazw klas, z których każda zaczyna się wielką literą. (Omówimy koncepcję diagramu bardziej szczegółowo w następnym akapicie naszego wykładu.) 1. Różne rodzaje i wielokrotności wiązań Relacja między relacjami w projektowaniu schematów bazy danych jest przedstawiona jako linie łączące klasy jednostek. Co więcej, każdy z końców połączenia może (i generalnie powinien) charakteryzować się nazwą (tj. rodzajem połączenia) oraz wielokrotnością roli klasy w połączeniu. Rozważmy bardziej szczegółowo pojęcia wielości i rodzaje połączeń. wielość (wielkość) to cecha, która wskazuje, ile atrybutów klasy encji z daną rolą może lub powinno uczestniczyć w każdym wystąpieniu pewnego rodzaju relacji. Najczęstszym sposobem ustawienia liczności roli relacji jest bezpośrednie określenie określonej liczby lub zakresu. Na przykład określenie „1” mówi, że każda klasa z daną rolą musi uczestniczyć w jakiejś instancji tego połączenia, a dokładnie jeden obiekt klasy z tą rolą może brać udział w każdej instancji tego połączenia. Określenie zakresu „0..1” oznacza, że nie wszystkie obiekty klasy z daną rolą muszą uczestniczyć w dowolnym wystąpieniu tej relacji, ale tylko jeden obiekt może brać udział w każdym wystąpieniu relacji. Porozmawiajmy bardziej szczegółowo o wielości. Typowymi, najczęstszymi kardynałami w systemach projektowania baz danych są następujące kardynalności: 1) 1 - wielokrotność połączenia na odpowiadającym mu końcu jest równa jeden; 2) 0... 1 - такая форма записи означает, что кратность данной связи на соответствующем своем конце не может превышать единицы; 3) 0... ∞ - такая кратность расшифровывается просто "много". Любопытно, что, как правило, "много" означает "ничего"; 4) 1... ∞ - такое обозначение получила кратность "один или более". Podajmy przykład prostego diagramu ilustrującego pracę z różnymi krotnościami linków.
Zgodnie z tym diagramem łatwo zrozumieć, że każda kasa ma wiele biletów, a z kolei każdy bilet znajduje się w jednej (i nie więcej) kasie. Rozważmy teraz najpopularniejsze typy lub nazwy linków. Wymieńmy je: 1) 1: 1 - takie oznaczenie nadano złączu "Jeden na jednego„tj. jest to niejako korespondencja jeden do jednego dwóch zestawów; 2) 1 : 0... ∞ - это обозначение связи типа "jeden za dużo„. 3) 0... ∞ : 1 - это обращение предыдущей связи или связь типа "wiele do jednego"; 4) 0... ∞ : 0... ∞ - это обозначение связи типа "wiele do wielu", tj. na każdym końcu linku znajduje się wiele atrybutów; 5) 0... 1 : 0... 1 - это связь, аналогичная введенной ранее связи типа "один к одному", она, в свою очередь, называется "nie więcej niż jeden do nie więcej niż jednego"; 6) 0... 1 : 0... ∞ - это связь, аналогичная связи типа "один ко многим", она называется "не более одного ко многим"; 7) 0... ∞ : 0... 1 - это связь, в свою очередь, аналогичная связи типа "многие к одному", она называется "od wielu do nie więcej niż jednego". Jak widać, ostatnie trzy połączenia zostały uzyskane z połączeń, które są wymienione w naszym wykładzie pod numerami jeden, dwa i trzy, zastępując wielokrotność „jeden” wielokrotnością „nie więcej niż jeden”. 2. Diagramy. Rodzaje wykresów A teraz przejdźmy w końcu bezpośrednio do rozważenia diagramów i ich typów. Ogólnie rzecz biorąc, istnieją trzy poziomy modelu logicznego. Poziomy te różnią się głębokością reprezentacji informacji o strukturze danych. Poziomy te odpowiadają następującym diagramom: 1) schemat prezentacji; 2) kluczowy schemat; 3) kompletny diagram atrybutów. Przeanalizujmy każdy z tych typów diagramów i wyjaśnijmy szczegółowo znaczenie ich różnic w głębokości prezentacji informacji o strukturze danych. 1. Презентационная диаграмма. Takie diagramy opisują tylko najbardziej podstawowe klasy jednostek i ich relacje. Klucze na takich schematach mogą nie być w ogóle opisywane, a zatem połączenia nie mogą być w żaden sposób zindywidualizowane. Dlatego relacje wiele-do-wielu są akceptowalne, chociaż zwykle unika się ich lub, jeśli istnieją, dopracowuje się je. Atrybuty złożone i wielowartościowe są również całkowicie poprawne, chociaż pisaliśmy wcześniej, że relacje bazowe z takimi atrybutami nie są zredukowane do żadnej normalnej postaci. Co ciekawe, z trzech rozważanych przez nas typów diagramów, tylko ostatni typ (pełny diagram atrybutów) zakłada, że prezentowane w nim dane są w jakiejś normalnej postaci. Natomiast rozważany już diagram prezentacji i następny w kolejności diagram kluczowy nie implikują niczego w tym rodzaju. Takie diagramy są zwykle używane do prezentacji (stąd ich nazwa - prezentacyjna, czyli używana do prezentacji, pokazów, gdzie nie jest potrzebna zbytnia szczegółowość). Niekiedy przy projektowaniu baz danych konieczne jest skonsultowanie się z ekspertami w dziedzinie, z jaką ta konkretna baza danych zajmuje się informacją. Wtedy też stosuje się diagramy prezentacyjne, ponieważ aby uzyskać potrzebne informacje od specjalistów w zawodzie dalekim od programowania, nie jest w ogóle wymagane nadmierne doprecyzowanie konkretnych szczegółów. 2. Ключевая диаграмма. W przeciwieństwie do diagramów prezentacyjnych, diagramy kluczowe z konieczności opisują wszystkie klasy jednostek i ich relacje, jednak tylko w kategoriach kluczy podstawowych. Tutaj relacje wiele-do-wielu są już koniecznie szczegółowe (tj. relacje tego typu w ich czystej postaci po prostu nie mogą być tutaj określone). Atrybuty wielowartościowe są nadal dozwolone w taki sam sposób, jak w diagramie prezentacji, ale jeśli są obecne na diagramie klucza, zwykle są konwertowane na niezależne klasy jednostek. Ale, co ciekawe, jednoznaczne atrybuty wciąż mogą być niekompletnie reprezentowane lub opisywane jako złożone. Te „swobody”, które nadal obowiązują w takich diagramach jak prezentacja i diagramy kluczowe, nie są dozwolone w kolejnym typie diagramu, ponieważ określają, że relacja bazowa nie jest znormalizowana. Można więc wnioskować, że diagramy kluczowe w przyszłości zakładają tylko „wiszące” atrybuty na już opisanych klasach encji, czyli za pomocą diagramu prezentacji wystarczy opisać najpotrzebniejsze klasy encji, a następnie za pomocą diagramu klucza dodać wszystko do niego niezbędne atrybuty i wyszczególnij wszystkie najważniejsze linki. 3. Полная атрибутивная диаграмма. Pełne diagramy atrybutów opisują najbardziej szczegółowo wszystkie powyższe klasy encji, ich atrybuty i relacje między tymi klasami encji. Z reguły takie wykresy reprezentują dane, które są w trzeciej postaci normalnej, więc naturalne jest, że w podstawowych relacjach opisywanych przez takie wykresy nie są dozwolone atrybuty złożone lub wielowartościowe, podobnie jak nie ma nieziarnistych atrybutów wiele-do- wiele relacji. Jednak pełne wykresy atrybutów nadal mają wadę, tzn. nie mogą być w pełni nazwane najbardziej kompletnymi wykresami pod względem prezentacji danych. Na przykład specyfika konkretnych systemów zarządzania bazami danych przy korzystaniu z pełnych diagramów atrybutów nadal nie jest brana pod uwagę, aw szczególności typ danych jest określony tylko w zakresie niezbędnym dla wymaganego logicznego poziomu modelowania. 3. Asocjacje i migracja kluczy Nieco wcześniej rozmawialiśmy już o tym, czym są relacje w bazach danych. W szczególności relacja została nawiązana podczas deklarowania kluczy obcych relacji. Ale w tej części naszego kursu nie mówimy już o podstawowych relacjach, ale o kasach podmiotów. W tym sensie proces nawiązywania relacji nadal wiąże się z deklaracjami różnych kluczy, ale teraz mówimy o kluczach klas encji. Mianowicie proces nawiązywania relacji wiąże się z przeniesieniem prostego lub złożonego klucza podstawowego jednej klasy encji do innej klasy. Proces takiego transferu jest również nazywany klucz migracji. W tym przypadku klasa encji, której klucze podstawowe są przekazywane, nazywa się klasa rodzicielska, a klasa jednostek, do których migrowane są klucze obce, nazywa się klasa dzieci podmioty. W klasie jednostki podrzędnej atrybuty klucza otrzymują status atrybutów klucza obcego i mogą, ale nie muszą uczestniczyć w tworzeniu własnego klucza podstawowego. Tak więc, gdy klucz podstawowy jest migrowany z klasy nadrzędnej do klasy jednostki podrzędnej, w klasie podrzędnej pojawia się klucz obcy, który odwołuje się do klucza podstawowego klasy nadrzędnej. Dla wygody formułycznej reprezentacji migracji kluczy wprowadzamy następujące kluczowe markery: 1) PK - tak oznaczymy dowolny atrybut klucza podstawowego (klucz podstawowy); 2) FK - tym znacznikiem oznaczymy atrybuty klucza obcego (klucza obcego); 3) PFK - takim znacznikiem oznaczymy atrybut klucza głównego/obcego, czyli dowolny taki atrybut, który jest częścią jedynego klucza podstawowego jakiejś klasy encji i jednocześnie jest częścią jakiegoś klucza obcego tej samej klasy encji . Zatem atrybuty klasy jednostek ze znacznikami PK i FK tworzą klucz podstawowy tej klasy. I atrybuty ze znacznikami FK i PFK są częścią niektórych kluczy obcych tej klasy jednostek. Zasadniczo klucze można migrować na różne sposoby i w każdym takim przypadku powstaje jakiś rodzaj połączenia. Zastanówmy się więc, jakie są typy łączy w zależności od schematu migracji klucza. W sumie istnieją dwa kluczowe schematy migracji. 