|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Notatki z wykładów, ściągawki
Informatyka i technologie informacyjne. Ściągawka: krótko, najważniejsza
Katalog / Notatki z wykładów, ściągawki Spis treści
1. Informatyka. Informacja Reprezentacja i przetwarzanie / informacja. Systemy liczbowe Informatyka zajmuje się sformalizowanym przedstawieniem obiektów i struktur ich relacji w różnych dziedzinach nauki, technologii i produkcji. Do modelowania obiektów i zjawisk wykorzystywane są różne narzędzia formalne, takie jak formuły logiczne, struktury danych, języki programowania itp. W informatyce tak podstawowe pojęcie jak informacja ma różne znaczenia: 1) formalne przedstawienie zewnętrznych form informacji; 2) abstrakcyjne znaczenie informacji, jej zawartość wewnętrzna, semantyka; 3) stosunek informacji do świata rzeczywistego. Ale z reguły informacja jest rozumiana jako jej abstrakcyjne znaczenie - semantyka. Jeśli chcemy dzielić się informacjami, potrzebujemy spójnych poglądów, aby nie naruszyć poprawności interpretacji. W tym celu interpretacja reprezentacji informacji jest utożsamiana z pewnymi strukturami matematycznymi. W takim przypadku przetwarzanie informacji może odbywać się za pomocą rygorystycznych metod matematycznych. Jednym z matematycznych opisów informacji jest jej reprezentacja jako funkcja y = f(x,t) gdzie jest czas, x to punkt w jakimś polu, w którym mierzona jest wartość y. W zależności od parametrów funkcji x i t informacje można sklasyfikować. Jeżeli parametry są wielkościami skalarnymi, które przyjmują ciągłą serię wartości, to uzyskaną w ten sposób informację nazywamy ciągłą (lub analogową). Jeśli parametry mają określony krok zmiany, wówczas informacja nazywana jest dyskretną. Informacje dyskretne są uważane za uniwersalne. Informacja dyskretna jest zwykle utożsamiana z informacją cyfrową, co jest szczególnym przypadkiem informacji symbolicznej o reprezentacji alfabetycznej. Alfabet to skończony zbiór symboli dowolnej natury. Bardzo często w informatyce dochodzi do sytuacji, w której znaki jednego alfabetu muszą być reprezentowane przez znaki innego, czyli musi zostać wykonana operacja kodowania. Jak pokazała praktyka, najprostszy alfabet, który pozwala na kodowanie innych alfabetów, jest binarny, składający się z dwóch znaków, które zwykle oznaczane są przez 0 i 1. Używając n znaków alfabetu binarnego, można zakodować 2n znaków, a to wystarczy zakodować dowolny alfabet. Wartość, która może być reprezentowana przez symbol alfabetu binarnego, nazywana jest minimalną jednostką informacji lub bitem. Sekwencja 8 bitów - bajty. Alfabet zawierający 256 różnych 8-bitowych sekwencji nazywany jest alfabetem bajtowym. System liczbowy to zestaw zasad dotyczących nazywania i pisania liczb. Istnieją pozycyjne i niepozycyjne systemy liczbowe. System liczbowy nazywa się pozycyjnym, jeśli wartość cyfry liczby zależy od położenia cyfry w liczbie. W przeciwnym razie nazywa się to niepozycyjnym. Wartość liczby jest określona przez położenie tych cyfr w liczbie. 2. Reprezentacja liczb w komputerze. Sformalizowana koncepcja algorytmu Procesory 32-bitowe mogą pracować z maksymalnie 232-1 RAM, a adresy mogą być zapisywane w zakresie 00000000 - FFFFFFFF. Jednak w trybie rzeczywistym procesor pracuje z pamięcią do 220-1, a adresy mieszczą się w zakresie 00000 - FFFFF. Bajty pamięci można łączyć w pola o stałej i zmiennej długości. Słowo to pole o stałej długości składające się z 2 bajtów, podwójne słowo to pole 4 bajtów. Adresy pól mogą być parzyste lub nieparzyste, a adresy parzyste są szybsze. Liczby stałoprzecinkowe są reprezentowane w komputerach jako liczby całkowite binarne, a ich rozmiar może wynosić 1, 2 lub 4 bajty. Liczby binarne całkowite są reprezentowane w uzupełnieniu do dwóch. Kod dopełnienia liczby dodatniej jest równy samej liczbie, a kod dopełnienia liczby ujemnej można uzyskać za pomocą następującego wzoru: x = 10n - \x\, gdzie n jest głębią bitową liczby. W systemie liczb binarnych dodatkowy kod uzyskuje się poprzez odwracanie bitów, czyli zastąpienie jednostek zerami i odwrotnie oraz dodanie jedynki do najmniej znaczącego bitu. Liczba bitów mantysy określa precyzję reprezentacji liczb, liczba bitów porządku maszynowego określa zakres reprezentacji liczb zmiennoprzecinkowych. Sformalizowana koncepcja algorytmu Algorytm może istnieć tylko wtedy, gdy w tym samym czasie istnieje jakiś obiekt matematyczny. Sformalizowane pojęcie algorytmu związane jest z pojęciem funkcji rekurencyjnych, normalnych algorytmów Markowa, maszyn Turinga. W matematyce funkcja jest nazywana jednowartościową, jeśli dla dowolnego zestawu argumentów istnieje prawo, zgodnie z którym określa się unikalną wartość funkcji. Algorytm może działać jako takie prawo; w tym przypadku mówi się, że funkcja jest obliczalna. Funkcje rekurencyjne są podklasą funkcji obliczalnych, a algorytmy definiujące obliczenia nazywane są algorytmami towarzyszących funkcji rekurencyjnych. Po pierwsze, podstawowe funkcje rekurencyjne są ustalone, dla których towarzyszący algorytm jest trywialny, jednoznaczny; następnie wprowadza się trzy reguły - operatory podstawienia, rekurencji i minimalizacji, za pomocą których uzyskuje się bardziej złożone funkcje rekurencyjne na podstawie funkcji podstawowych. Podstawowymi funkcjami i towarzyszącymi im algorytmami mogą być: 1) funkcja n zmiennych niezależnych, identycznie równych zero. Wtedy, jeśli znakiem funkcji jest φn, to niezależnie od liczby argumentów wartość funkcji powinna być równa zero; 2) identyczna funkcja n zmiennych niezależnych postaci Ψ ni. Następnie, jeśli znakiem funkcji jest Ψ ni, to wartość funkcji należy przyjąć jako wartość i-tego argumentu, licząc od lewej do prawej; 3) Funkcja λ jednego niezależnego argumentu. Następnie, jeśli znakiem funkcji jest λ, to wartość funkcji należy przyjąć jako wartość następującą po wartości argumentu. 3. Wprowadzenie do języka Pascal Podstawowe symbole języka - litery, cyfry i znaki specjalne - tworzą jego alfabet. Język Pascal zawiera następujący zestaw podstawowych symboli: 1) 26 małych liter łacińskich i 26 wielkich liter łacińskich: 2) _ (podkreślenie); 3) 10 cyfr: 0 1 2 3 4 5 6 7 8 9; 4) oznaki czynności: + - O / = <> < > <= >= := @; 5) ограничители:., ( ) [ ] (..) { } (* *).. : ; 6) specyfikatory: ^ # $; 7) słowa serwisowe (zastrzeżone): ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNKCJA, GOTO, JEŻELI, WDROŻENIE, IN, INDEX, DZIEDZICZONE, INLINE, INTERFEJS, PRZERWANIE, ETYKIETA, BIBLIOTEKA, MOD, NAZWA, BRAK, BLISKO, NIE, OBIEKT, LUB, OPAKOWANE, PRYWATNE, PROCEDURA, PROGRAMOWA, PUBLICZNA, NAGRYWAJ, POWTARZAJ, MIESZKAŃCA, ZESTAW, SHL, SHR, STRING, POTEM, DO, TYP, JEDNOSTKA, DO, ZASTOSOWANIA, VAR, WIRTUALNY, PODCZAS, Z, XOR. Oprócz wymienionych, zestaw podstawowych znaków zawiera spację. W Pascalu obowiązuje zasada: typ jest wyraźnie określony w deklaracji zmiennej lub funkcji poprzedzającej jej użycie. Koncepcja typu Pascal ma następujące główne właściwości: 1) dowolny typ danych definiuje zestaw wartości, do których należy stała, które może przyjąć zmienna lub wyrażenie, lub może wytworzyć operacja lub funkcja; 2) rodzaj wartości podanej przez stałą, zmienną lub wyrażenie można określić poprzez ich formę lub opis; 3) każda operacja lub funkcja wymaga argumentów typu stałego i daje wynik typu stałego. W Pascalu istnieją skalarne i strukturalne typy danych. Typy skalarne obejmują typy standardowe i typy zdefiniowane przez użytkownika. Typy standardowe obejmują typy całkowite, rzeczywiste, znakowe, logiczne i adresowe. Typy całkowite definiują stałe, zmienne i funkcje, których wartości są realizowane przez zbiór liczb całkowitych dozwolony na danym komputerze. Pascal ma następujące pierwszeństwo operatorów:
1) obliczenia w nawiasach; 2) obliczanie wartości funkcji; 3) operacje jednorazowe; 4) operacje * / div mod i; 5) operacje + - lub xor; 6) operacje relacyjne = <> < > <= >=. 4. Standardowe procedury i funkcje Funkcje arytmetyczne 1. Funkcja Abs (X); zwraca wartość bezwzględną parametru. 2. Funkcja ArcTan(X: Rozszerzona): Rozszerzona; zwraca arcus tangens argumentu. 3. Funkcja Exp(X: Real): Real; zwraca wykładnik. 4.Frac (X: Rzeczywisty): Rzeczywisty; zwraca część ułamkową argumentu. 5. Funkcja Int(X: Rzeczywista): Rzeczywista; zwraca część całkowitą argumentu. 6. Function Ln(X: Real): Real; возвращает натуральный логарифм (Ln е = 1) выражения x вещественного типа. 7. Funkcja Pi: Rozszerzona; zwraca wartość Pi, która jest zdefiniowana jako 3.1415926535. 8. Funkcja Sin (X: Rozszerzony): Rozszerzony; zwraca sinus argumentu. 9. Funkcja Sqr (X: Rozszerzona): Rozszerzona; zwraca kwadrat argumentu. 10. Function Sqrt (X: Rozszerzony): Rozszerzony; zwraca pierwiastek kwadratowy argumentu. Procedury i funkcje konwersji wartości 1. Procedura Str(X[:szerokość[:dziesiętne]];var S); konwertuje liczbę X na reprezentację ciągu. 2. Function Chr(X: Byte): Char; возвращает символ с порядковым номером x в ASCII-таблице. 3. Funkcja Wysoka (X); zwraca największą wartość w zakresie parametru. 4.Funkcja Niska(X); zwraca najmniejszą wartość z zakresu parametru. 5. FunctionOrd(X): LongInt; zwraca wartość porządkową wyrażenia typu wyliczeniowego. 6. Funkcja Runda (X: Rozszerzona): LongInt; zaokrągla wartość rzeczywistą do liczby całkowitej. 7. Funkcja Trunc(X: Extended): LongInt; obcina wartość typu rzeczywistego do liczby całkowitej. 8. Procedura Val(S; var V; var Code: Integer); konwertuje liczbę z wartości ciągu S na reprezentację numeryczną V. Procedury i funkcje pracy z wartościami porządkowymi 1. Procedura Dec(var X [; N: LongInt]); odejmuje jeden lub N od zmiennej X. 2. Procedura Inc(var X [; N: LongInt]); dodaje jeden lub N do zmiennej X. 3. Funkcja Odd(X: LongInt): Boolean; zwraca True, jeśli X jest liczbą nieparzystą, w przeciwnym razie False. 4.FunkcjaPred(X); zwraca poprzednią wartość parametru. 5 Funkcja Succ(X); zwraca następną wartość parametru. 5. Operatory języka Pascal Operator warunkowy Format pełnej instrukcji warunkowej jest zdefiniowany w następujący sposób: Jeśli B to S1 inaczej S2 gdzie B jest warunkiem rozgałęzienia (podejmowania decyzji), wyrażenia logicznego lub relacji; S1, S2 - jedna instrukcja wykonywalna, prosta lub złożona. Podczas wykonywania instrukcji warunkowej najpierw oceniane jest wyrażenie B, a następnie analizowany jest jego wynik: jeśli B jest prawdziwe, to wykonywana jest instrukcja S1 - gałąź to, a instrukcja S2 jest pomijana; jeśli B jest fałszywe, to instrukcja S2 - wykonywana jest gałąź else, a instrukcja S1 jest pomijana. Operator selekcji Struktura operatora jest następująca: przypadki c1: instrukcja1; c2: instrukcja2; ... cn: instrukcjaN; inna instrukcja puszki; gdzie S jest porządkowym wyrażeniem typu, którego wartość jest obliczana; c1, c2,..., on - константы порядкового типа, с которыми сравниваются выражения S; instructionl,..., instructionN - операторы, из которых выполняется тот, с константой которого совпадает значение выражения S; instrukcja - operator, który jest wykonywany, jeśli wartość wyrażenia S nie pasuje do żadnej ze stałych c1, o2, on. Instrukcja pętli z parametrem W momencie rozpoczęcia wykonywania instrukcji for wartości początkowe i końcowe są określane jednorazowo, a wartości te są zachowywane przez cały czas wykonywania instrukcji for. Instrukcja zawarta w treści instrukcji for jest wykonywana raz dla każdej wartości z zakresu między wartością początkową i końcową. Licznik pętli jest zawsze inicjowany wartością początkową. Instrukcja pętli z warunkiem wstępnym Podczas gdy B zrobić S; gdzie B jest warunkiem logicznym, którego prawdziwość jest sprawdzana (jest to warunek zakończenia pętli)$; S - treść pętli - jedna instrukcja. Wyrażenie sterujące powtarzaniem instrukcji musi być typu Boolean. Jest oceniany przed wykonaniem instrukcji wewnętrznej. Instrukcja wewnętrzna jest ponownie wykonywana, dopóki wyrażenie ma wartość Trie. Jeśli wyrażenie ma wartość False od początku, instrukcja zawarta w instrukcji pętli warunków wstępnych nie jest wykonywana. Instrukcja pętli z warunkiem końcowym powtarzaj S aż do B; gdzie B jest warunkiem logicznym, którego prawdziwość jest sprawdzana (jest to warunek zakończenia pętli); S - jedna lub więcej instrukcji treści pętli. Wynik wyrażenia musi być typu logicznego. Instrukcje zawarte między słowami kluczowymi repeat i until są wykonywane sekwencyjnie, dopóki wynikiem wyrażenia nie będzie True. Sekwencja instrukcji zostanie wykonana co najmniej raz, ponieważ wyrażenie jest oceniane po każdym wykonaniu sekwencji instrukcji. 6. Pojęcie algorytmu pomocniczego Algorytm rozwiązywania problemów został zaprojektowany przez rozłożenie całego problemu na oddzielne podzadania. Zazwyczaj podzadania są implementowane jako podprogramy. Podprogram to pewien algorytm pomocniczy, który jest wielokrotnie używany w algorytmie głównym z różnymi wartościami niektórych przychodzących wielkości, zwanych parametrami. Podprogram w językach programowania to ciąg instrukcji, które są zdefiniowane i zapisane tylko w jednym miejscu w programie, ale można je wywołać do wykonania z jednego lub kilku punktów programu. Każdy podprogram jest identyfikowany przez unikalną nazwę. W Pascalu istnieją dwa rodzaje podprogramów: procedury i funkcje. Procedura i funkcja to nazwana sekwencja deklaracji i instrukcji. Podczas korzystania z procedur lub funkcji program musi zawierać tekst procedury lub funkcji oraz wywołanie procedury lub funkcji. Parametry określone w opisie nazywane są formalnymi, te określone w wywołaniu podprogramu nazywane są rzeczywistymi. Wszystkie parametry formalne można podzielić na następujące kategorie: 1) parametry – zmienne; 2) parametry stałe; 3) wartości parametrów; 4) parametry procedury i parametry funkcji, tj. parametry typu proceduralnego; 5) niewpisane parametry zmiennych. Teksty procedur i funkcji znajdują się w opisach procedur i funkcji. Przekazywanie nazw procedur i funkcji jako parametrów W wielu problemach, zwłaszcza w matematyce obliczeniowej, konieczne jest przekazywanie nazw procedur i funkcji jako parametrów. W tym celu TURBO PASCAL wprowadził nowy typ danych - proceduralny lub funkcjonalny, w zależności od tego, co jest opisane. (Typy proceduralne i funkcyjne są opisane w sekcji deklaracji typu). Funkcja i typ proceduralny jest definiowany jako nagłówek procedury i funkcja z listą parametrów formalnych, ale bez nazwy. Możliwe jest zdefiniowanie funkcji lub typu proceduralnego bez parametrów, na przykład: rodzaj Proc = procedura; Po zadeklarowaniu typu proceduralnego lub funkcjonalnego może służyć do opisu parametrów formalnych – nazw procedur i funkcji. Ponadto konieczne jest napisanie tych rzeczywistych procedur lub funkcji, których nazwy będą przekazywane jako rzeczywiste parametry. 7. Procedury i funkcje w Pascalu Procedury w Pascalu Opis procedury składa się z nagłówka i bloku, które poza sekcją podłączenia modułu nie różnią się od bloku programu. Nagłówek składa się ze słowa kluczowego Procedure, nazwy procedury i opcjonalnej listy parametrów formalnych w nawiasach: Procedura <nazwa> [(<lista parametrów formalnych>)]; Dla każdego parametru formalnego należy zdefiniować jego typ. Grupy parametrów w opisie procedury są oddzielone średnikami. Struktura procedury jest prawie całkowicie podobna do programu. Jednak w bloku procedur nie ma sekcji podłączenia modułu. Blok składa się z dwóch części: opisowej i wykonawczej. Część opisowa zawiera opis elementów procedury. Natomiast w części wykonawczej akcje są wskazywane za pomocą dostępnych w procedurze elementów programu (np. zmiennych globalnych i stałych), które pozwalają uzyskać żądany wynik. Sekcja instrukcji procedury różni się od sekcji instrukcji programu tylko tym, że po słowie kluczowym End, które kończy sekcję, występuje średnik zamiast kropki. Instrukcja wywołania procedury służy do wywoływania procedury. Składa się z nazwy procedury oraz listy argumentów w nawiasach. Instrukcje, które mają zostać wykonane po uruchomieniu procedury, są zawarte w części instrukcji modułu procedury. Czasami chcesz, aby procedura sama się wywołała. Ten sposób wywoływania nazywa się rekurencją. Rekurencja jest przydatna w przypadkach, gdy zadanie główne można podzielić na podzadania, z których każde realizowane jest zgodnie z algorytmem pokrywającym się z głównym. Funkcje w Pascalu Deklaracja funkcji definiuje część programu, w której wartość jest obliczana i zwracana. Opis funkcji składa się z nagłówka i bloku. Nagłówek zawiera słowo kluczowe Function, nazwę funkcji, opcjonalną listę parametrów formalnych ujętą w nawiasy oraz typ zwracany funkcji. Ogólny widok nagłówka funkcji wygląda następująco: Function <nazwa> [(<lista parametrów formalnych>)]: <typ zwracany>; W implementacji Turbo Pascal 7.0 firmy Borland wartość zwracana przez funkcję nie może być typu złożonego. A język Object Pascal używany w zintegrowanych środowiskach programistycznych Borland Delphi pozwala na dowolny typ wyniku, z wyjątkiem typu pliku. Blok funkcyjny jest blokiem lokalnym o strukturze podobnej do bloku procedur. Treść funkcji musi zawierać co najmniej jedną instrukcję przypisania, po lewej stronie której znajduje się nazwa funkcji. To ona określa wartość zwracaną przez funkcję. Jeżeli jest kilka takich instrukcji, to wynikiem działania funkcji będzie wartość ostatniej wykonanej instrukcji przypisania. Funkcja jest aktywowana po wywołaniu funkcji. Gdy funkcja jest wywoływana, określany jest identyfikator funkcji i wszelkie parametry potrzebne do oceny funkcji. Wywołanie funkcji może być zawarte w wyrażeniach jako operand. Gdy wyrażenie jest oceniane, funkcja jest wykonywana, a wartość operandu staje się wartością zwracaną przez funkcję. Część operatora bloku funkcyjnego określa instrukcje, które muszą zostać wykonane, gdy funkcja jest aktywowana. Moduł musi zawierać co najmniej jedną instrukcję przypisania, która przypisuje wartość do identyfikatora funkcji. Wynikiem działania funkcji jest ostatnia przypisana wartość. Jeśli nie ma takiej instrukcji przypisania lub jeśli nie została wykonana, wartość zwracana przez funkcję jest niezdefiniowana. Jeżeli identyfikator funkcji jest używany podczas wywoływania funkcji w module - funkcji, to funkcja jest wykonywana rekurencyjnie. 