1. Schemat migracji ∀PK (PK |→PFK.); W tym wpisie symbol „|→” oznacza pojęcie „migruje”, czyli powyższy wzór będzie brzmiał następująco: każdy (każdy) atrybut klucza podstawowego PK klasy podmiotu nadrzędnego jest przekazywany (migruje) do główny klucz PFKlasa jednostki potomnej K, która oczywiście jest również kluczem obcym dla tej klasy. W tym przypadku mówimy o tym, że bez wyjątku każdy kluczowy atrybut klasy encji nadrzędnej musi zostać przeniesiony do klasy encji podrzędnej. Ten rodzaj połączenia nazywa się identyfikacja, ponieważ klucz klasy jednostki nadrzędnej jest całkowicie zaangażowany w identyfikację jednostek podrzędnych. Z kolei wśród linków typu identyfikującego są jeszcze dwa możliwe niezależne typy linków. Tak więc istnieją dwa rodzaje identyfikujących linków: 1) полностью идентифицирующими. Mówi się, że relacja identyfikująca jest w pełni identyfikująca wtedy i tylko wtedy, gdy atrybuty migrującego klucza podstawowego klasy jednostki nadrzędnej całkowicie tworzą klucz podstawowy (i obcy) klasy jednostki podrzędnej. W pełni identyfikujący związek jest również czasami nazywany kategoryczny, ponieważ w pełni identyfikująca relacja identyfikuje jednostki podrzędne we wszystkich kategoriach; 2) не полностью идентифицирующими. Relacja identyfikacyjna nazywana jest niepełną identyfikacją wtedy i tylko wtedy, gdy atrybuty migrującego klucza podstawowego klasy jednostki nadrzędnej tylko częściowo tworzą klucz podstawowy (i jednocześnie obcy) klasy jednostki podrzędnej. Tak więc oprócz klucza ze znacznikiem PFK będzie miał również klucz oznaczony PK. W tym przypadku klucz obcy PFK klasy jednostki podrzędnej będzie całkowicie określony przez klucz podstawowy PK klasy jednostki nadrzędnej, ale po prostu klucz podstawowy PK tej relacji podrzędnej nie będzie określony przez klucz podstawowy PK jednostki nadrzędnej klasy encji, będzie ona sama. 2. Schemat migracji ∃PK (PK |→ FK); Taki schemat migracji należy odczytywać w następujący sposób: istnieją takie atrybuty klucza podstawowego klasy jednostki nadrzędnej, które podczas migracji są przenoszone do obowiązkowych atrybutów niekluczowych klasy jednostki podrzędnej. Zatem w tym przypadku mówimy o tym, że niektóre, a nie wszystkie, jak w poprzednim przypadku, atrybuty klucza podstawowego klasy encji nadrzędnej są przenoszone do klasy encji podrzędnych. Dodatkowo, jeśli w poprzednim schemacie migracji zdefiniowano migrację do klucza podstawowego relacji potomnej, który jednocześnie stał się również kluczem obcym, to ostatni typ migracji określa, że atrybuty klucza podstawowego klasy encji nadrzędnej migrują do zwykłego , początkowo atrybuty niebędące kluczami, które następnie uzyskują status klucza obcego. Ten rodzaj połączenia nazywa się nieidentyfikujący, ponieważ rzeczywiście klucz nadrzędny nie jest całkowicie zaangażowany w tworzenie jednostek podrzędnych, po prostu ich nie identyfikuje. Wśród relacji nieidentyfikujących rozróżnia się również dwa możliwe typy relacji. Zatem relacje nieidentyfikujące są dwojakiego rodzaju: 1) обязательно неидентифицирующими. Mówi się, że relacje nieidentyfikujące są koniecznie nieidentyfikujące wtedy i tylko wtedy, gdy wartości Null dla wszystkich migrujących atrybutów kluczowych klasy jednostek podrzędnych są zabronione; 2) необязательно неидентифицирующими. Mówi się, że relacje nieidentyfikujące niekoniecznie są nieidentyfikujące wtedy i tylko wtedy, gdy dozwolone są wartości null dla niektórych migrujących atrybutów kluczowych klasy jednostek podrzędnych. Wszystkie powyższe podsumowujemy w formie poniższej tabeli, aby ułatwić zadanie usystematyzowania i zrozumienia przedstawionego materiału. Również w tej tabeli uwzględnimy informacje o tym, jakie typy relacji („nie więcej niż jeden do jednego”, „wiele do jednego”, „wiele do nie więcej niż jeden”) odpowiadają jakim typom relacji (w pełni identyfikujące, nie w pełni identyfikujące, niekoniecznie identyfikujące, niekoniecznie nieidentyfikujące). Tak więc między klasami jednostek nadrzędnych i podrzędnych ustanawiany jest następujący typ relacji, w zależności od typu relacji.
Widzimy więc, że we wszystkich przypadkach z wyjątkiem ostatniego odwołanie nie jest puste (nie jest puste) → 1. Zwróć uwagę na trend, że na macierzystym końcu połączenia we wszystkich przypadkach z wyjątkiem ostatniego, krotność jest ustawiona na „jeden”. Dzieje się tak dlatego, że wartość klucza obcego w przypadkach tych relacji (czyli w pełni identyfikujący, nie w pełni identyfikujący i niekoniecznie identyfikujący typy relacji) musi koniecznie odpowiadać (a co więcej, jedynej) wartości klucza podstawowego klasa jednostki nadrzędnej. A w tym drugim przypadku, ze względu na fakt, że wartość klucza obcego może być równa wartości Null (flaga ważności FK: null), krotność jest ustawiana na „nie więcej niż jeden” na końcu macierzystym relacja. Naszą analizę prowadzimy dalej. Na podrzędnym końcu połączenia we wszystkich przypadkach, z wyjątkiem pierwszego, krotność jest ustawiona na „wiele”. Dzieje się tak dlatego, że ze względu na niepełną identyfikację, jak w drugim przypadku (lub brak takiej identyfikacji w drugim i trzecim przypadku w ogóle), wartość klucza podstawowego klasy podmiotu nadrzędnego może wielokrotnie występować wśród wartości klucza obcego klasy podrzędnej. W pierwszym przypadku relacja jest w pełni identyfikująca, więc atrybuty klucza podstawowego klasy jednostki nadrzędnej mogą wystąpić tylko raz wśród atrybutów kluczy klasy jednostki podrzędnej. Wykład nr 12. Relacje klas podmiotów Tak więc wszystkie koncepcje, przez które przeszliśmy, a mianowicie diagramy i ich rodzaje, wielokrotności i typy relacji, a także rodzaje migracji kluczy, pomogą nam teraz w przejrzeniu materiału o tych samych związkach, ale już między konkretnymi klasami podmioty. Wśród nich, jak zobaczymy, są też różnego rodzaju połączenia. 1. Hierarchiczna relacja rekurencyjna Pierwszym rodzajem relacji między klasami encji, który rozważymy, jest tzw hierarchiczna relacja rekurencyjna. Ogólnie rekurencja (or link rekurencyjny) jest relacją klasy encji do samej siebie. Czasami, przez analogię do sytuacji życiowych, takie połączenie nazywane jest również „hakiem na ryby”. Hierarchiczna relacja rekurencyjna (lub po prostu rekurencja hierarchiczna) to dowolna rekurencyjna relacja typu „co najwyżej jeden-do-wielu”. Rekurencja hierarchiczna jest najczęściej używana do przechowywania danych w strukturze drzewa. Podczas określania hierarchicznej relacji rekurencyjnej klucz podstawowy klasy jednostki nadrzędnej (który w tym konkretnym przypadku działa również jako klasa jednostki podrzędnej) musi zostać zmigrowany jako klucz obcy do obowiązkowych atrybutów niekluczowych tej samej klasy jednostki. Wszystko to jest konieczne, aby zachować logiczną integralność samego pojęcia „rekurencji hierarchicznej”. Zatem biorąc pod uwagę wszystkie powyższe, możemy stwierdzić, że hierarchiczna relacja rekurencyjna może być tylko niekoniecznie nieidentyfikujące i żaden inny, ponieważ gdyby użyto jakiegokolwiek innego rodzaju relacji, wartości Null dla klucza obcego byłyby nieprawidłowe, a rekursja byłaby nieskończona. Należy również pamiętać, że atrybuty nie mogą występować dwukrotnie w tej samej klasie encji pod tą samą nazwą. Dlatego atrybutom migrowanego klucza należy nadać tak zwaną nazwę roli. Tak więc w hierarchicznej relacji rekurencyjnej atrybuty węzła są rozszerzane o klucz obcy, który jest opcjonalnym odniesieniem do klucza podstawowego węzła, który jest jego bezpośrednim przodkiem. Zbudujmy prezentację i kluczowe diagramy implementujące rekurencję hierarchiczną w relacyjnym modelu danych i podajmy przykład formy tabelarycznej. Najpierw stwórzmy diagram prezentacji:
Teraz zbudujmy bardziej szczegółowy - kluczowy diagram:
Rozważ przykład, który wyraźnie ilustruje taki rodzaj relacji, jak hierarchiczna relacja rekurencyjna. Dajmy nam następującą klasę encji, która podobnie jak w poprzednim przykładzie składa się z atrybutów „Kod przodka” i „Kod węzła”. Najpierw pokażmy tabelaryczną reprezentację tej klasy encji:
Teraz zbudujmy diagram reprezentujący tę klasę podmiotów. Aby to zrobić, wybieramy z tabeli wszystkie niezbędne do tego informacje: przodek węzła z kodem „jeden” nie istnieje lub nie jest zdefiniowany, z tego wnioskujemy, że węzeł „jeden” jest wierzchołkiem. Ten sam węzeł „jeden” jest przodkiem węzłów o kodzie „dwa” i „trzy”. Z kolei węzeł o kodzie „dwa” ma dwoje dzieci: węzeł o kodzie „cztery” i węzeł o kodzie „pięć”. A węzeł z kodem „trzy” ma tylko jedno dziecko – węzeł z kodem „sześć”. Biorąc więc pod uwagę wszystkie powyższe, zbudujmy strukturę drzewa, która odzwierciedla informacje o danych zawartych w poprzedniej tabeli:
Widzieliśmy więc, że naprawdę wygodne jest reprezentowanie struktur drzewiastych za pomocą hierarchicznej relacji rekurencyjnej. 2. Rekurencyjna komunikacja sieciowa Sieciowe rekurencyjne połączenie klas bytów między sobą jest niejako wielowymiarowym odpowiednikiem hierarchicznego połączenia rekurencyjnego, przez które już przeszliśmy. Tylko jeśli hierarchiczna rekurencja została zdefiniowana jako relacja rekurencyjna „co najwyżej jeden-do-wielu”, wtedy rekurencja sieci reprezentuje tę samą relację rekurencyjną, tylko typu „wiele do wielu”. Ze względu na fakt, że w tym połączeniu z każdej strony uczestniczy wiele klas podmiotów, nazywa się to połączeniem sieciowym. Jak już można się domyślić przez analogię z rekurencją hierarchiczną, łącza typu rekurencja sieciowa są przeznaczone do reprezentowania grafowych struktur danych (podczas gdy łącza hierarchiczne służą, jak pamiętamy, wyłącznie do implementacji struktur drzewiastych). Ale ponieważ w połączeniu typu rekurencji sieciowej określone są połączenia typu „wiele do wielu”, nie można obejść się bez ich dodatkowego uszczegółowienia. Dlatego w celu udoskonalenia wszystkich relacji wiele-do-wielu w schemacie konieczne staje się utworzenie nowej niezależnej klasy encji, która zawiera wszystkie odwołania do rodzica lub potomka relacji Ancestor-Descendant. Taka klasa jest ogólnie nazywana klasa jednostki asocjacyjnej. W naszym konkretnym przypadku (w bazach, które będziemy brać pod uwagę w naszym kursie) encja asocjacyjna nie posiada własnych dodatkowych atrybutów i nosi nazwę powołanie, ponieważ nazywa relacje przodek-potomek, odwołując się do nich. W związku z tym klucz podstawowy klasy encji reprezentującej hosty należy dwukrotnie migrować do klas encji asocjacyjnych. W tej klasie migrowane klucze muszą razem tworzyć złożony klucz podstawowy. Z powyższego możemy wywnioskować, że ustanawianie łączy przy użyciu rekurencji sieciowej nie powinno być całkowicie identyfikujące i nic więcej. Podobnie jak w przypadku korzystania z hierarchicznej relacji rekurencyjnej, w przypadku używania rekursji sieciowej jako relacji żaden atrybut nie może pojawić się dwukrotnie w tej samej klasie encji pod tą samą nazwą. W związku z tym, podobnie jak ostatnim razem, wyraźnie określono, że wszystkie atrybuty klucza migracji muszą otrzymać nazwę roli. Aby zilustrować działanie sieciowej komunikacji rekurencyjnej, zbudujmy prezentację i kluczowe diagramy implementujące rekurencję sieciową w relacyjnym modelu danych. Zacznijmy od diagramu prezentacji:
Teraz zbudujmy bardziej szczegółowy diagram kluczy:
Co tu widzimy? Widzimy, że oba połączenia na tym kluczowym diagramie są połączeniami „wiele do jednego”. Co więcej, wielość „0... ∞” lub wielość „wiele” znajduje się na końcu połączenia skierowanego w stronę nazewnictwa klasy bytów. Rzeczywiście istnieje wiele linków, ale wszystkie odnoszą się do jednego kodu węzła, który jest kluczem podstawowym klasy encji „Nodes”. I na koniec rozważmy przykład ilustrujący działanie takiego typu połączenia przez klasę encji, jaką jest rekurencja sieciowa. Dajmy tabelaryczną reprezentację jakiejś klasy encji, a także nazewniczą klasę encji zawierającą informacje o linkach. Przyjrzyjmy się tym tabelom. Węzły:
Linki:
Rzeczywiście, powyższa reprezentacja jest wyczerpująca: podaje wszystkie niezbędne informacje, aby łatwo odtworzyć zakodowaną tutaj strukturę grafu. Na przykład bez przeszkód widzimy, że węzeł z kodem „jeden” ma odpowiednio troje dzieci o kodach „dwa”, „trzy” i „cztery”. Widzimy również, że węzły z kodami „dwa” i „trzy” nie mają w ogóle potomków, a węzeł z kodem „cztery” ma (podobnie jak węzeł „jeden”) trzech potomków o kodach „jeden”, „dwóch” i trzy". Narysujmy wykres podany przez klasy encji podane powyżej:
Tak więc wykres, który właśnie zbudowaliśmy, to dane, dla których klasy encji zostały połączone za pomocą połączenia sieciowego typu rekursja. 3. Stowarzyszenie Ze wszystkich typów powiązań uwzględnionych w naszym szczególnym toku wykładów tylko dwa są powiązaniami rekurencyjnymi. Zdążyliśmy już je rozważyć, są to odpowiednio hierarchiczne i sieciowe łącza rekurencyjne. Wszystkie inne typy relacji, które musimy wziąć pod uwagę, nie są rekurencyjne, ale z reguły reprezentują relację kilku klas nadrzędnych i kilku klas jednostek podrzędnych. Co więcej, jak można się domyślić, klasy jednostek nadrzędnych i podrzędnych nigdy się nie pokrywają (w rzeczywistości nie mówimy już o rekurencji). Połączenie, które zostanie omówione w tej części wykładu, nazywa się asocjacją i odnosi się właśnie do nierekurencyjnego typu połączeń. Więc połączenie nazwane stowarzyszenie, jest implementowana jako relacja między wieloma klasami jednostek nadrzędnych i jedną klasą jednostek podrzędnych. A jednocześnie, co ciekawe, związek ten opisują relacje różnego typu. Warto również zauważyć, że podczas asocjacji może istnieć tylko jedna klasa encji nadrzędnej, tak jak w rekursji sieciowej, ale nawet w takiej sytuacji liczba relacji pochodzących z klasy encji podrzędnych musi wynosić co najmniej dwa. Co ciekawe, zarówno w asocjacji, jak iw rekurencji sieciowej istnieją specjalne rodzaje klas encji. Przykładem takiej klasy jest klasa jednostki podrzędnej. Rzeczywiście, w ogólnym przypadku, w asocjacji, klasa jednostek podrzędnych jest nazywana klasa jednostki asocjacyjnej. W szczególnym przypadku, gdy klasa encji asocjacyjnych nie posiada własnych dodatkowych atrybutów i zawiera tylko atrybuty migrujące wraz z kluczami podstawowymi z klas encji nadrzędnych, taka klasa jest nazywana klasa jednostek nazewniczych. Jak widać, istnieje niemal absolutna analogia z koncepcją jednostek asocjacyjnych i nazewniczych w sieciowym połączeniu rekurencyjnym. Najczęściej asocjacja służy do udoskonalania (rozwiązywania) relacji wiele-do-wielu. Zilustrujmy to stwierdzenie. Niech na przykład otrzymamy następujący schemat prezentacyjny, który opisuje schemat przyjmowania określonego lekarza w określonym szpitalu:
Ten diagram dosłownie oznacza, że w szpitalu jest wielu lekarzy i wielu pacjentów i nie ma innej relacji i korespondencji między lekarzami a pacjentami. Tak więc oczywiście przy takiej bazie danych administracja szpitala nigdy nie będzie miała jasności, jak umawiać wizyty u różnych lekarzy dla różnych pacjentów. Oczywiste jest, że użyte tutaj relacje wiele-do-wielu muszą być po prostu uszczegółowione, aby skonkretyzować relacje między różnymi lekarzami i pacjentami, innymi słowy, aby racjonalnie zorganizować harmonogram wizyt wszystkich lekarzy i ich pacjentów w Szpital. A teraz zbudujmy bardziej szczegółowy kluczowy diagram, w którym szczegółowo opiszemy wszystkie istniejące relacje wiele do wielu. W tym celu odpowiednio wprowadzimy nową klasę encji, nazwiemy ją „Odbiór”, która będzie działać jako klasa encji asocjacyjnych (później zobaczymy, dlaczego będzie to klasa encji asocjacyjnych, a nie tylko klasa nazewnictwa podmiotów, o których mówiliśmy wcześniej). Więc nasz kluczowy diagram będzie wyglądał tak:
Teraz wyraźnie widać, dlaczego nowa klasa „Odbieranie” nie jest klasą jednostek nazewniczych. W końcu ta klasa ma swój dodatkowy atrybut „Data - Czas”, dlatego zgodnie z definicją nowo wprowadzona klasa „Recepcja” jest klasą bytów asocjacyjnych. Ta klasa „kojarzy” ze sobą klasy jednostek „Lekarze” i „Pacjent” za pomocą czasu, w którym odbywa się ta lub inna wizyta, co znacznie ułatwia pracę z taką bazą danych. Tak więc, wprowadzając atrybut "Data - Czas", dosłownie zorganizowaliśmy bardzo potrzebny harmonogram pracy dla różnych lekarzy. Widzimy również, że zewnętrzny klucz podstawowy „Kod lekarza” klasy jednostki „Recepcja” odwołuje się do klucza podstawowego o tej samej nazwie klasy jednostki „Lekarze”. Podobnie zewnętrzny klucz podstawowy „Kod pacjenta” klasy encji „Recepcja” odnosi się do klucza podstawowego o tej samej nazwie w klasie encji „Pacjent”. W tym przypadku, oczywiście, klasy jednostek „Lekarze” i „Pacjent” są rodzicami, a powiązana klasa jednostek „Recepcja” jest z kolei jedynym dzieckiem. Widzimy, że relacja wiele-do-wielu z poprzedniego diagramu prezentacji jest teraz w pełni szczegółowa. Zamiast jednej relacji wiele-do-wielu, którą widzimy na powyższym diagramie prezentacji, mamy dwie relacje wiele-do-jednego. Potomek pierwszego związku ma wielokrotność „wielu”, co dosłownie oznacza, że klasa jednostek „Recepcja” ma wielu lekarzy (wszyscy są w szpitalu). A na końcu tej relacji jest wielość „jednego”, co to oznacza? Oznacza to, że w klasie encji „Recepcja” każdy z dostępnych kodów każdego konkretnego lekarza może wystąpić nieskończenie wiele razy. Rzeczywiście, w harmonogramie w szpitalu kod tego samego lekarza występuje wiele razy, w różnych dniach i godzinach. A oto ten sam kod, ale już w klasie encji „Doktorzy” może wystąpić raz i tylko raz. Rzeczywiście, na liście wszystkich lekarzy szpitalnych (a klasa podmiotu „Lekarze” to nic innego jak taka lista) kod każdego konkretnego lekarza może występować tylko raz. Podobnie dzieje się z relacją między klasą rodzicielską „Pacjent” a klasą potomną „Pacjent”. Na liście wszystkich pacjentów szpitala (w klasie jednostki „Pacjenci”) kod każdego konkretnego pacjenta może wystąpić tylko raz. Ale z drugiej strony w harmonogramie wizyt (w klasie encji „Recepcja”) każdy kod konkretnego pacjenta może wystąpić dowolnie wiele razy. Dlatego w ten sposób ułożone są krotności na końcach wiązania. Jako przykład implementacji asocjacji w relacyjnym modelu danych zbudujmy model opisujący harmonogram spotkań klienta z wykonawcą z opcjonalnym udziałem konsultantów. Nie będziemy się rozwodzić nad diagramem prezentacji, ponieważ musimy rozważyć konstrukcję diagramów we wszystkich szczegółach, a diagram prezentacji nie może zapewnić takiej możliwości. Zbudujmy więc kluczowy diagram, który odzwierciedla istotę relacji między klientem, wykonawcą a konsultantem.
Zacznijmy więc od szczegółowej analizy powyższego kluczowego diagramu. Po pierwsze, klasa „Graph” jest klasą encji asocjacyjnych, ale tak jak w poprzednim przykładzie nie jest klasą encji nazwanych, ponieważ posiada atrybut, który nie migruje do niej wraz z kluczami, ale jest jej własny atrybut. To jest atrybut „Data - Godzina”. Po drugie, widzimy, że atrybuty klasy encji podrzędnych „Wykres”, „Kod klienta”, „Kod wykonawcy” i „Data - godzina” tworzą złożony klucz podstawowy tej klasy encji. Atrybut „Kod doradcy” jest po prostu kluczem obcym klasy jednostki „Chart”. Należy pamiętać, że ten atrybut dopuszcza wartości Null wśród swoich wartości, ponieważ zgodnie z warunkiem obecność konsultanta na spotkaniu nie jest konieczna. Ponadto, po trzecie, zauważamy, że pierwsze dwa linki (z trzech dostępnych linków) nie są całkowicie identyfikujące. Mianowicie nie w pełni identyfikujący, ponieważ klucz migrujący w obu przypadkach (klucze podstawowe „Kod klienta” i „Kod wykonawcy”) nie tworzy całkowicie klucza podstawowego klasy encji „Graph”. Rzeczywiście, pozostaje atrybut „Data - Czas”, który jest również częścią złożonego klucza podstawowego. Na końcach obu tych niecałkowicie identyfikujących wiązań zaznaczono krotności „jeden” i „wiele”. Odbywa się to w celu pokazania (jak w przykładzie o lekarzach i pacjentach) różnicy między podaniem kodu klienta lub wykonawcy w różnych klasach podmiotów. Rzeczywiście, w klasie encji „Graph” dowolny kod klienta lub kontrahenta może wystąpić dowolną liczbę razy. Dlatego na tym, dziecko, końcu połączenia jest wielość „wielu”. A w klasie encji „Klienci” lub „Kontrahenci” każdy z kodów odpowiednio klienta lub kontrahenta może wystąpić raz i tylko raz, ponieważ każda z tych klas encji jest niczym innym jak kompletną listą wszystkich klientów i wykonawców. Dlatego na tym, nadrzędnym końcu połączenia, istnieje wiele „jednego”. I na koniec zwróć uwagę, że trzecia relacja, a mianowicie relacja klasy encji „Graph” z klasą encji „Konsultanci”, niekoniecznie jest nieidentyfikująca. Rzeczywiście, w tym przypadku mówimy o przeniesieniu atrybutu klucza „Kod konsultanta” klasy encji „Konsultanci” do atrybutu niekluczowego klasy encji „Graph” o tej samej nazwie, tj. klucza podstawowego klasa encji „Konsultanci” w klasie encji „Graph” nie identyfikuje klucza podstawowego już tej klasy. A poza tym, jak wspomniano wcześniej, atrybut „Kod doradcy” zezwala na wartości Null, więc tutaj używana jest właśnie nieidentyfikująca relacja. W ten sposób atrybut „Kod doradcy” uzyskuje status klucza obcego i nic więcej. Zwróćmy też uwagę na wielość linków umieszczonych na stronie nadrzędnej i podrzędnej tego nie do końca nieidentyfikującego linku. Jego macierzysty koniec ma wielokrotność „nie więcej niż jeden”. Rzeczywiście, jeśli przypomnimy sobie definicję relacji, która nie jest całkowicie nieidentyfikująca, zrozumiemy, że atrybut „Kod konsultanta” z klasy encji „Wykres” nie może odpowiadać więcej niż jednemu kodowi konsultanta z listy wszystkich konsultantów (która jest klasą jednostek „Konsultanci”). I generalnie może się okazać, że nie będzie odpowiadał żaden kod konsultanta (pamiętaj o checkboxie dopuszczalności wartości Null Kod konsultanta: Null), ponieważ zgodnie z warunkiem obecność konsultanta na spotkanie klienta z wykonawcą generalnie nie jest konieczne. 4. Uogólnienia Innym rodzajem relacji między klasami encji, który rozważymy, jest relacja formy uogólnienie. Jest to również nierekurencyjny rodzaj relacji. Tak więc związek taki jak uogólnienie jest zaimplementowana jako relacja jednej klasy encji nadrzędnych z kilkoma klasami encji podrzędnych (w przeciwieństwie do poprzedniej relacji Asocjacja, która dotyczyła kilku klas encji nadrzędnych i jednej klasy encji podrzędnych). Formułując reguły reprezentacji danych za pomocą relacji Generalization, należy od razu powiedzieć, że ta relacja jednej klasy encji nadrzędnych i kilku klas encji podrzędnych jest opisywana przez relacje w pełni identyfikujące, czyli relacje kategoryczne. Przypominając definicję w pełni identyfikujących relacji, dochodzimy do wniosku, że podczas korzystania z uogólnienia każdy atrybut klucza podstawowego klasy jednostki nadrzędnej jest przenoszony do klucza podstawowego klas jednostek podrzędnych, tj. atrybutów podstawowego klucza migracji nadrzędnej klasa encji całkowicie tworzy klucze podstawowe wszystkich klas encji podrzędnych , identyfikują je. Warto zauważyć, że Generalizacja wprowadza tzw hierarchia kategorii lub hierarchia dziedziczenia. W tym przypadku klasa jednostki nadrzędnej definiuje generyczna klasa encji, charakteryzujący się atrybutami wspólnymi dla bytów wszystkich klas potomnych lub tzw podmioty kategoryczne tj. klasa jednostek nadrzędnych jest dosłownym uogólnieniem wszystkich klas jednostek podrzędnych. Jako przykład implementacji uogólnienia w relacyjnym modelu danych zbudujemy następujący model. Model ten będzie oparty na uogólnionej koncepcji „Studentów” i będzie opisywał następujące pojęcia kategoryczne (tj. uogólni następujące klasy jednostek podrzędnych): „Uczniowie”, „Studentowie” i „Studenci studiów podyplomowych”. Zbudujmy więc kluczowy diagram, który odzwierciedla istotę relacji między klasą encji nadrzędnej a klasami encji podrzędnych, opisanej połączeniem typu Generalization.
Więc co widzimy? Po pierwsze, każdej z podstawowych relacji (lub z klas podmiotowych, czyli takich samych) „Uczniowie”, „Studenci” i „Studenci studiów podyplomowych” odpowiadają jej własnym atrybutom, takim jak „Klasa”, „Kurs” i „Rok studiów”. ”. Każdy z tych atrybutów charakteryzuje członków własnej klasy encji. Widzimy również, że klucz podstawowy klasy encji nadrzędnej „Studenci” migruje do każdej klasy encji podrzędnych i tworzy tam podstawowy klucz obcy. Za pomocą tych połączeń możemy określić kodem każdego ucznia jego imię, nazwisko i patronimię, o których informacji nie znajdziemy w odpowiednich klasach encji podrzędnych. Po drugie, ponieważ mówimy o w pełni identyfikującej (lub kategorycznej) relacji klas encji, zwrócimy uwagę na wielość relacji między klasą encji nadrzędnej a jej klasami potomnymi. Rodzicowy koniec każdego z tych łączy ma wielokrotność „jeden”, a każdy podrzędny koniec łączy ma wielokrotność „co najwyżej jeden”. Jeśli przypomnimy sobie definicję w pełni identyfikującej relacji klas encji, staje się jasne, że naprawdę unikalny kod ucznia, który jest kluczem podstawowym klasy encji „Uczniowie”, określa co najwyżej jeden atrybut z takim kodem w każdej encji potomnej klasy „Student”, „Studenci” i Doktoranci. Dlatego wszystkie obligacje mają właśnie takie krotności. Napiszmy fragment operatorów do tworzenia podstawowych relacji „Uczniowie” i „Uczniowie” wraz z określeniem zasad zachowania integralności referencyjnej typu kaskadowego. Więc mamy: Utwórz tabelę Uczniowie ... klucz podstawowy (kod studenta) klucz obcy (Student ID) referencje Studenci (Student ID) na kaskadzie aktualizacji po usunięciu kaskady Utwórz stół Uczniowie ... klucz podstawowy (kod studenta) klucz obcy (Student ID) referencje Studenci (Student ID) na kaskadzie aktualizacji przy usuwaniu kaskady; W ten sposób widzimy, że w klasie encji podrzędnej (lub relacji) „Student” określony jest podstawowy klucz obcy, który odwołuje się do klasy encji nadrzędnej (lub relacji) „Studenci”. Kaskadowa reguła zachowania integralności referencyjnej określa, że gdy atrybuty klasy jednostki nadrzędnej „Studenci” zostaną usunięte lub zaktualizowane, odpowiednie atrybuty relacji podrzędnej „Student” zostaną automatycznie (kaskadowo) zaktualizowane lub usunięte. Podobnie, gdy atrybuty klasy jednostki nadrzędnej „Uczniowie” zostaną usunięte lub zaktualizowane, odpowiednie atrybuty relacji podrzędnej „Uczniowie” również zostaną automatycznie zaktualizowane lub usunięte. Należy zauważyć, że stosuje się tutaj tę zasadę integralności referencyjnej, ponieważ w tym kontekście (lista uczniów) nie jest racjonalne zakazywanie usuwania i aktualizowania informacji, a także przypisywanie niezdefiniowanej wartości zamiast prawdziwych informacji . Podajmy teraz przykład klas encji opisanych na poprzednim diagramie, przedstawionych tylko w formie tabelarycznej. Mamy więc następujące tabele relacji: Uczniowie - relacja rodzicielska, która łączy informacje o atrybutach wszystkich innych relacji:
Dzieci w wieku szkolnym - relacja dziecka:
studentów - relacja drugiego dziecka:
Doktoranci - relacja trzeciego dziecka:
Tak więc rzeczywiście widzimy, że w klasach potomnych podmiotów nie ma informacji o nazwisku, imieniu i patronimice uczniów, tj. uczniów, studentów i doktorantów. Te informacje można uzyskać tylko poprzez odwołania do klasy jednostki nadrzędnej. Widzimy również, że różne kody uczniów w klasie jednostek „Studenci” mogą odpowiadać różnym klasom jednostek podrzędnych. Tak więc, o uczniu z kodem „1” Nikołaj Zabotin, nic nie jest znane w relacji rodzicielskiej, z wyjątkiem jego imienia, a wszystkie inne informacje (kim jest, uczeń, student lub doktorant) można znaleźć tylko poprzez odniesienie do odpowiedniej klasy jednostki podrzędnej (określonej przez kod). Podobnie musisz pracować z resztą uczniów, których kody są określone w klasie jednostki nadrzędnej „Studenci”. 5. Kompozycja Relacja klas jednostek typu kompozycja, podobnie jak dwie poprzednie, nie należy do typu relacji rekurencyjnej. Skład (lub, jak to się czasem nazywa, agregacja złożona) jest relacją pojedynczej klasy encji nadrzędnej z wieloma klasami encji podrzędnych, podobnie jak relacja, którą omówiliśmy powyżej. Uogólnienie. Ale jeśli uogólnienie zostało zdefiniowane jako relacja klas encji opisanych przez pełną identyfikację relacji, to z kolei kompozycja jest opisana przez niepełną identyfikację relacji, tj. Podczas tworzenia każdy atrybut klucza podstawowego nadrzędnej klasy encji migruje do atrybutu klucza klasy jednostki podrzędnej. Jednocześnie migrujące atrybuty klucza tylko częściowo tworzą klucz podstawowy klasy jednostki podrzędnej. Tak więc w przypadku agregacji złożonej (z kompozycją) klasa jednostki nadrzędnej (lub jednostka) jest powiązany z wieloma klasami jednostek podrzędnych (lub składniki). W takim przypadku składniki agregatu (tj. składniki klasy jednostki nadrzędnej) odwołują się do agregatu za pośrednictwem klucza obcego, który jest częścią klucza podstawowego i dlatego nie może istnieć poza agregatem. Ogólnie rzecz biorąc, agregacja złożona jest rozszerzoną formą agregacji prostej (o której powiemy nieco później). Kompozycja (lub złożona agregacja) charakteryzuje się tym, że: 1) odniesienie do zespołu jest zaangażowane w identyfikację części; 2) składniki te nie mogą istnieć poza agregatem. Agregacja (relacja, którą rozważymy dalej) z relacjami z konieczności nieidentyfikującymi również nie pozwala na istnienie komponentów poza agregacją, a zatem ma bliskie znaczenie realizacji agregacji złożonej opisanej powyżej. Zbudujmy diagram klucza opisujący relację między jedną klasą encji nadrzędnych a kilkoma klasami encji podrzędnych, tj. opisujący relację klas encji złożonego typu agregacji. Niech to będzie kluczowy diagram obrazujący kompozycję budynków określonego kampusu, w tym budynków, ich sal lekcyjnych i wind. Więc ten diagram będzie wyglądał tak:
Spójrzmy więc na diagram, który właśnie stworzyliśmy. Co w nim widzimy? Po pierwsze widzimy, że relacja użyta w tej złożonej agregacji jest rzeczywiście identyfikująca, a nawet nie w pełni identyfikująca. W końcu klucz podstawowy klasy encji nadrzędnej „Budynki” bierze udział w tworzeniu klucza podstawowego klas encji podrzędnych „Odbiorcy” i „Windy”, ale nie definiuje go całkowicie. Klucz podstawowy „Case No” klasy encji nadrzędnej migruje do obcych kluczy podstawowych „Case No” obu klas podrzędnych, ale oprócz tego migrowanego klucza obie klasy encji podrzędnych mają również swój własny klucz podstawowy, odpowiednio „Odbiorcy No” i „Elevator No.”, tj. złożone klucze podstawowe klas jednostek podrzędnych są tylko częściowo utworzonymi atrybutami klucza podstawowego klasy jednostek nadrzędnych. Przyjrzyjmy się teraz wielości linków łączących klasę rodzica i obie klasy podrzędne. Ponieważ mamy do czynienia z niepełną identyfikacją linków, występują krotności: „jeden” i „wiele”. Wielokrotność „jeden” występuje na końcu macierzystym obu relacji i symbolizuje, że na liście wszystkich dostępnych korpusów (a klasa encji „Corpus” jest właśnie taką listą), każda liczba może wystąpić tylko raz (i nie więcej). niż to) razy. I z kolei wśród atrybutów klas „Widzowie” i „Windy” każdy numer budynku może występować wielokrotnie, ponieważ jest więcej widowni (lub wind) niż budynków, a w każdym budynku jest kilka audytoriów i wind. Tak więc, wymieniając wszystkie sale lekcyjne i windy, nieuchronnie powtórzymy numery budynków. I na koniec, tak jak w przypadku poprzedniego typu połączenia, wypiszmy fragmenty operatorów do tworzenia podstawowych relacji (lub, co jest tym samym, klas encji) „Odbiorcy” i „Windy” i będziemy zrób to z definicją zasad zachowania integralności referencyjnej typu kaskadowego. Więc to stwierdzenie wyglądałoby tak: Utwórz tabelę Odbiorcy ... klucz podstawowy (numer korpusu, numer publiczności) klucz obcy (numer sprawy) referencje Wzorce (numer sprawy) na kaskadzie aktualizacji po usunięciu kaskady Utwórz tabelę Windy ... klucz podstawowy (numer sprawy, numer windy) klucz obcy (numer sprawy) referencje Wzorce (numer sprawy) na kaskadzie aktualizacji przy usuwaniu kaskady; W ten sposób ustawiliśmy wszystkie niezbędne klucze podstawowe i obce klas jednostek podrzędnych. Znowu zasadę zachowania integralności referencyjnej przyjęliśmy jako kaskadę, ponieważ określiliśmy ją już jako najbardziej racjonalną. Teraz podamy przykład w formie tabelarycznej wszystkich klas encji, które właśnie rozważaliśmy. Opiszmy te podstawowe relacje, które odzwierciedliliśmy za pomocą diagramu w postaci tabel, i dla jasności wprowadzimy tam pewną ilość danych orientacyjnych. Załączniki Relacja rodzicielska wygląda tak:
Widzowie - klasa podmiotu podrzędnego:
Windy - druga klasa encji podrzędnej klasy nadrzędnej „Załączniki”:
Możemy więc zobaczyć, w jaki sposób informacje są zorganizowane dla wszystkich budynków, ich sal lekcyjnych i wind w tej bazie danych, z której może korzystać każda instytucja edukacyjna w prawdziwym życiu. 6. Agregacja Agregacja to ostatni typ relacji między klasami encji, który zostanie uwzględniony w naszym kursie. Nie jest również rekurencyjna, a jeden z jej dwóch typów jest dość zbliżony do wcześniej rozważanej agregacji złożonej. W ten sposób zbiór jest relacją jednej klasy jednostki nadrzędnej z wieloma klasami jednostek podrzędnych. W tym przypadku relację można opisać dwoma rodzajami relacji: 1) koniecznie nieidentyfikujące linki; 2) opcjonalne linki nieidentyfikujące. Przypomnijmy, że w przypadku relacji niekoniecznie identyfikujących niektóre atrybuty klucza podstawowego klasy jednostki nadrzędnej są przenoszone do atrybutu niekluczowego klasy podrzędnej, a wartości Null dla wszystkich atrybutów klucza migrującego są zabronione. W przypadku relacji niekoniecznie nieidentyfikujących, migracja kluczy podstawowych odbywa się zgodnie z dokładnie tą samą zasadą, ale dozwolone są wartości Null dla niektórych atrybutów klucza migrującego. Podczas agregacji klasa jednostki nadrzędnej (lub jednostka) jest powiązany z wieloma klasami jednostek podrzędnych (lub składniki). Składniki agregatu (tj. klasa jednostki nadrzędnej) odwołują się do agregatu za pomocą klucza obcego, który nie jest częścią klucza podstawowego, a zatem w przypadku niekoniecznie nieidentyfikujące relacje, komponenty agregatu mogą istnieć poza agregatem. W przypadku agregacji z relacjami z konieczności nieidentyfikujących, składniki agregatu nie mogą istnieć poza agregatem iw tym sensie agregacja z relacjami z konieczności nieidentyfikującymi jest bliska agregacji złożonej. Teraz, gdy stało się już jasne, czym jest relacja typu agregacji, zbudujmy kluczowy diagram opisujący działanie tej relacji. Niech nasz przyszły schemat opisze zaznaczone elementy samochodów (a mianowicie silnik i podwozie). Jednocześnie przyjmiemy, że wycofanie samochodu z eksploatacji oznacza wycofanie z eksploatacji wraz z nim podwozia, ale nie oznacza jednoczesnego wycofania z eksploatacji silnika. Więc nasz kluczowy diagram wygląda tak:
Więc co widzimy na tym kluczowym diagramie? Po pierwsze, relacja klasy jednostki nadrzędnej "Samochody" z klasą jednostki podrzędnej "Silniki" niekoniecznie jest nieidentyfikująca, ponieważ atrybut "samochód #" dopuszcza wartości null wśród swoich wartości. Z kolei ten atrybut dopuszcza wartości zerowe z tego powodu, że wycofanie silnika z eksploatacji według stanu nie zależy od wycofania z eksploatacji całego pojazdu, a zatem niekoniecznie występuje podczas wycofania z eksploatacji samochodu. Widzimy również, że klucz podstawowy „Engine #” klasy jednostki „Samochody” migruje do atrybutu niekluczowego „Engine #” klasy jednostki „Silniki”. A jednocześnie ten atrybut zyskuje status klucza obcego. A kluczem podstawowym w tej klasie jednostek Engines jest atrybut Engine Marker, który nie odwołuje się do żadnego atrybutu relacji nadrzędnej. Po drugie, relacja między klasą jednostki nadrzędnej „Motors” a klasą jednostki podrzędnej „Chassis” jest z konieczności relacją nieidentyfikującą, ponieważ atrybut klucza obcego „Car #” nie zezwala na wartości Null wśród swoich wartości. To z kolei ma miejsce, ponieważ wiadomo pod warunkiem, że wycofanie samochodu z eksploatacji pociąga za sobą obowiązkowe jednoczesne wycofanie z eksploatacji podwozia. Tutaj, podobnie jak w przypadku poprzedniej relacji, klucz podstawowy klasy jednostki nadrzędnej „Silniki” jest migrowany do atrybutu niekluczowego „Numer samochodu” klasy jednostki podrzędnej „Podwozie”. Jednocześnie kluczem podstawowym tej klasy jednostek jest atrybut „Znacznik podwozia”, który nie odnosi się do żadnego atrybutu relacji nadrzędnej „Silniki”. Pójść dalej. Dla jak najlepszego przyswojenia tematu wypiszmy jeszcze raz fragmenty operatorów tworzenia podstawowych relacji „Silniki” i „Podwozie” wraz z określeniem zasad zachowania integralności referencyjnej. Utwórz silniki tabeli ... klucz główny (znacznik silnika) kluczyk obcy (nr pojazdu) referencje Samochody (nr pojazdu) na kaskadzie aktualizacji przy usuwaniu ustaw Null Utwórz podwozie stołu ... klucz główny (znacznik podwozia) kluczyk obcy (nr pojazdu) referencje Samochody (nr pojazdu) na kaskadzie aktualizacji przy usuwaniu kaskady; Widzimy, że wszędzie zastosowaliśmy tę samą zasadę zachowania integralności referencyjnej – kaskadę, bo już wcześniej uznawaliśmy ją za najbardziej racjonalną ze wszystkich. Tym razem jednak zastosowaliśmy (oprócz reguły kaskadowej) ustawioną regułę integralności referencyjnej Null. Ponadto użyliśmy go pod następującym warunkiem: jeśli jakaś wartość klucza podstawowego „Numer samochodu” z klasy podmiotu nadrzędnego „Samochody” zostanie usunięta, to wartość klucza obcego „Numer samochodu” relacji podrzędnej „Silniki” odwołujący się do niego zostanie przypisana wartość Null . 7. Ujednolicenie atrybutów Jeżeli podczas migracji kluczy podstawowych pewnej klasy encji nadrzędnych atrybuty z różnych klas nadrzędnych, które są zbieżne w znaczeniu, trafią do tej samej klasy potomnej, to atrybuty te muszą zostać „scalone”, czyli konieczne jest wykonanie tego -nazywa ujednolicenie atrybutów. Przykładowo w przypadku, gdy pracownik może pracować w organizacji, będąc wymienionym w nie więcej niż jednym dziale, po ujednoliceniu atrybutu „Kod organizacji” otrzymujemy następujący kluczowy diagram:
Podczas migracji klucza podstawowego z klas encji nadrzędnych „Organizacja” i „Dział” do klasy podrzędnej „Pracownicy” atrybut „Identyfikator organizacji” trafia do klasy encji „Pracownicy”. I dwa razy: 1) pierwszy raz z markerem PFK z klasy encji „Organizacja” przy ustanawianiu niecałkowicie identyfikującej relacji; 2) i drugi raz ze znacznikiem FK z warunkiem przyjęcia wartości Null z klasy encji „Departamenty” przy nawiązywaniu relacji niekoniecznie nieidentyfikującej. Po ujednoliceniu atrybut „Identyfikator organizacji” przyjmuje status atrybutu klucza podstawowego/obcego, przejmując status atrybutu klucza obcego. Zbudujmy nowy kluczowy diagram, który pokazuje sam proces unifikacji:
W ten sposób nastąpiła unifikacja atrybutów. Wykład nr 13. Systemy ekspertowe i model produkcji wiedzy 1. Powołanie systemów eksperckich Zapoznać się z tak nową dla nas koncepcją jak: systemy eksperckie my na początek przejdziemy przez historię powstania i rozwoju kierunku „systemy eksperckie”, a następnie zdefiniujemy samo pojęcie systemów eksperckich. Na początku lat 80-tych. XX wiek w badaniach nad tworzeniem sztucznej inteligencji ukształtował się nowy niezależny kierunek, zwany systemy eksperckie. Celem tych nowych badań nad systemami ekspertowymi jest opracowanie specjalnych programów przeznaczonych do rozwiązywania określonych typów problemów. Czym jest ten szczególny rodzaj problemu, który wymagał stworzenia zupełnie nowej inżynierii wiedzy? Ten szczególny rodzaj zadań może obejmować zadania z absolutnie dowolnego obszaru tematycznego. Najważniejszą rzeczą, która odróżnia je od zwykłych problemów, jest to, że ich rozwiązanie wydaje się być bardzo trudnym zadaniem dla człowieka-eksperta. Następnie pierwszy tak zwany system ekspercki (gdzie rolą eksperta nie była już osoba, ale maszyna), a system ekspertowy otrzymuje wyniki, które nie ustępują jakością i wydajnością rozwiązaniom uzyskanym przez zwykłego człowieka – eksperta. Wyniki pracy systemów ekspertowych można wyjaśnić użytkownikowi na bardzo wysokim poziomie. Tę jakość systemów ekspertowych zapewnia ich zdolność rozumowania na podstawie własnej wiedzy i wniosków. Systemy eksperckie mogą z powodzeniem uzupełniać własną wiedzę w procesie interakcji z ekspertem. W ten sposób można je z pełnym zaufaniem postawić na równi z w pełni ukształtowaną sztuczną inteligencją. Badacze w dziedzinie systemów eksperckich dla nazwy swojej dyscypliny często posługują się również wspomnianym wcześniej terminem „inżynieria wiedzy”, wprowadzonym przez niemieckiego naukowca E. Feigenbauma jako „wprowadzanie do rozwiązania zasad i narzędzi badawczych z dziedziny sztucznej inteligencji trudne stosowane problemy, które wymagają specjalistycznej wiedzy." Jednak komercyjny sukces firm deweloperskich nie przyszedł natychmiast. Przez ćwierć wieku od 1960 do 1985. Sukcesy sztucznej inteligencji związane są głównie z rozwojem badań. Jednak począwszy od około 1985 roku i na masową skalę od 1987 do 1990 roku. systemy ekspertowe są aktywnie wykorzystywane w zastosowaniach komercyjnych. Zalety systemów ekspertowych są dość duże i przedstawiają się następująco: 1) technologia systemów ekspertowych znacznie rozszerza zakres praktycznie istotnych zadań rozwiązywanych na komputerach osobistych, których rozwiązanie przynosi znaczne korzyści ekonomiczne i znacznie upraszcza wszystkie związane z tym procesy; 2) technologia systemów eksperckich jest jednym z najważniejszych narzędzi w rozwiązywaniu globalnych problemów tradycyjnego programowania, takich jak czas trwania, jakość, a co za tym idzie wysoki koszt tworzenia złożonych aplikacji, w wyniku czego efekt ekonomiczny został znacznie zmniejszony ; 3) wysokie koszty eksploatacji i utrzymania złożonych systemów, często kilkukrotnie przewyższające koszt samego opracowania, niski poziom ponownego wykorzystania programów itp.; 4) połączenie technologii systemów eksperckich z tradycyjną technologią programowania nadaje nowe właściwości produktom software'owym poprzez, po pierwsze, dynamiczną modyfikację aplikacji przez zwykłego użytkownika, a nie przez programistę; po drugie, większa „przejrzystość” aplikacji, lepsza grafika, interfejs i interakcja systemów eksperckich. Według zwykłych użytkowników i czołowych ekspertów, w niedalekiej przyszłości systemy eksperckie znajdą następujące zastosowania: 1) systemy eksperckie będą odgrywać wiodącą rolę na wszystkich etapach projektowania, rozwoju, produkcji, dystrybucji, debugowania, kontroli i świadczenia usług; 2) technologia systemów eksperckich, która otrzymała szeroką dystrybucję komercyjną, zapewni rewolucyjny przełom w integracji aplikacji z gotowych inteligentnych modułów współpracujących. Generalnie systemy ekspertowe przeznaczone są do tzw nieformalne zadania, czyli systemy eksperckie nie odrzucają i nie zastępują tradycyjnego podejścia do tworzenia programów nastawionego na rozwiązywanie sformalizowanych problemów, ale je uzupełniają, tym samym znacznie poszerzając możliwości. To jest dokładnie to, czego nie może zrobić zwykły ludzki ekspert. Tak złożone niesformalizowane zadania charakteryzują się: 1) błędność, niedokładność, niejednoznaczność, a także niekompletność i niespójność danych źródłowych; 2) błędność, niejednoznaczność, niedokładność, niekompletność i niespójność wiedzy o obszarze problemowym i rozwiązywanym problemie; 3) duży wymiar przestrzeni rozwiązań konkretnego problemu; 4) dynamiczna zmienność danych i wiedzy bezpośrednio w procesie rozwiązywania takiego nieformalnego problemu. Systemy eksperckie opierają się głównie na heurystycznym poszukiwaniu rozwiązania, a nie na wykonaniu znanego algorytmu. Jest to jedna z głównych przewag technologii systemów eksperckich nad tradycyjnym podejściem do tworzenia oprogramowania. To właśnie pozwala im tak dobrze radzić sobie z powierzonymi im zadaniami. Technologia systemów eksperckich służy do rozwiązywania różnych problemów. Wymieniamy główne z tych zadań. 