8. Przekazywanie opisów i łączenie podprogramów. Dyrektywa Program może zawierać kilka podprogramów, tzn. struktura programu może być skomplikowana. Jednak te podprogramy mogą znajdować się na tym samym poziomie zagnieżdżenia, więc deklaracja podprogramu musi być pierwsza, a następnie wywołanie jej, chyba że jest używana specjalna deklaracja do przodu. Deklaracja procedury, która zawiera dyrektywę forward zamiast bloku instrukcji, nazywana jest deklaracją forward. W pewnym momencie po tej deklaracji procedura musi zostać zdefiniowana za pomocą deklaracji definiującej. Deklaracja definiująca to taka, która używa tego samego identyfikatora procedury, ale pomija listę parametrów formalnych i zawiera blok instrukcji. Deklaracja przekazująca i deklaracja definiująca muszą pojawić się w tej samej części procedury i deklaracji funkcji. Pomiędzy nimi można zadeklarować inne procedury i funkcje, które mogą odwoływać się do procedury przekazywania deklaracji. W ten sposób możliwa jest wzajemna rekurencja. Opis w przód i opis definiujący stanowią pełny opis procedury. Procedurę uważa się za opisaną za pomocą opisu wyprzedzającego. Jeśli program zawiera dość dużo podprogramów, to program przestanie być wizualny, trudno będzie się w nim poruszać. Aby tego uniknąć, niektóre podprogramy są przechowywane jako pliki źródłowe na dysku iw razie potrzeby są połączone z głównym programem na etapie kompilacji za pomocą dyrektywy kompilacji. Dyrektywa to specjalny komentarz, który można umieścić w dowolnym miejscu programu, gdzie może być normalny komentarz. Różnią się jednak tym, że dyrektywa ma specjalną notację: zaraz po nawiasie zamykającym bez spacji pisany jest znak $, a następnie ponownie bez spacji wskazana jest dyrektywa. Przykład: 1) {$E+} - emuluj koprocesor matematyczny; 2) {$F+} - tworzą daleki typ procedur i funkcji wywołujących; 3) {$N+} - użyj koprocesora matematycznego; 4) {$R+} - sprawdź, czy zakresy są poza granicami. Niektóre przełączniki kompilacji mogą zawierać parametr, na przykład: {$I nazwa pliku} - uwzględnij nazwany plik w tekście skompilowanego programu 9. Parametry podprogramu Opis procedury lub funkcji określa listę parametrów formalnych. Każdy parametr zadeklarowany na formalnej liście parametrów jest lokalny dla opisywanej procedury lub funkcji i może być przywoływany przez jego identyfikator w module skojarzonym z tą procedurą lub funkcją. Istnieją trzy typy parametrów: wartość, zmienna i zmienna bez typu. Charakteryzują się one następująco: 1. Grupa parametrów bez poprzedzającego słowa kluczowego to lista parametrów wartości. 2. Grupa parametrów poprzedzona słowem kluczowym const, po której następuje typ, jest listą parametrów stałych. 3. Grupa parametrów poprzedzona słowem kluczowym var, po której następuje typ to lista parametrów zmiennych. Parametry wartości Formalny parametr wartości jest traktowany jak zmienna lokalna dla procedury lub funkcji, z wyjątkiem tego, że pobiera swoją początkową wartość z odpowiedniego rzeczywistego parametru, gdy procedura lub funkcja jest wywoływana. Zmiany, którym przechodzi formalny parametr wartości, nie wpływają na wartość rzeczywistego parametru. Odpowiednia wartość parametru wartości rzeczywistej musi być wyrażeniem, a jego wartość nie może być typem pliku ani żadnym typem struktury zawierającym typ pliku. Rzeczywisty parametr musi być typu, którego przypisanie jest zgodne z typem formalnego parametru wartości. Jeśli parametr jest typu string, to formalny parametr będzie miał atrybut rozmiaru 255. Stałe parametry W treści podprogramu nie można zmienić wartości stałego parametru. Parametry-stałe mogą być użyte do uporządkowania tych parametrów, których zmiany w podprogramie są niepożądane i powinny być zabronione. Zmienne parametry Parametr zmiennej jest używany, gdy wartość musi zostać przekazana z podprogramu do bloku wywołującego. W tym przypadku, gdy podprogram jest wywoływany, parametr formalny jest zastępowany przez argument zmienny, a wszelkie zmiany parametru formalnego są odzwierciedlane w argumencie. Zmienne proceduralne Po zdefiniowaniu typu proceduralnego staje się możliwe opisywanie zmiennych tego typu. Takie zmienne nazywane są zmiennymi proceduralnymi. Podobnie jak zmienna typu integer, której można przypisać wartość typu integer, zmienna proceduralna może mieć przypisaną wartość typu proceduralnego. Taka wartość może oczywiście być inną zmienną proceduralną, ale może to być również identyfikator procedury lub funkcji. W tym kontekście deklarację procedury lub funkcji można postrzegać jako opis specjalnego rodzaju stałej, której wartością jest procedura lub funkcja. Jak w przypadku każdego innego przypisania, wartości zmiennej po lewej i prawej stronie muszą być zgodne z przypisaniem. Typy proceduralne, aby były zgodne z przypisaniem, muszą mieć taką samą liczbę parametrów, a parametry w odpowiednich pozycjach muszą być tego samego typu. Nazwy parametrów w deklaracji typu proceduralnego nie mają wpływu. Ponadto, aby zapewnić zgodność przypisania, procedura lub funkcja, jeśli ma być przypisana do zmiennej procedury, nie może być standardowa ani zagnieżdżona. 10. Rodzaje parametrów podprogramów Parametry wartości Formalny parametr wartości jest traktowany jako zmienna lokalna; pobiera swoją początkową wartość z odpowiedniego rzeczywistego parametru, gdy procedura lub funkcja jest wywoływana. Zmiany, którym przechodzi formalny parametr wartości, nie wpływają na wartość rzeczywistego parametru. Odpowiednia rzeczywista wartość parametru value musi być wyrażeniem, a jego wartość nie może być typu pliku. Stałe parametry Formalne parametry stałe uzyskują swoją wartość, gdy wywoływana jest procedura lub funkcja. Przypisania do stałego parametru formalnego są niedozwolone. Formalnego parametru stałego nie można przekazać jako rzeczywistego parametru do innej procedury lub funkcji. Zmienne parametry Parametr zmiennej jest używany, gdy wartość musi zostać przekazana z procedury lub funkcji do programu wywołującego. Po aktywacji formalna zmienna parametryczna jest zastępowana przez rzeczywistą zmienną, zmiany w formalnej zmiennej parametrycznej są odzwierciedlane w aktualnym parametrze. Niewpisane parametry Gdy parametr formalny jest parametrem zmiennej bez określonego typu, odpowiadający mu rzeczywisty parametr może być zmienną lub stałą referencją. Parametr bez typu zadeklarowany za pomocą słowa kluczowego var można modyfikować, natomiast parametr bez typu zadeklarowany za pomocą słowa kluczowego const jest tylko do odczytu. Zmienne proceduralne Po zdefiniowaniu typu proceduralnego staje się możliwe opisywanie zmiennych tego typu. Takie zmienne nazywane są zmiennymi proceduralnymi. Zmiennej proceduralnej można przypisać wartość typu proceduralnego. Procedura lub funkcja przy przydziale musi być: 1) niestandardowa; 2) nie zagnieżdżone; 3) nie jest postępowaniem typu inline; 4) nie w trybie przerwania. Parametry typu proceduralnego Ponieważ typy proceduralne mogą być używane w dowolnym kontekście, możliwe jest opisanie procedur lub funkcji, które przyjmują procedury i funkcje jako parametry. Parametry typu proceduralnego są szczególnie przydatne, gdy trzeba wykonać wspólne działania na wielu procedurach lub funkcjach. Jeśli procedura lub funkcja ma zostać przekazana jako parametr, musi być zgodna z tymi samymi regułami zgodności typu, co przypisanie. Oznacza to, że takie procedury lub funkcje muszą być skompilowane z dyrektywą far, nie mogą być funkcjami wbudowanymi, nie mogą być zagnieżdżone i nie mogą być opisane za pomocą atrybutów inline lub przerwań. 11. Typ łańcucha w Pascalu. Procedury i funkcje dla zmiennych typu łańcuchowego Sekwencja znaków o określonej długości nazywana jest ciągiem. Zmienne typu string są definiowane przez podanie w nawiasach kwadratowych nazwy zmiennej, słowa zastrzeżonego string oraz opcjonalnie, ale niekoniecznie, maksymalnego rozmiaru, tj. długości ciągu. Jeśli nie ustawisz maksymalnego rozmiaru ciągu, to domyślnie będzie to 255, czyli ciąg będzie składał się z 255 znaków. Do każdego elementu ciągu można się odnieść poprzez jego numer. Jednak łańcuchy są danymi wejściowymi i wyjściowymi jako całość, a nie element po elemencie, jak ma to miejsce w przypadku tablic. Liczba wprowadzanych znaków nie może przekraczać określonej w maksymalnym rozmiarze ciągu, więc jeśli taka nadwyżka wystąpi, to „dodatkowe” znaki zostaną zignorowane. Procedury i funkcje dla zmiennych typu łańcuchowego 1. Kopiowanie funkcji (S: ciąg; indeks, liczba: liczba całkowita): ciąg; Zwraca podciąg ciągu. S jest wyrażeniem typu String. Index i Count są wyrażeniami typu całkowitego. Funkcja zwraca ciąg zawierający znaki Count, zaczynając od pozycji Index. Jeśli indeks jest większy niż długość S, funkcja zwraca pusty ciąg. 2. Procedura Delete(var S: String; Index, Count: Integer); Usuwa podciąg znaków o długości Count z ciągu S, zaczynając od pozycji Index. S jest zmienną typu String. Index i Count są wyrażeniami typu całkowitego. Jeśli indeks jest większy niż długość S, żadne znaki nie są usuwane. 3. Procedura Insert(Źródło: Ciąg; var S: Ciąg; Indeks: Liczba całkowita); Łączy podciąg w ciąg, zaczynając od określonej pozycji. Źródło jest wyrażeniem typu String. S jest zmienną typu String o dowolnej długości. Indeks jest wyrażeniem typu integer. Wstaw wstawia Source do S, zaczynając od pozycji S. 4. Długość funkcji (S: ciąg): liczba całkowita; Zwraca liczbę znaków faktycznie użytych w ciągu S. Zauważ, że w przypadku używania ciągów zakończonych znakiem NULL liczba znaków niekoniecznie jest równa liczbie bajtów. 5. Function Pos(Substr: String; S: String): Liczba całkowita; Wyszukuje podciąg w ciągu. Pos szuka Substr wewnątrz S i zwraca wartość całkowitą, która jest indeksem pierwszego znaku Substr w S. Jeśli Substr nie zostanie znaleziony, Pos zwraca zero. 12. Nagrania Rekord to zbiór ograniczonej liczby logicznie powiązanych komponentów należących do różnych typów. Składniki rekordu nazywane są polami, z których każde jest identyfikowane za pomocą nazwy. Pole rekordu zawiera nazwę pola, po której następuje dwukropek wskazujący typ pola. Pola rekordów mogą być dowolnego typu dozwolonego w Pascalu, z wyjątkiem typu pliku. Opis rekordu w języku Pascal odbywa się za pomocą słowa serwisowego RECORD, po którym następuje opis składników rekordu. Opis wpisu kończy się słowem serwisowym END. Na przykład notatnik zawiera nazwiska, inicjały i numery telefonów, więc wygodnie jest przedstawić oddzielny wiersz w notatniku jako następujący wpis: wpisz wiersz = rekord FIO: Ciąg[20]; TEL: Ciąg[7]; puszki; var str: Wiersz; Opisy rekordów są również możliwe bez użycia nazwy typu, na przykład: var str: Nagraj FIO: Ciąg[20]; TEL: Ciąg[7]; puszki; Odwoływanie się do rekordu jako całości jest dozwolone tylko w instrukcjach przypisania, w których nazwy rekordów tego samego typu są używane po lewej i prawej stronie znaku przypisania. We wszystkich pozostałych przypadkach obsługiwane są oddzielne pola rekordów. Aby odwołać się do pojedynczego składnika rekordu, należy podać nazwę rekordu i oddzielone kropką nazwę żądanego pola. Taka nazwa nazywana jest nazwą złożoną. Składnik rekordu może być również rekordem, w którym to przypadku nazwa wyróżniająca będzie zawierać nie dwie, ale więcej nazw. Odwoływanie się do składników rekordu można uprościć za pomocą operatora with append. Umożliwia zastąpienie nazw złożonych, które charakteryzują każde pole, tylko nazwami pól i zdefiniowanie nazwy rekordu w operatorze dołączania. Czasami zawartość pojedynczego rekordu zależy od wartości jednego z jego pól. W języku Pascal dozwolony jest opis rekordu składający się z części wspólnych i wariantów. Część wariantową określa się za pomocą przypadku P konstrukcji, gdzie P jest nazwą pola ze wspólnej części rekordu. Możliwe wartości akceptowane przez to pole są wymienione w taki sam sposób, jak w oświadczeniu wariantowym. Jednak zamiast określać czynność do wykonania, jak to ma miejsce w instrukcji wariantu, pola wariantów są podane w nawiasach. Opis części wariantowej kończy się słowem serwisowym. Typ pola P można określić w nagłówku części wariantowej. Rekordy są inicjowane za pomocą wpisanych stałych. 13. Zestawy Pojęcie zbioru w języku Pascal opiera się na matematycznym pojęciu zbiorów: jest to ograniczony zbiór różnych elementów. Wyliczeniowy lub interwałowy typ danych służy do konstruowania konkretnego typu zestawu. Typ elementów tworzących zestaw nazywany jest typem bazowym. Typ wielokrotny jest opisywany za pomocą zestawu słów funkcyjnych, na przykład: typ M = zestaw B; gdzie M jest typem liczby mnogiej, B jest typem podstawowym. Przynależność zmiennych do typu liczby mnogiej można określić bezpośrednio w sekcji deklaracji zmiennej. Stałe typu zestawu są zapisywane jako ujęty w nawias ciąg elementów lub interwałów typu podstawowego, oddzielonych przecinkami. Operacje przypisania (:=), sumy (+), przecięcia (*) i odejmowania (-) dotyczą zmiennych i stałych określonego typu. Wynikiem tych operacji jest wartość typu mnogiego: 1) ['A','B'] + ['A','D'] da ['A','B','D']; 2) ['A'] * ['A','B','C'] da ['A']; 3) ['A','B','C'] - ['A','B'] da ['C'] Operacje dotyczą wielu wartości: tożsamość (=), brak tożsamości (<>), zawarty w (<=), zawiera (>=). Wynik tych operacji ma typ logiczny: 1) ['A','B'] = ['A','C'] da FAŁSZ; 2) ['A','B'] <> ['A','C'] da PRAWDA; 3) ['B'] <= ['B','C'] da TRUE; 4) ['C','D'] >= ['A'] da FAŁSZ. Oprócz tych operacji, do pracy z wartościami typu zbioru używany jest w operacji, który sprawdza, czy element typu bazowego po lewej stronie znaku operacji należy do zbioru po prawej stronie znaku operacji . Wynik tej operacji jest wartością logiczną. Wartości typu wielokrotnego nie mogą być elementami listy I/O. W każdej konkretnej implementacji kompilatora z języka Pascal liczba elementów typu bazowego, na którym budowany jest zestaw, jest ograniczona. 14. Pliki. Operacje na plikach Typ danych pliku definiuje uporządkowaną kolekcję komponentów tego samego typu. Podczas pracy z plikami wykonywane są operacje we / wy. Operacja wejściowa to transfer danych z urządzenia zewnętrznego do pamięci, operacja wyjściowa to transfer danych z pamięci do urządzenia zewnętrznego. Pliki tekstowe Do opisu takich plików służy typ Tekst: zmienna TF1, TF2: Tekst; Pliki składowe Komponent lub plik z typem to plik z zadeklarowanym typem jego komponentów. wpisz M = plik T; gdzie M to nazwa typu pliku; T - typ komponentu. Operacje wykonywane są za pomocą procedur. Write(f, X1,X2,...XK) Niewpisane pliki Niewpisane pliki umożliwiają zapisywanie dowolnych sekcji pamięci komputera na dysk i odczytywanie ich. var f: plik; 1. Procedura Assign(var F; FileName: String); Odwzorowuje nazwę pliku na zmienną. 2. Procedura Zamknij (var F); Przerywa połączenie między zmienną pliku a plikiem na dysku zewnętrznym i zamyka plik. 3.Funkcja Eof(var F): Boolean; {Pliki wpisane lub niewpisane} Funkcja Eof[(var F: tekst)]: Boolean; {pliki tekstowe} Sprawdza koniec pliku. 4. Procedura Wymaż (varF); Usuwa zewnętrzny plik skojarzony z F. 5. Function FileSize(var F): Liczba całkowita; Zwraca rozmiar w bajtach pliku F. 6.Funkcja FilePos(varF): LongInt; Zwraca bieżącą pozycję w pliku. 7. Procedura Reset(var F [: File; RecSize: Word]); Otwiera istniejący plik. 8. Procedura Rewrite(var F: File [; Recsize: Word]); Tworzy i otwiera nowy plik. 9. Procedura Seek(var F; N: LongInt); Przenosi bieżącą pozycję pliku do określonego komponentu. 10. Procedura Append(var F: Text); Dodatek. 11.Funkcja Eoln[(var F: tekst)]: Boolean; Sprawdza koniec ciągu. 12. Procedure Read(F, V1 [, V2..., Vn]); {Pliki wpisane i niewpisane} Procedure Read([var F: Text;] V1 [, V2..., Vn]); {pliki tekstowe} Wczytuje komponent pliku do zmiennej. 13. Procedura Readln([var F: Tekst;] V1 [, V2..., Vn]); Czyta wiersz znaków w pliku, w tym znacznik końca wiersza, i przechodzi na początek następnego. 14. Funkcja SeekEof[(var F: tekst)]: Boolean; Zwraca znak końca pliku. Używany tylko do otwartych plików tekstowych. 15. Procedure Writeln([var F: Text;] [P1, P2..., Pn]); {pliki tekstowe} Wykonuje operację zapisu, a następnie umieszcza w pliku znacznik końca wiersza. 15. Moduły. Rodzaje modułów Jednostka (UNIT) w Pascalu to specjalnie zaprojektowana biblioteka podprogramów. Moduł w przeciwieństwie do programu nie może być uruchamiany samodzielnie, może jedynie uczestniczyć w budowaniu programów i innych modułów. Moduł w Pascalu to oddzielnie przechowywana i niezależnie skompilowana jednostka programu. Wszystkie elementy programowe modułu można podzielić na dwie części: 1) elementy programu przeznaczone do wykorzystania przez inne programy lub moduły, takie elementy nazywane są widocznymi na zewnątrz modułu; 2) elementy oprogramowania, które są niezbędne tylko do działania samego modułu, nazywane są niewidocznymi (lub ukrytymi). jednostka <nazwa modułu>; {tytuł modułu} Interfejs {opis widocznych elementów programowych modułu} realizacja {opis ukrytych elementów programistycznych modułu} rozpocząć {instrukcje inicjalizacji elementu modułu} koniec. Aby odwołać się do zmiennej zadeklarowanej w module, należy użyć nazwy złożonej składającej się z nazwy modułu i nazwy zmiennej oddzielonych kropką. Rekursywne używanie modułów jest zabronione. Wymieńmy typy modułów. 