1. Interpretacja. Systemy eksperckie dokonujące interpretacji najczęściej wykorzystują odczyty różnych instrumentów do opisu stanu rzeczy. Interpretacyjne systemy eksperckie są w stanie przetwarzać różnego rodzaju informacje. Przykładem jest wykorzystanie danych z analizy spektralnej i zmian w charakterystyce substancji do określenia ich składu i właściwości. Przykładem jest również interpretacja odczytów przyrządów pomiarowych w kotłowni w celu opisania stanu kotłów i wody w nich. Systemy interpretacyjne najczęściej zajmują się bezpośrednio wskazaniami. W związku z tym pojawiają się trudności, których nie mają inne typy systemów. Jakie są te trudności? Trudności te wynikają z faktu, że systemy ekspertowe muszą interpretować zatkane, zbędne, niepełne, niewiarygodne lub nieprawidłowe informacje. W związku z tym nieuniknione są błędy lub znaczny wzrost przetwarzania danych. 2. Przepowiednia. Systemy eksperckie, które przeprowadzają prognozę czegoś, określają probabilistyczne warunki danych sytuacji. Przykładami są prognoza szkód wyrządzonych w zbiorach zbóż przez niekorzystne warunki pogodowe, ocena zapotrzebowania na gaz na rynku światowym, prognozowanie pogody według stacji meteorologicznych. Systemy prognostyczne czasami wykorzystują modelowanie, tj. programy, które wyświetlają pewne zależności w świecie rzeczywistym w celu odtworzenia ich w środowisku programistycznym, a następnie projektują sytuacje, które mogą wystąpić z pewnymi danymi początkowymi. 3. Диагностика различных приборов. Systemy eksperckie przeprowadzają taką diagnostykę, wykorzystując opisy dowolnej sytuacji, zachowania lub dane dotyczące struktury różnych elementów w celu określenia możliwych przyczyn nieprawidłowego działania diagnozowalnego systemu. Przykładami są ustalenie okoliczności choroby na podstawie objawów obserwowanych u pacjentów (w medycynie); identyfikacja usterek w obwodach elektronicznych oraz identyfikacja wadliwych elementów w mechanizmach różnych urządzeń. Systemy diagnostyczne są dość często asystentami, którzy nie tylko stawiają diagnozę, ale także pomagają w rozwiązywaniu problemów. W takich przypadkach systemy te mogą wchodzić w interakcje z użytkownikiem, pomagając w rozwiązywaniu problemów, a następnie udostępniając listę działań wymaganych do ich rozwiązania. Obecnie wiele systemów diagnostycznych jest opracowywanych jako aplikacje do systemów inżynieryjnych i komputerowych. 4. Планирование различных событий. Systemy eksperckie przeznaczone do planowania projektowania różnych operacji. Systemy z góry określają prawie kompletną sekwencję działań przed rozpoczęciem ich realizacji. Przykładem takiego planowania wydarzeń jest tworzenie planów działań militarnych, zarówno defensywnych, jak i ofensywnych, z góry ustalonych na określony czas w celu uzyskania przewagi nad siłami wroga. 5. Design. Systemy eksperckie wykonujące projektowanie opracowują różne formy obiektów, biorąc pod uwagę panujące okoliczności i wszystkie związane z nimi czynniki. Przykładem jest inżynieria genetyczna. 6. Sterowanie. Systemy eksperckie, które sprawują kontrolę, porównują obecne zachowanie systemu z jego zachowaniem oczekiwanym. Obserwujące systemy eksperckie wykrywają kontrolowane zachowanie, które potwierdza ich oczekiwania w porównaniu z normalnym zachowaniem lub założeniem potencjalnych odchyleń. Kontrolujące systemy eksperckie ze swej natury muszą działać w czasie rzeczywistym i implementować zależną od czasu i kontekstową interpretację zachowania sterowanego obiektu. Przykłady obejmują monitorowanie odczytów przyrządów pomiarowych w reaktorach jądrowych w celu wykrycia sytuacji awaryjnych lub ocenę danych diagnostycznych od pacjentów na oddziale intensywnej terapii. 7. Управление. W końcu powszechnie wiadomo, że systemy eksperckie, które sprawują kontrolę, bardzo skutecznie zarządzają zachowaniem systemu jako całości. Przykładem jest zarządzanie różnymi branżami, a także dystrybucja systemów komputerowych. Systemy eksperckie sterowania muszą zawierać komponenty obserwacyjne w celu kontrolowania zachowania obiektu w długim okresie czasu, ale mogą również potrzebować innych komponentów z już przeanalizowanych typów zadań. Systemy eksperckie znajdują zastosowanie w różnych dziedzinach: transakcjach finansowych, przemyśle naftowym i gazowym. Technologia systemów eksperckich może być również zastosowana w energetyce, transporcie, przemyśle farmaceutycznym, kosmosie, hutnictwie i górnictwie, chemii i wielu innych dziedzinach. 2. Struktura systemów ekspertowych Rozwój systemów eksperckich ma wiele istotnych różnic w stosunku do rozwoju konwencjonalnego oprogramowania. Doświadczenie w tworzeniu systemów ekspertowych pokazało, że wykorzystanie w ich rozwoju metodologii przyjętej w tradycyjnym programowaniu albo znacznie zwiększa ilość czasu poświęcanego na tworzenie systemów ekspertowych, albo wręcz prowadzi do negatywnego wyniku. Systemy eksperckie dzieli się generalnie na statyczny и dynamiczny. Najpierw rozważ statyczny system ekspercki. standard statyczny system ekspercki składa się z następujących głównych elementów: 1) pamięć robocza, zwana również bazą danych; 2) bazy wiedzy; 3) rozwiązujący, zwany także tłumaczem; 4) elementy nabywania wiedzy; 5) składnik wyjaśniający; 6) komponent dialogowy. Przyjrzyjmy się teraz każdemu komponentowi bardziej szczegółowo. Pamięć robocza (przez absolutną analogię do pracy, tj. RAM komputera) jest przeznaczony do odbierania i przechowywania początkowych i pośrednich danych zadania, które jest rozwiązywane w danym momencie. Baza wiedzy przeznaczony jest do przechowywania długoterminowych danych opisujących konkretny obszar tematyczny oraz reguł opisujących racjonalne przekształcenie danych w tym obszarze rozwiązywanego problemu. Solvernazywany również interpretator, działa następująco: wykorzystując dane początkowe z pamięci roboczej i dane długoterminowe z bazy wiedzy, tworzy reguły, których zastosowanie do danych początkowych prowadzi do rozwiązania problemu. Jednym słowem, naprawdę „rozwiązuje” postawiony przed nim problem; Komponent pozyskiwania wiedzy automatyzuje proces wypełniania systemu eksperckiego wiedzą ekspercką, czyli to właśnie ten komponent dostarcza do bazy wiedzy wszystkie niezbędne informacje z tego konkretnego obszaru tematycznego. Wyjaśnij składnik wyjaśnia, w jaki sposób system uzyskał rozwiązanie tego problemu lub dlaczego nie otrzymał tego rozwiązania i jaką wiedzę wykorzystał przy tym. Innymi słowy, komponent wyjaśniania generuje raport z postępu. Komponent ten jest bardzo ważny w całym systemie eksperckim, ponieważ znacznie ułatwia testowanie systemu przez eksperta, a także zwiększa zaufanie użytkownika do uzyskanego wyniku, a tym samym przyspiesza proces rozwoju. Komponent okna dialogowego służy zapewnieniu przyjaznego interfejsu użytkownika zarówno w trakcie rozwiązywania problemu, jak i w procesie zdobywania wiedzy i deklarowania wyników pracy. Teraz, gdy wiemy już, z jakich komponentów generalnie składa się statystyczny system ekspercki, zbudujmy diagram, który odzwierciedla strukturę takiego systemu eksperckiego. To wygląda tak:
Statyczne systemy ekspertowe są najczęściej wykorzystywane w aplikacjach technicznych, gdzie możliwe jest nieuwzględnianie zmian w środowisku zachodzących podczas rozwiązywania problemu. Ciekawe, że pierwsze systemy eksperckie, które znalazły praktyczne zastosowanie, były właśnie statyczne. Na tym więc na razie zakończymy rozważanie statystycznego systemu eksperckiego, przejdźmy do analizy dynamicznego systemu eksperckiego. Niestety program naszego kursu nie zawiera szczegółowego rozpatrzenia tego systemu ekspertowego, więc ograniczymy się do analizy tylko najbardziej podstawowych różnic między dynamicznym systemem ekspertowym a statycznym. W przeciwieństwie do statycznego systemu eksperckiego, struktura dynamiczny system ekspercki Ponadto wprowadzono dwa następujące komponenty: 1) podsystem modelowania świata zewnętrznego; 2) podsystem relacji z otoczeniem zewnętrznym. Podsystem relacji z otoczeniem zewnętrznym Po prostu nawiązuje połączenia ze światem zewnętrznym. Robi to poprzez system specjalnych czujników i kontrolerów. Ponadto niektóre tradycyjne elementy statycznego systemu ekspertowego ulegają znaczącym zmianom, aby odzwierciedlić logikę czasową zdarzeń aktualnie zachodzących w środowisku. Jest to główna różnica między statycznymi a dynamicznymi systemami eksperckimi. Przykładem dynamicznego systemu ekspertowego jest zarządzanie produkcją różnych leków w przemyśle farmaceutycznym. 3. Uczestnicy rozwoju systemów ekspertowych W rozwój systemów ekspertowych zaangażowani są przedstawiciele różnych specjalności. Najczęściej konkretny system ekspercki jest opracowywany przez trzech specjalistów. Zwykle jest to: 1) ekspert; 2) inżynier wiedzy; 3) programista ds. rozwoju narzędzi. Wyjaśnijmy obowiązki każdego z wymienionych tutaj specjalistów. Ekspert jest specjalistą w dziedzinie, której zadania będą rozwiązywane za pomocą właśnie opracowywanego systemu eksperckiego. Inżynier wiedzy jest bezpośrednio specjalistą w zakresie rozwoju systemu ekspertowego. Stosowane przez niego technologie i metody nazywane są technologiami i metodami inżynierii wiedzy. Inżynier wiedzy pomaga ekspertowi zidentyfikować ze wszystkich informacji w danym obszarze informacje, które są niezbędne do pracy z konkretnym rozwijanym systemem eksperckim, a następnie ustrukturyzować go. Ciekawe, że brak inżynierów wiedzy wśród uczestników rozwoju, czyli zastępowanie ich przez programistów, albo prowadzi do niepowodzenia całego projektu tworzenia konkretnego systemu ekspertowego, albo znacząco wydłuża czas jego rozwoju. Oraz, w końcu, programista opracowuje narzędzia (jeśli narzędzia są nowo opracowane) zaprojektowane w celu przyspieszenia rozwoju systemów eksperckich. Narzędzia te zawierają, w granicach, wszystkie główne komponenty systemu eksperckiego; programista łączy również swoje narzędzia ze środowiskiem, w którym będzie używany. 