1. Moduł SYSTEM. Moduł SYSTEM implementuje procedury obsługi niższego poziomu dla wszystkich wbudowanych funkcji, takich jak I/O, manipulacja łańcuchami, operacje zmiennoprzecinkowe i dynamiczna alokacja pamięci. 2. Moduł DOS. Moduł DOS implementuje liczne procedury i funkcje Pascala, które są odpowiednikami najczęściej używanych wywołań DOS, takich jak GetTime, SetTime, DiskSize i tak dalej. 3. Moduł CRT. Moduł CRT implementuje szereg potężnych programów, które zapewniają pełną kontrolę nad funkcjami komputera, takimi jak sterowanie trybem ekranu, rozszerzone kody klawiatury, kolory, okna i dźwięki. 4. Moduł WYKRES. Korzystając z procedur i funkcji zawartych w tym module, możesz tworzyć różne grafiki na ekranie. 5. Moduł NAKŁADKI. Moduł OVERLAY pozwala zmniejszyć wymagania dotyczące pamięci programu DOS w trybie rzeczywistym. 16. Referencyjny typ danych. pamięć dynamiczna. zmienne dynamiczne. Praca z pamięcią dynamiczną Zmienna statyczna (statycznie alokowana) to zmienna jawnie zadeklarowana w programie, do której odwołuje się nazwa. Miejsce w pamięci na umieszczenie zmiennych statycznych jest określane podczas kompilacji programu. W przeciwieństwie do takich zmiennych statycznych, programy Pascala mogą tworzyć zmienne dynamiczne. Główną właściwością zmiennych dynamicznych jest to, że są one tworzone i przydzielana jest im pamięć podczas wykonywania programu. Zmienne dynamiczne są umieszczane w dynamicznym obszarze pamięci (obszar sterty). Zmienna dynamiczna nie jest wyraźnie określona w deklaracjach zmiennych i nie można się do niej odwoływać za pomocą nazwy. Dostęp do takich zmiennych uzyskuje się za pomocą wskaźników i referencji. Typ referencyjny (wskaźnik) definiuje zestaw wartości wskazujących na zmienne dynamiczne określonego typu, zwanego typem bazowym. Zmienna typu referencyjnego zawiera adres zmiennej dynamicznej w pamięci. Jeśli typ podstawowy jest niezadeklarowanym identyfikatorem, musi być zadeklarowany w tej samej części deklaracji typu, co typ wskaźnika. Zastrzeżone słowo nil oznacza stałą z wartością wskaźnika, która na nic nie wskazuje. Podajmy przykład opisu zmiennych dynamicznych. zmienna p1, p2: ^real; p3, p4: ^ liczba całkowita; ... Procedury i funkcje pamięci dynamicznej 1. Procedura Nowa{var p: Wskaźnik). Przydziela miejsce w obszarze pamięci dynamicznej, aby pomieścić zmienną dynamiczną p" i przypisuje jej adres do wskaźnika p. 2. Procedura Dispose(var p: Wskaźnik). Zwalnia pamięć przydzieloną do dynamicznej alokacji zmiennych przez procedurę New, a wartość wskaźnika p staje się niezdefiniowana. 3. Procedura GetMem(var p: Wskaźnik; rozmiar: Word). Alokuje sekcję pamięci w obszarze sterty, przypisuje adres jej początku do wskaźnika p, rozmiar sekcji w bajtach jest określony przez parametr size. 4. Procedura FreeMem(varp: Wskaźnik; rozmiar: Word). Zwalnia obszar pamięci, którego początkowy adres jest określony przez wskaźnik p, a rozmiar jest określony przez parametr size. Wartość wskaźnika p staje się niezdefiniowana. 5. Procedura Mark{var p: Pointer) zapisuje do wskaźnika p adres początku sekcji wolnej pamięci dynamicznej w momencie jej wywołania. 6. Procedura Release(var p: Pointer) zwalnia część pamięci dynamicznej, poczynając od adresu zapisanego do wskaźnika p przez procedurę Mark, czyli czyści pamięć dynamiczną zajętą po wywołaniu procedury Mark. 7. Funkcja MaxAvail: Longint zwraca długość w bajtach najdłuższej wolnej sekcji pamięci dynamicznej. 8. Funkcja MemAvail: Longint zwraca całkowitą ilość wolnej pamięci dynamicznej w bajtach. 9. Funkcja pomocnicza SizeOf(X):Word zwraca rozmiar w bajtach zajmowany przez X, gdzie X może być nazwą zmiennej dowolnego typu lub nazwą typu. 17. Abstrakcyjne struktury danych Strukturalne typy danych, takie jak tablice, zestawy i rekordy, są strukturami statycznymi, ponieważ ich rozmiary nie zmieniają się podczas całego wykonywania programu. Często wymagane jest, aby struktury danych zmieniały swoje rozmiary w trakcie rozwiązywania problemu. Takie struktury danych nazywane są dynamicznymi. Należą do nich stosy, kolejki, listy, drzewa itp. Opis struktur dynamicznych za pomocą tablic, rekordów i plików prowadzi do marnotrawstwa pamięci komputera i wydłuża czas rozwiązywania problemów. Każdy składnik dowolnej struktury dynamicznej jest rekordem zawierającym co najmniej dwa pola: jedno pole typu „wskaźnik”, a drugie – do rozmieszczenia danych. Ogólnie rekord może zawierać nie jeden, ale kilka wskaźników i kilka pól danych. Pole danych może być zmienną, tablicą, zestawem lub rekordem. Jeżeli część wskazująca zawiera adres jednego elementu listy, to lista nazywana jest jednokierunkową (lub pojedynczo powiązaną). Jeśli zawiera dwa składniki, jest podwójnie połączony. Na listach możesz wykonywać różne operacje, na przykład: 1) dodanie elementu do listy; 2) usunięcie elementu z listy z danym kluczem; 3) wyszukaj element o podanej wartości pola kluczowego; 4) sortowanie elementów wykazu; 5) podział listy na dwie lub więcej list; 6) połączenie dwóch lub więcej list w jedną; 7) inne operacje. Jednak z reguły nie ma potrzeby wykonywania wszystkich operacji w rozwiązywaniu różnych problemów. Dlatego w zależności od podstawowych operacji, które należy zastosować, istnieją różne rodzaje list. Najpopularniejsze z nich to stos i kolejka. 18. Stosy Stos to dynamiczna struktura danych, do której dodawany jest składnik, a usuwany z jednego końca, zwanego wierzchołkiem stosu. Stos działa na zasadzie LIFO (Last-In, First-Out) - „ostatnie weszło, pierwsze wyszło”. Zazwyczaj na stosach wykonywane są trzy operacje: 1) początkowa formacja stosu (zapis pierwszego składnika); 2) dodanie składnika do stosu; 3) wybór komponentu (skreślenie). Aby utworzyć stos i z nim pracować, musisz mieć dwie zmienne typu „wskaźnik”, z których pierwsza określa wierzchołek stosu, a druga jest pomocnicza. Przykład. Napisz program, który tworzy stos, dodaje do niego dowolną liczbę składników, a następnie odczytuje wszystkie składniki. Program STOS; używa Crt; rodzaj Alfa = Ciąg[10]; PZm = ^Zm; Comp = rekord SD: Alfa; pNastępny: PComp puszki; było pTop: PCComp; sc: Alfa; Utwórz ProcedureStack(var pTop: PComp; var sC: Alfa); rozpocząć Nowy(pTop); pGóra^.pDalej:= NIL; pGóra^.sD:= sC; puszki; Dodaj ProcedureComp(var pTop: PComp; var sC: Alfa); zmienna pAux: PComp; rozpocząć NOWOŚĆ(pAux); pAux^.pDalej:= pGóra; pTop:=pAux; pGóra^.sD:= sC; puszki; Procedura DelComp(var pTop: PComp; var sC: ALFA); rozpocząć sC:= pGóra^.sD; pGór:= pGór^.pNastępny; puszki; rozpocząć Clrscr; writeln( WPISZ ŁAŃCUCH ); readln(sc); CreateStack(pTop, sc); powtarzać writeln( WPISZ ŁAŃCUCH ); readln(sc); AddComp(pTop, sc); do sC = 'KONIEC'; 19. Kolejki Kolejka to dynamiczna struktura danych, w której składnik jest dodawany na jednym końcu i pobierany na drugim końcu. Kolejka działa na zasadzie FIFO (First-In, First-Out) – „pierwszy weszło, ten lepszy”. Przykład. Napisz program, który tworzy kolejkę, dodaje do niej dowolną liczbę komponentów, a następnie odczytuje wszystkie komponenty. Program KOLEJKA; używa Crt; rodzaj Alfa = Ciąg[10]; PZm = ^Zm; Comp = rekord SD: Alfa; pNastępny: PCComp; puszki; było pPoczątek, koniec: PComp; sc: Alfa; Utwórz ProcedureQueue(var pBegin,pEnd: PComp; var sc: Alfa); rozpocząć Nowy(pRozpocznij); pPoczątek^.pNastępny:= NIL; pPoczątek^.sD:= sC; pEnd:= pPoczątek; puszki; Procedura AddQueue(var pEnd: PComp; var sc: alfa); zmienna pAux: PComp; rozpocząć Nowy(pAux); pAux^.pDalej:= NIL; pKoniec^.pNastępny:= pAux; pEnd:= pAux; koniec^.sD:= sC; puszki; Procedura DelQueue(var pPoczątek: PComp; var sc: alfa); rozpocząć sC:=pRozpocznij^.sD; pPoczątek:= pPoczątek^.pNastępny; puszki; rozpocząć Clrscr; writeln( WPISZ ŁAŃCUCH ); readln(sc); CreateQueue(pPoczątek, koniec, sc); powtarzać writeln( WPISZ ŁAŃCUCH ); readln(sc); AddQueue(pEnd, sc); do sC = 'KONIEC'; 20. Struktury danych drzewa Drzewopodobna struktura danych to skończony zbiór elementów-węzłów, pomiędzy którymi istnieją relacje – połączenie między źródłem a generowanym. Jeśli użyjemy definicji rekurencyjnej zaproponowanej przez N. Wirtha, to drzewiasta struktura danych o typie bazowym t jest albo strukturą pustą, albo węzłem typu t, z którym jest skończony zbiór struktur drzewiastych o typie bazowym t, zwanych poddrzewami. powiązany. Następnie podajemy definicje używane podczas pracy ze strukturami drzewiastymi. Если узел y находится непосредственно под узлом х, то узел y называется непосредственным потомком узла х, а x - непосредственным предком узла у, т. е., если узел хнаходится на i-ом уровне, то соответственно узел y находится на (i + 1) - ом уровне. Maksymalny poziom węzła drzewa nazywa się wysokością lub głębokością drzewa. Przodek nie posiada tylko jednego węzła drzewa – jego korzenia. Węzły drzewa, które nie mają dzieci, nazywane są węzłami liści (lub liśćmi drzewa). Wszystkie inne węzły nazywane są węzłami wewnętrznymi. Liczba bezpośrednich dzieci węzła określa stopień tego węzła, a maksymalny możliwy stopień węzła w danym drzewie określa stopień drzewa. Przodków i potomków nie można wymieniać, to znaczy, że połączenie między oryginałem a wygenerowanym działa tylko w jednym kierunku. Jeśli przejdziesz od korzenia drzewa do jakiegoś konkretnego węzła, wtedy liczba gałęzi drzewa, przez które przejdziesz w tym przypadku, nazywana jest długością ścieżki dla tego węzła. Jeśli wszystkie gałęzie (węzły) drzewa są uporządkowane, mówi się, że drzewo jest uporządkowane. Drzewa binarne to szczególny przypadek struktur drzewiastych. Są to drzewa, w których każde dziecko ma najwyżej dwoje dzieci, zwane poddrzewem lewym i prawym. Zatem drzewo binarne jest strukturą drzewa, której stopień wynosi dwa. Kolejność drzewa binarnego jest określona przez następującą regułę: każdy węzeł ma swoje własne pole klucza, a dla każdego węzła wartość klucza jest większa niż wszystkich kluczy w jego lewym poddrzewie i mniejsza niż wszystkich kluczy w jego prawym poddrzewie. Drzewo, którego stopień jest większy niż dwa, nazywamy silnie rozgałęzionym. 