4. Tryby pracy systemów ekspertowych System ekspertowy działa w dwóch głównych trybach: 1) w trybie zdobywania wiedzy; 2) w trybie rozwiązywania problemu (zwanym również trybem konsultacji lub trybem korzystania z systemu eksperckiego). Jest to logiczne i zrozumiałe, ponieważ najpierw trzeba niejako załadować system ekspertowy informacjami z dziedziny, w której ma pracować, jest to tryb „szkoleniowy” systemu ekspertowego, tryb, w którym otrzymuje wiedzę. A po załadowaniu wszystkich informacji niezbędnych do pracy następuje sama praca. System ekspercki jest gotowy do pracy i może być teraz wykorzystany do konsultacji lub rozwiązywania wszelkich problemów. Rozważmy bardziej szczegółowo tryb zdobywania wiedzy. W trybie zdobywania wiedzy praca z systemem ekspertowym realizowana jest przez eksperta za pośrednictwem inżyniera wiedzy. W tym trybie ekspert, korzystając z komponentu pozyskiwania wiedzy, zapełnia system wiedzą (danymi), co z kolei umożliwia systemowi rozwiązywanie problemów z tego obszaru tematycznego w trybie rozwiązywania bez udziału eksperta. Należy zauważyć, że tryb pozyskiwania wiedzy w tradycyjnym podejściu do tworzenia programów odpowiada etapom algorytmizacji, programowania i debugowania wykonywanym bezpośrednio przez programistę. Wynika z tego, że w przeciwieństwie do tradycyjnego podejścia, w przypadku systemów eksperckich tworzenie programów jest realizowane nie przez programistę, ale przez eksperta, oczywiście przy pomocy systemów eksperckich, czyli na ogół , osoba, która nie zna się na programowaniu. A teraz rozważmy drugi tryb funkcjonowania systemu ekspertowego, czyli tryb rozwiązywania problemów. W trybie rozwiązywania problemów (lub tzw. trybie konsultacji) komunikacja z systemami ekspertowymi realizowana jest bezpośrednio przez użytkownika końcowego, który jest zainteresowany efektem końcowym pracy, a czasem sposobem jego uzyskania. Należy zauważyć, że w zależności od przeznaczenia systemu ekspertowego użytkownik nie musi być ekspertem w tym obszarze problemowym. W tym przypadku zwraca się o wynik do systemów eksperckich, nie mając wystarczającej wiedzy do uzyskania wyników. Lub, użytkownik może nadal posiadać poziom wiedzy wystarczający do samodzielnego osiągnięcia pożądanego rezultatu. W takim przypadku użytkownik może sam uzyskać wynik, ale zwraca się do systemów ekspertowych, aby albo przyspieszyć proces uzyskiwania wyniku, albo przypisać monotonną pracę systemom ekspertowym. W trybie konsultacji dane o zadaniu użytkownika, po przetworzeniu przez komponent okna dialogowego, trafiają do pamięci roboczej. Solver na podstawie danych wejściowych z pamięci roboczej, ogólnych danych dotyczących obszaru problemu oraz reguł z bazy danych generuje rozwiązanie problemu. Rozwiązując problem, systemy ekspertowe nie tylko wykonują określoną sekwencję określonej operacji, ale także ją wstępnie formują. Odbywa się to w przypadku, gdy reakcja systemu nie jest do końca jasna dla użytkownika. W tej sytuacji użytkownik może zażądać wyjaśnienia, dlaczego ten system ekspercki zadaje określone pytanie lub dlaczego ten system ekspercki nie może wykonać tej operacji, w jaki sposób uzyskuje się ten lub inny wynik dostarczany przez ten system ekspercki. 5. Model produkcji wiedzy W jego centrum, modele produkcyjne wiedzy zbliżone do modeli logicznych, co pozwala na zorganizowanie bardzo efektywnych procedur logicznego wnioskowania o danych. To jest z jednej strony. Z drugiej jednak strony, jeśli weźmiemy pod uwagę produkcyjne modele wiedzy w porównaniu z modelami logicznymi, to te pierwsze wyraźniej prezentują wiedzę, co jest niepodważalną zaletą. Dlatego niewątpliwie model produkcji wiedzy jest jednym z głównych sposobów reprezentacji wiedzy w systemach sztucznej inteligencji. Zacznijmy więc od szczegółowego rozważenia koncepcji produkcyjnego modelu wiedzy. Tradycyjny model wiedzy produkcyjnej obejmuje następujące podstawowe elementy: 1) zbiór reguł (lub produkcji) reprezentujących bazę wiedzy systemu produkcyjnego; 2) pamięć operacyjną, w której przechowywane są fakty pierwotne, a także fakty wyprowadzone z faktów pierwotnych za pomocą mechanizmu wnioskowania; 3) sam mechanizm wnioskowania logicznego, który pozwala na podstawie dostępnych faktów, zgodnie z istniejącymi regułami wnioskowania, wyprowadzić nowe fakty. Co ciekawe, liczba takich operacji może być nieskończona. Każda reguła reprezentująca bazę wiedzy systemu produkcyjnego zawiera część warunkową i końcową. Warunkowa część reguły zawiera albo jeden fakt, albo kilka faktów połączonych spójnikiem. Ostatnia część reguły zawiera fakty, które należy uzupełnić pamięcią operacyjną, jeśli warunkowa część reguły jest prawdziwa. Jeśli spróbujemy schematycznie zobrazować produkcyjny model wiedzy, to produkcja jest rozumiana jako wyraz następującej postaci: (i) Q; P; A→B; N; Oto nazwa modelu produkcji wiedzy lub jego numer seryjny, za pomocą którego ta produkcja jest wyróżniana z całego zestawu modeli produkcyjnych, otrzymując jakąś identyfikację. Jakaś jednostka leksykalna odzwierciedlająca istotę tego produktu może pełnić rolę nazwy. W rzeczywistości nazywamy produkty dla lepszego postrzegania przez świadomość, aby uprościć wyszukiwanie pożądanego produktu z listy. Weźmy prosty przykład: kupno notesu” lub „zestawu kredek. Oczywiście każdy produkt jest zwykle określany słowami pasującymi do danej chwili. Innymi słowy, nazwij rzeczy po imieniu. Pójść dalej. Element Q charakteryzuje zakres tego konkretnego modelu produkcji wiedzy. Takie sfery są łatwo rozróżnialne w ludzkim umyśle, dlatego z reguły nie ma trudności z określeniem tego elementu. Weźmy przykład. Rozważmy następującą sytuację: powiedzmy, że w jednym obszarze naszej świadomości przechowywana jest wiedza o tym, jak gotować jedzenie, w innym, jak dostać się do pracy, w trzecim, jak prawidłowo obsługiwać pralkę. Podobny podział istnieje również w pamięci produkcyjnego modelu wiedzy. Taki podział wiedzy na odrębne obszary może znacznie zaoszczędzić czas poświęcony na poszukiwanie określonych modeli produkcyjnych wiedzy, które są w danej chwili potrzebne, a tym samym znacznie upraszcza proces pracy z nimi. Oczywiście głównym elementem produkcji jest jej tzw. rdzeń, który w naszym powyższym wzorze oznaczono jako A → B. Formuła ta może być interpretowana jako „jeżeli warunek A jest spełniony, to należy wykonać akcję B”. Jeśli mamy do czynienia z bardziej złożonymi konstrukcjami jądra, to po prawej stronie dozwolony jest następujący alternatywny wybór: „jeżeli warunek A jest spełniony, należy wykonać akcję B1, w przeciwnym razie należy wykonać akcję B2". Jednak interpretacja rdzenia produkcyjnego modelu wiedzy może być różna i zależeć od tego, co będzie po lewej i prawej stronie znaku sekwencyjnego „→”. Przy jednej z interpretacji rdzenia produkcyjnego modelu wiedzy sekwen można interpretować w zwykłym sensie logicznym, tj. jako znak logicznej konsekwencji działania B z prawdziwego warunku A. Niemniej jednak możliwe są również inne interpretacje rdzenia modelu produkcji wiedzy. A więc na przykład A może opisać pewien warunek, którego spełnienie jest konieczne, aby pewne działanie B mogło zostać wykonane. Następnie rozważamy element modelu produkcyjnego wiedzy R. Element Р definiuje się jako warunek zastosowania rdzenia produktu. Jeśli warunek P jest spełniony, aktywowany jest rdzeń produkcyjny. W przeciwnym razie, jeśli warunek P nie jest spełniony, czyli jest fałszywy, rdzeń nie może zostać aktywowany. Jako ilustrujący przykład rozważmy następujący model produkcji wiedzy: „Dostępność pieniędzy”; „Jeśli chcesz kupić rzecz A, powinieneś zapłacić jej koszt kasjerowi i przedstawić czek sprzedającemu”. Patrzymy, jeśli warunek P jest spełniony, czyli zakup jest opłacony i czek jest przedstawiony, to rdzeń jest aktywowany. Zakup zakończony. Jeżeli w tym modelu produkcji wiedzy warunek stosowalności rdzenia jest fałszywy, czyli nie ma pieniędzy, to nie można zastosować rdzenia modelu produkcji wiedzy i nie jest on aktywowany. I wreszcie przejdź do żywiołu N. Element N nazywany jest stanem końcowym modelu danych produkcyjnych. Warunek końcowy określa czynności i procedury, które należy wykonać po wdrożeniu rdzenia produkcyjnego. Dla lepszego zrozumienia podajmy prosty przykład: po zakupie rzeczy w sklepie konieczne jest zmniejszenie ilości rzeczy tego typu o jeden w inwentarzu towarów tego sklepu, czyli czy zakup jest dokonywany (stąd , rdzeń jest sprzedawany), wtedy sklep ma o jedną sztukę tego konkretnego produktu mniej. Stąd warunek końcowy „Wykreśl jednostkę zakupionego przedmiotu”. Podsumowując, można powiedzieć, że reprezentacja wiedzy jako zbioru reguł, czyli poprzez wykorzystanie produkcyjnego modelu wiedzy, ma następujące zalety: 1) to łatwość tworzenia i rozumienia poszczególnych reguł; 2) jest to prostota mechanizmu logicznego wyboru. Jednak w reprezentacji wiedzy w postaci zbioru reguł istnieją również wady, które wciąż ograniczają zakres i częstotliwość stosowania modeli wiedzy produkcyjnej. Główną taką wadą jest niejednoznaczność wzajemnych relacji między regułami składającymi się na określony model produkcji wiedzy, a regułami logicznego wyboru. Uwagi 1. Podkreślona czcionka w drukowanym wydaniu książki odpowiada: pogrubiona kursywa w tej (elektronicznej) wersji książki. (Ok. e. wyd.)
▪ Prawo ubezpieczeniowe. Notatki do wykładów ▪ Chirurgia dziecięca. Notatki do wykładów
Nowy sposób kontrolowania i manipulowania sygnałami optycznymi
05.05.2024 Klawiatura Primium Seneca
05.05.2024 Otwarto najwyższe obserwatorium astronomiczne na świecie
04.05.2024
▪ Czujniki do ochrony piłkarzy futbolu amerykańskiego ▪ Akcelerator optyczny sieci neuronowej ▪ Akumulatory Ampd Energy do dużych żurawi wieżowych.
▪ sekcja serwisu Prace elektryczne. Wybór artykułu ▪ artykuł A terpentyna do czegoś się przyda! Popularne wyrażenie ▪ artykuł Czym jest ekologia? Szczegółowa odpowiedź ▪ artykuł Płyń pontonem. Transport osobisty ▪ artykuł Aparat cyfrowy - skaner slajdów. Encyklopedia elektroniki radiowej i elektrotechniki
Strona główna | biblioteka | Artykuły | Mapa stony | Recenzje witryn
www.diagram.com.ua |