21. Operacje na drzewach Dalej rozważymy wszystkie operacje w odniesieniu do drzew binarnych. I. Budowanie drzewa. Przedstawiamy algorytm budowy uporządkowanego drzewa. 1. Jeśli drzewo jest puste, dane są przesyłane do korzenia drzewa. Jeśli drzewo nie jest puste, to jedna z jego gałęzi jest opada w taki sposób, że kolejność drzewa nie jest naruszona. W rezultacie nowy węzeł staje się kolejnym liściem drzewa. 2. Aby dodać węzeł do już istniejącego drzewa, możesz użyć powyższego algorytmu. 3. Podczas usuwania węzła z drzewa należy zachować ostrożność. Jeśli usuwany węzeł jest liściem lub ma tylko jedno dziecko, operacja jest prosta. Jeśli usuwany węzeł ma dwóch potomków, to wśród jego potomków konieczne będzie znalezienie węzła, który można umieścić na jego miejscu. Jest to konieczne ze względu na wymóg uporządkowania drzewka. Możesz to zrobić: zamień węzeł do usunięcia na węzeł z największą wartością klucza w lewym poddrzewie lub na węzeł z najmniejszą wartością klucza w prawym poddrzewie, a następnie usuń żądany węzeł jako liść. II. Wyszukaj węzeł z podaną wartością pola klucza. Podczas wykonywania tej operacji konieczne jest przejście drzewa. Należy wziąć pod uwagę różne formy notacji drzewa: przedrostek, wrostek i przyrostek. Powstaje pytanie: jak reprezentować węzły drzewa, aby najwygodniej z nimi pracować? Możliwe jest przedstawienie drzewa za pomocą tablicy, gdzie każdy węzeł jest opisany wartością typu złożonego, która posiada pole informacyjne typu znakowego i dwa pola typu referencyjnego. Ale nie jest to zbyt wygodne, ponieważ drzewa mają dużą liczbę węzłów, które nie są z góry określone. Dlatego najlepiej jest używać zmiennych dynamicznych podczas opisywania drzewa. Wtedy każdy węzeł jest reprezentowany przez wartość tego samego typu, która zawiera opis danej liczby pól informacyjnych, a liczba odpowiadających im pól musi być równa stopniowi drzewa. Logiczne jest zdefiniowanie braku potomków przez odniesienie do zera. Wtedy w Pascalu opis drzewa binarnego może wyglądać tak: TYP TreeLink = ^Drzewo; drzewo = rekord; Inf: <typ danych>; Lewo, Prawo: TreeLink; Koniec 22. Przykłady realizacji operacji 1. Skonstruuj drzewo składające się z XNUMX węzłów o minimalnej wysokości lub drzewo idealnie zrównoważone (liczba węzłów lewego i prawego poddrzewa takiego drzewa nie powinna różnić się o więcej niż jeden). Rekurencyjny algorytm konstrukcji: 1) pierwszy węzeł jest traktowany jako korzeń drzewa; 2) lewe poddrzewo nl węzłów jest zbudowane w ten sam sposób; 3) w ten sam sposób zbudowane jest prawe poddrzewo węzłów nr; nr = n - nl - 1 Jako pole informacyjne przyjmiemy numery węzłów wprowadzone z klawiatury. Funkcja rekurencyjna implementująca tę konstrukcję będzie wyglądać tak: Drzewo funkcji (n: bajt): TreeLink; Wersja: TreeLink; nl,nr,x: bajt; Rozpocząć Jeśli n = 0 to Drzewo:= nil Więcej Rozpocząć nl:= n dział 2; nr = n - nl - 1; writeln('Podaj numer wierzchołka ); odczytln(x); traszka); t^.inf:= x; t^.lewo:= Drzewo(nl); t^.prawo:= Drzewo(nr); Drzewo:=t; End; {Drzewo} Koniec 2. W drzewie uporządkowanym binarnie znajdź węzeł z podaną wartością pola klucza. Jeśli nie ma takiego elementu w drzewie, dodaj go do drzewa. Procedura wyszukiwania(x: Byte; var t: TreeLink); Rozpocząć Jeśli t = zero, to Rozpocząć Traszka); t^inf := x; t^.lewo:= zero; t^.prawo:= zero; Koniec W przeciwnym razie, jeśli x < t^.inf to Szukaj(x, t^.lewo) W przeciwnym razie, jeśli x > t^.inf to Szukaj(x, t^.prawo) Więcej Rozpocząć {przetworzyć znaleziony element} ... End; Koniec 23. Pojęcie grafu. Sposoby reprezentowania wykresu Graf to para G = (V,E), gdzie V to zbiór obiektów o dowolnym charakterze, zwanych wierzchołkami, a E to rodzina par ei = (vil, vi2), vijOV, zwanych krawędziami. W ogólnym przypadku zbiór V i (lub) rodzina E może zawierać nieskończoną liczbę elementów, ale rozważymy tylko grafy skończone, tj. grafy, dla których zarówno V, jak i E są skończone. Jeżeli kolejność elementów zawartych w ei ma znaczenie, to graf nazywamy skierowanym, w skrócie - digrafem, inaczej - nieskierowanym. Krawędzie dwuznaku nazywane są łukami. Jeśli e = , to wierzchołki v i u nazywane są końcami krawędzi. Tutaj mówimy, że krawędź e przylega (incydent) do każdego z wierzchołków v i u. Wierzchołki v oraz i są również nazywane sąsiednimi (incydentami). W ogólnym przypadku krawędzie postaci e = ; takie krawędzie nazywane są pętlami. Stopień wierzchołka grafu to liczba krawędzi przypadających na dany wierzchołek, z pętlami liczonymi dwukrotnie. Waga węzła to liczba (rzeczywista, całkowita lub wymierna) przypisana do danego węzła (interpretowana jako koszt, przepustowość itp.). Путем в графе (или маршрутом в орграфе) называется чередующаяся последовательность вершин и ребер (или дуг - в орграфе) вида v0, (v0,v1), v1,..., (vn -1,vn), vn. Число n называется длиной пути. Путь без повторяющихся ребер называется цепью, без повторяющихся вершин - простой цепью. Замкнутый путь без повторяющихся ребер называется циклом (или kontur w dwugrafie); bez powtarzania wierzchołków (z wyjątkiem pierwszego i ostatniego) - prosty cykl. Graf jest połączony, jeśli istnieje ścieżka między dowolnymi dwoma jego wierzchołkami, aw przeciwnym razie jest rozłączony. Istnieje wiele sposobów reprezentowania wykresów. 1. Macierz incydentów. Jest to macierz prostokątna n x m, gdzie n to liczba wierzchołków, a m to liczba krawędzi. 2. Macierz sąsiedztwa. Jest to macierz kwadratowa o wymiarach n × n, gdzie n jest liczbą wierzchołków. 3. Lista przyległości (incydentów). Reprezentuje strukturę danych, która dla każdego wierzchołka grafu przechowywana jest lista sąsiadujących z nim wierzchołków. Lista jest tablicą wskaźników, której i-ty element zawiera wskaźnik do listy wierzchołków sąsiadujących z i-tym wierzchołkiem. 4. Lista list. Jest to struktura danych podobna do drzewa, w której jedna gałąź zawiera listy sąsiadujących ze sobą wierzchołków. 24. Różne reprezentacje wykresów Aby zaimplementować wykres jako listę zdarzeń, możesz użyć następującego typu: Lista typów = ^S; S=rekord; inf: Bajt; następny: Lista; puszki; Wtedy wykres definiujemy następująco: Vargr: tablica[1..n] listy; Przejdźmy teraz do procedury przechodzenia przez wykres. Jest to algorytm pomocniczy, który pozwala przeglądać wszystkie wierzchołki wykresu, analizować wszystkie pola informacyjne. Jeśli rozważymy przechodzenie grafu dogłębnie, to istnieją dwa rodzaje algorytmów: rekurencyjne i nierekurencyjne. W Pascalu procedura przechodzenia w głąb wyglądałaby tak: Procedura Obhod(gr: wykres; k: bajt); Warg: Wykres; l:Lista; Rozpocząć lis[k]:= fałsz; g:=gr; Podczas gdy g^.inf <> k do g:= g^.następny; l:= g^.smeg; Podczas gdy l <> nic nie zaczynam Jeśli nov[l^.inf] to Obhod(gr, l^.inf); l:= l^.następny; End; End; Reprezentowanie wykresu jako listy list Wykres można zdefiniować za pomocą listy list w następujący sposób: TypeList = ^Tlista; tlist=rekord inf: Bajt; następny: Lista; puszki; Wykres = ^TGpaph; TGpaph = rekord inf: Bajt; smeg: Lista; dalej: wykres; puszki; Przemierzając wykres wszerz, wybieramy dowolny wierzchołek i jednocześnie przeglądamy wszystkie sąsiadujące z nim wierzchołki. Oto procedura przechodzenia po grafie na szerokość w pseudokodzie: Procedura Obhod2(v); Rozpocząć kolejka = O; kolejka <= v; nov[v] = Fałsz; Podczas kolejki <> O do Rozpocząć p <= kolejka; Dla u w spisok(p) do Jeśli nowy[u] to Rozpocząć lis[u]:= Fałsz; kolejka <= u; End; End; End; 25. Typ obiektu w Pascalu. Pojęcie przedmiotu, jego opis i zastosowanie Język programowania obiektowego charakteryzuje się trzema głównymi właściwościami: 1) hermetyzacja. Połączenie rekordów z procedurami i funkcjami manipulującymi polami tych rekordów tworzy nowy typ danych - obiekt; 2) dziedziczenie. Definicja obiektu i jego dalsze wykorzystanie do budowy hierarchii obiektów podrzędnych z możliwością dostępu do kodu i danych wszystkich obiektów nadrzędnych dla każdego obiektu podrzędnego