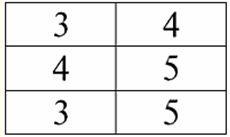
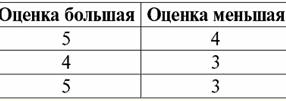

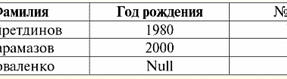

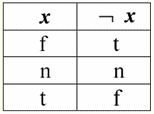

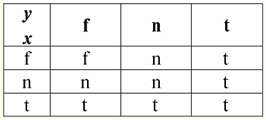
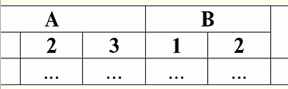


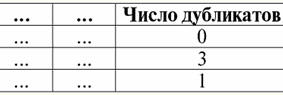
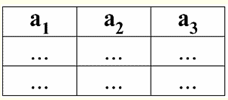






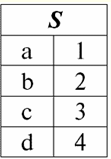
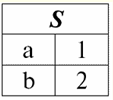

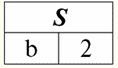
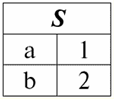

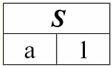
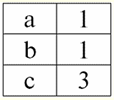

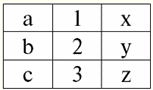









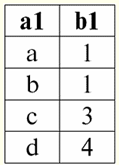






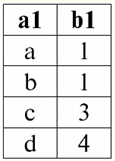



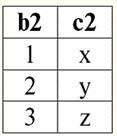

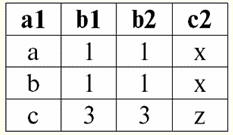




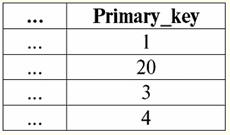

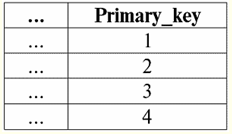

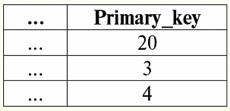
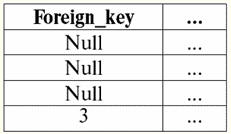

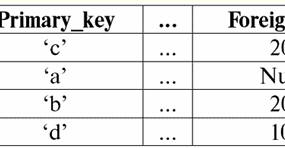











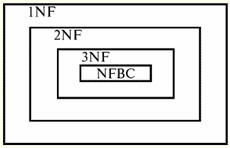

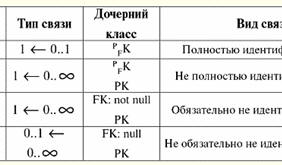









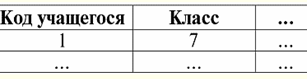
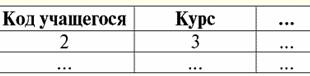





 Zobacz inne artykuły Sekcja
Zobacz inne artykuły Sekcja 