związanego z hierarchią; 3) polimorfizm. Nadanie akcji pojedynczej nazwy, która jest następnie udostępniana w górę iw dół hierarchii obiektów, przy czym każdy obiekt w hierarchii wykonuje tę akcję w sposób, który jej odpowiada. Mówiąc o obiekcie, wprowadzamy nowy typ danych - obiekt. Typ obiektu to struktura składająca się ze stałej liczby komponentów. Każdy składnik to albo pole zawierające dane o ściśle określonym typie, albo metoda wykonująca operacje na obiekcie. Typ obiektu może dziedziczyć komponenty innego typu obiektu. Jeśli typ T2 dziedziczy po typie T1, to typ T2 jest dzieckiem typu G, a sam typ G jest rodzicem typu G2. Poniższy kod źródłowy zawiera przykład deklaracji typu obiektu. rodzaj punkt = obiekt X, Y: liczba całkowita; puszki; Prost = obiekt A, B: TPunkt; procedura Init(XA, YA, XB, YB: liczba całkowita); procedura Copy(var R: TRectangle); procedura Przenieś(DX, DY: liczba całkowita); procedura Grow(DX, DY: liczba całkowita); procedura Intersect(var R: TRectangle); procedura Union(var R: TRectangle); funkcja Zawiera(P: Punkt): Boolean; puszki; W przeciwieństwie do innych typów, typy obiektów można deklarować tylko w sekcji deklaracji typu na zewnętrznym poziomie zakresu programu lub modułu. W związku z tym typy obiektów nie mogą być deklarowane w sekcji deklaracji zmiennej lub wewnątrz procedury, funkcji lub bloku metody. Typ komponentu typu pliku nie może mieć typu obiektowego ani żadnego typu struktury zawierającego komponenty typu obiektowego. 26. Dziedziczenie Dziedziczenie to proces generowania nowych typów podrzędnych z istniejących typów nadrzędnych, podczas gdy dziecko otrzymuje (dziedziczy) od rodzica wszystkie jego pola i metody. Typ potomny w tym przypadku nazywany jest typem spadkobiercy lub typu podrzędnego. A typ, z którego dziedziczy typ potomny, nazywa się typem rodzica. Dziedziczone pola i metody mogą być używane bez zmian lub przedefiniowane (zmodyfikowane). N. Wirth w swoim języku dążył do maksymalnej prostoty, więc nie komplikował jej wprowadzając relację dziedziczenia. Dlatego typy w Pascalu nie mogą dziedziczyć. Jednak Turbo Pascal 7.0 rozszerza ten język o obsługę dziedziczenia. Jednym z takich rozszerzeń jest nowa kategoria struktury danych związana z rekordami, ale o wiele potężniejsza. Typy danych w tej nowej kategorii są definiowane przy użyciu nowego zastrzeżonego słowa Object. Składnia jest bardzo podobna do składni definiowania rekordów: Rodzaj Nieruchomości <nazwa typu> = obiekt [(<nazwa typu nadrzędnego>)] ([<zakres>] <opis pól i metod>)+ puszki; Znak „+” po konstrukcji składni w nawiasach oznacza, że ta konstrukcja musi wystąpić w tym opisie raz lub więcej razy. Zakres to jedno z następujących słów kluczowych: ▪ Private; ▪ Protected; ▪ Public. Zakres określa, do których części programu będą dostępne komponenty, których opisy występują po słowie kluczowym określającym ten zakres. Aby uzyskać więcej informacji na temat zakresów komponentów, zobacz pytanie #28. Dziedziczenie to potężne narzędzie używane w tworzeniu programów. Pozwala zaimplementować w praktyce obiektową dekompozycję problemu, używając języka do wyrażania relacji między obiektami typów tworzących hierarchię, a także promuje ponowne wykorzystanie kodu programu. 27. Tworzenie instancji obiektów Instancja obiektu jest tworzona przez zadeklarowanie zmiennej lub stałej typu obiektu lub zastosowanie standardowej procedury New do zmiennej typu „wskaźnik do typu obiektu”. Wynikowy obiekt jest nazywany instancją typu obiektu. Jeśli typ obiektu zawiera metody wirtualne, wystąpienia tego typu obiektu muszą zostać zainicjowane przez wywołanie konstruktora przed wywołaniem dowolnej metody wirtualnej. Przypisanie wystąpienia typu obiektu nie oznacza zainicjowania wystąpienia. Obiekt jest inicjowany przez kod wygenerowany przez kompilator, który jest uruchamiany między wywołaniem konstruktora a punktem, w którym wykonanie faktycznie osiąga pierwszą instrukcję w bloku kodu konstruktora. Jeśli instancja obiektu nie jest zainicjowana i włączone jest sprawdzanie zakresu (przez dyrektywę {$R+}), to pierwsze wywołanie metody wirtualnej instancji obiektu daje błąd wykonania. Jeśli sprawdzanie zakresu jest wyłączone przez dyrektywę {$R-}), to pierwsze wywołanie metody wirtualnej niezainicjowanego obiektu może prowadzić do nieprzewidywalnego zachowania. Obowiązkowa reguła inicjowania dotyczy również wystąpień, które są składnikami typów struktur. Na przykład: było Komentarz: tablica [1..5] TStrField; I: liczba całkowita rozpocząć dla I:= 1 do 5 do Komentarz [I].Init (1, I + 10, 40, 'imię'); . . . dla I:= 1 do 5 wykonaj Komentarz [I].Gotowe; puszki; W przypadku wystąpień dynamicznych inicjowanie zwykle dotyczy umieszczania, a czyszczenie dotyczy usuwania, co jest osiągane za pomocą rozszerzonej składni standardowych procedur New i Dispose. Na przykład: było SP: strFieldPtr; rozpocząć New(SP, Init(1, 1, 25, 'imię'); SP^.Put('Władimir'); SP^.Wyświetlacz; . . . Utylizacja (SP, Gotowe); koniec. Wskaźnik do typu obiektu jest przypisaniem zgodnym ze wskaźnikiem do dowolnego typu obiektu nadrzędnego, więc w czasie wykonywania wskaźnik do typu obiektu może wskazywać na wystąpienie tego typu lub na wystąpienie dowolnego typu podrzędnego. 28. Komponenty i zakres Zakres identyfikatora ziarna wykracza poza typ obiektu. Co więcej, zakres identyfikatora bean rozciąga się na bloki procedur, funkcji, konstruktorów i destruktorów, które implementują metody typu obiektu i jego potomków. Na podstawie tych rozważań identyfikator komponentu musi być unikalny w obrębie typu obiektu i we wszystkich jego potomkach, a także we wszystkich jego metodach. W deklaracji typu obiektu nagłówek metody może określać parametry opisywanego typu obiektu, nawet jeśli deklaracja nie jest jeszcze kompletna. Rozważmy następujący schemat deklaracji typu, która zawiera składniki wszystkich prawidłowych zakresów: Rodzaj Nieruchomości <nazwa typu> = obiekt [(<nazwa typu nadrzędnego>)] Sprawy Prywatne <prywatne opisy pól i metod> Chroniony <zabezpieczone opisy pól i metod> Publiczne <publiczne opisy pól i metod> puszki; Pola i metody opisane w sekcji Prywatne mogą być używane tylko w module zawierającym ich deklaracje i nigdzie indziej. Chronione pola i metody, czyli te opisane w sekcji Chronione, są widoczne dla modułu, w którym zdefiniowany jest typ, oraz dla potomków tego typu. Pola i metody z sekcji Public nie mają ograniczeń w ich użyciu i mogą być używane w dowolnym miejscu programu, który ma dostęp do tego typu obiektu. Zakres identyfikatora komponentu opisanego w prywatnej części deklaracji typu jest ograniczony do modułu (programu), który zawiera deklarację typu obiektu. Innymi słowy, prywatne ziarna identyfikatorów działają jak zwykłe publiczne identyfikatory w module, który zawiera deklarację typu obiektu, a poza modułem wszelkie prywatne ziarna i identyfikatory są nieznane i niedostępne. Umieszczając powiązane typy obiektów w tym samym module, możesz sprawić, by te obiekty miały dostęp do swoich prywatnych komponentów, a te prywatne komponenty będą nieznane innym modułom. 29. Metody Deklaracja metody wewnątrz typu obiektu odpowiada deklaracji metody do przodu (forward). Tak więc gdzieś po deklaracji typu obiektu, ale w tym samym zakresie co deklaracja typu obiektu, metoda musi zostać zaimplementowana poprzez zdefiniowanie jej deklaracji. W przypadku metod proceduralnych i funkcjonalnych deklaracja definiująca przyjmuje postać normalnej procedury lub deklaracji funkcji, z tym wyjątkiem, że w tym przypadku identyfikator procedury lub funkcji jest traktowany jako identyfikator metody. Definiujący opis metody zawsze zawiera niejawny parametr o identyfikatorze Self, odpowiadający parametrowi zmiennej formalnej, która ma typ obiektowy. W bloku metody Self reprezentuje wystąpienie, którego składnik metody został określony w celu wywołania metody. W ten sposób wszelkie zmiany wartości pól Self są odzwierciedlane w instancji. Metody wirtualne Metody są domyślnie statyczne, ale z wyjątkiem konstruktorów mogą być wirtualne (poprzez dołączenie dyrektywy virtual w deklaracji metody). Kompilator rozwiązuje odwołania do wywołań metod statycznych podczas procesu kompilacji, podczas gdy wywołania metod wirtualnych są rozwiązywane w czasie wykonywania. Nazywa się to czasem późnym wiązaniem. Zastąpienie metody statycznej jest niezależne od zmiany nagłówka metody. W przeciwieństwie do tego, przesłonięcie metody wirtualnej musi zachować kolejność, typy i nazwy parametrów oraz typy wyników funkcji, jeśli takie istnieją. Ponadto redefinicja musi ponownie obejmować dyrektywę wirtualną. Metody dynamiczne Borland Pascal obsługuje dodatkowe metody późnego wiązania zwane metodami dynamicznymi. Metody dynamiczne różnią się od metod wirtualnych tylko sposobem, w jaki są wysyłane w czasie wykonywania. Pod wszystkimi innymi względami metody dynamiczne są uważane za równoważne metodom wirtualnym. Deklaracja metody dynamicznej jest równoważna deklaracji metody wirtualnej, ale deklaracja metody dynamicznej musi zawierać indeks metody dynamicznej, który jest określony bezpośrednio po słowie kluczowym virtual. Indeks metody dynamicznej musi być stałą całkowitą z zakresu od 1 do 656535 i musi być unikalny wśród indeksów innych metod dynamicznych zawartych w typie obiektu lub jego przodkach. Na przykład: procedura FileOpen(var Msg: TMessage); wirtualny 100; Zastąpienie metody dynamicznej musi być zgodne z kolejnością, typami i nazwami parametrów oraz dokładnie odpowiadać typowi wyniku funkcji metody nadrzędnej. Zastąpienie musi również zawierać dyrektywę wirtualną, po której następuje ten sam indeks metody dynamicznej, który został określony w typie obiektu przodka. 30. Konstruktory i destruktory Konstruktory i destruktory to wyspecjalizowane formy metod. Stosowane w połączeniu z rozszerzoną składnią standardowych procedur New i Dispose, konstruktory i destruktory mają możliwość umieszczania i usuwania obiektów dynamicznych. Dodatkowo konstruktorzy mają możliwość wykonania wymaganej inicjalizacji obiektów zawierających metody wirtualne. Podobnie jak wszystkie metody, konstruktory i destruktory mogą być dziedziczone, a obiekty mogą zawierać dowolną liczbę konstruktorów i destruktorów. Konstruktory służą do inicjowania nowo tworzonych obiektów. Zazwyczaj inicjalizacja opiera się na wartościach przekazanych do konstruktora jako parametry. Konstruktor nie może być wirtualny, ponieważ mechanizm wysyłania metody wirtualnej zależy od konstruktora, który jako pierwszy zainicjował obiekt. Oto kilka przykładów konstruktorów: konstruktor Field.Copy(var F: Field); rozpocząć Ja:=F; puszki; Główną akcją konstruktora typu pochodnego (dziecko) jest prawie zawsze wywołanie odpowiedniego konstruktora jego bezpośredniego rodzica w celu zainicjowania dziedziczonych pól obiektu. Po wykonaniu tej procedury konstruktor inicjuje pola obiektu, które należą tylko do typu pochodnego. Destruktory są przeciwieństwem konstruktorów i służą do czyszczenia obiektów po ich użyciu. Normalnie czyszczenie polega na usunięciu wszystkich pól wskaźnika w obiekcie. Operacja Destruktor może być wirtualny i często jest. Destruktor rzadko ma parametry. Oto kilka przykładów destruktorów: destruktor Pole gotowe; rozpocząć FreeMem(Nazwa, Długość(Nazwa^) + 1); puszki; destruktor StrField.Done; rozpocząć FreeMem(Wartość, Len); Pole gotowe; puszki; Destruktor typu podrzędnego, takiego jak powyższy TStrField. Gotowe, zazwyczaj najpierw usuwa pola wskaźnika wprowadzone w typie pochodnym, a następnie, jako ostatni krok, wywołuje odpowiedni destruktor kolektora bezpośredniego elementu nadrzędnego, aby usunąć dziedziczone pola wskaźnika obiektu. 31. Destruktory Borland Pascal zapewnia specjalny rodzaj metody zwanej garbage collector (lub destruktor) do czyszczenia i usuwania dynamicznie przydzielonego obiektu. Destruktor łączy etap usuwania obiektu z innymi czynnościami lub zadaniami wymaganymi dla tego typu obiektu. Dla jednego typu obiektu można zdefiniować wiele destruktorów. Destruktory mogą być dziedziczone i mogą być statyczne lub wirtualne. Ponieważ różne finalizatory zwykle wymagają różnych typów obiektów, ogólnie zaleca się, aby destruktory były zawsze wirtualne, aby dla każdego typu obiektu wykonywany był poprawny destruktor. Destruktor słowa zastrzeżonego nie musi być określany dla każdej metody czyszczenia, nawet jeśli definicja typu obiektu zawiera metody wirtualne. Destruktory tak naprawdę działają tylko na dynamicznie alokowanych obiektach. Kiedy dynamicznie alokowany obiekt jest czyszczony, destruktor wykonuje specjalną funkcję: zapewnia, że w dynamicznie alokowanym obszarze pamięci zawsze zwalniana jest prawidłowa liczba bajtów. Nie ma obaw o używanie destruktora ze statycznie przydzielonymi obiektami; w rzeczywistości, nie przekazując typu obiektu do destruktora, programista pozbawia obiekt tego typu pełnych korzyści dynamicznego zarządzania pamięcią w Borland Pascal. Destruktory w rzeczywistości stają się sobą, gdy obiekty polimorficzne muszą zostać wyczyszczone, a pamięć, którą zajmują, musi zostać zwolniona. Obiekty polimorficzne to te obiekty, które zostały przypisane do typu nadrzędnego ze względu na rozszerzone zasady zgodności typów Borland Pascal. Termin „polimorficzny” jest odpowiedni, ponieważ kod przetwarzający obiekt „nie wie” dokładnie w czasie kompilacji, jakiego typu obiekt będzie ostatecznie musiał przetworzyć. Wie tylko, że ten obiekt należy do hierarchii obiektów, które są potomkami określonego typu obiektu. Sama metoda destruktora może być pusta i wykonywać tylko tę funkcję: destruktorObiekt.Wykonane; rozpocząć puszki; To, co jest przydatne w tym destruktorze, nie jest własnością jego ciała, jednak kompilator generuje kod epilogu w odpowiedzi na słowo zastrzeżone destruktora. Jest jak moduł, który niczego nie eksportuje, ale wykonuje pewną niewidoczną pracę, wykonując sekcję inicjalizacji przed uruchomieniem programu. Cała akcja rozgrywa się za kulisami. 32. Metody wirtualne Metoda staje się wirtualna, jeśli po jej deklaracji typu obiektu następuje nowe zastrzeżone słowo virtual. Jeśli metoda w typie nadrzędnym jest zadeklarowana jako wirtualna, wszystkie metody o tej samej nazwie w typach podrzędnych muszą być również zadeklarowane jako wirtualne, aby uniknąć błędu kompilatora. Poniżej znajdują się obiekty z przykładowej listy płac, odpowiednio zwirtualizowane: rodzaj PEpracownik = ^TEpracownik; Pracownik = obiekt Nazwa, Tytuł: ciąg[25]; Oceń: Realne; konstruktor Init(AName, ATitle: String; ARate: Real); funkcja GetPayAmount: Real; wirtualny; funkcja GetName: ciąg; funkcja GetTitle: String; funkcja GetRate: Real; procedura Pokaż; wirtualny; puszki; PH co godzinę = ^T co godzinę; Czwarty = obiekt(Pracownik); Czas: liczba całkowita; konstruktor Init(Nazwa, ATitle: String; ARate: Real; Czas: liczba całkowita); funkcja GetPayAmount: Real; wirtualny; funkcja GetTime: Liczba całkowita; puszki; PSopłacany = ^TSopłacany; TSalaried = obiekt(Tpracownik); funkcja GetPayAmount: Real; wirtualny; puszki; PCzadane = ^TCzadane; TCommissioned = obiekt (opłacany); Prowizja: Rzeczywista; Kwota sprzedaży: rzeczywista; konstruktor Init(AName, ATitle: String; ARate, AProwizja, AKwota Sprzedaży: Rzeczywista); funkcja GetPayAmount: Real; wirtualny; puszki; Konstruktor to specjalny rodzaj procedury, która wykonuje pewne czynności konfiguracyjne dla mechanizmu metody wirtualnej. Ponadto konstruktor musi zostać wywołany przed wywołaniem jakiejkolwiek metody wirtualnej. Wywołanie metody wirtualnej bez wcześniejszego wywołania konstruktora może zablokować system, a kompilator nie ma możliwości sprawdzenia kolejności wywoływania metod. Każdy typ obiektu, który ma metody wirtualne, musi mieć konstruktora. Konstruktor musi zostać wywołany przed wywołaniem jakiejkolwiek innej metody wirtualnej. Wywołanie metody wirtualnej bez wcześniejszego wywołania konstruktora może spowodować blokadę systemu, a kompilator nie może sprawdzić kolejności wywoływania metod. 33. Pola danych obiektu i parametry metody formalnej Implikacją faktu, że metody i ich obiekty mają wspólny zakres, jest to, że parametry formalne metody nie mogą być identyczne z żadnym z pól danych obiektu. Nie jest to jakieś nowe ograniczenie narzucone przez programowanie obiektowe, ale raczej te same stare zasady zakresu, które zawsze miał Pascal. Jest to równoznaczne z zakazem, aby parametry formalne procedury były identyczne ze zmiennymi lokalnymi procedury. Rozważ przykład ilustrujący ten błąd dla procedury: procedura CrunchIt(Crunchee: MyDataRec, Crunchby, Kod błędu: liczba całkowita); było A, B: znak; Kod błędu: liczba całkowita; rozpocząć . . . puszki; Wystąpił błąd w wierszu zawierającym deklarację zmiennej lokalnej ErrorCode. Dzieje się tak, ponieważ identyfikatory parametru formalnego i zmiennej lokalnej są takie same. Zmienne lokalne procedury i jej parametry formalne mają wspólny zakres i dlatego nie mogą być identyczne. Otrzymasz komunikat „Błąd 4: Zduplikowany identyfikator”, jeśli spróbujesz skompilować coś takiego. Ten sam błąd występuje przy próbie przypisania parametru metody formalnej do nazwy pola obiektu, do którego należy ta metoda. Okoliczności są nieco inne, ponieważ umieszczenie nagłówka podprogramu w strukturze danych jest ukłonem w stronę innowacji w Turbo Pascalu, ale podstawowe zasady zakresu Pascala nie uległy zmianie. Podczas wybierania identyfikatorów zmiennych i parametrów nadal musisz szanować określoną kulturę. Niektóre style programowania oferują sposoby nazywania pól typu w celu zmniejszenia ryzyka zduplikowanych identyfikatorów. Na przykład notacja węgierska sugeruje, że nazwy pól zaczynają się od przedrostka „m”. 34. Hermetyzacja Połączenie kodu i danych w obiekcie nazywa się enkapsulacją. W zasadzie możliwe jest zapewnienie wystarczającej liczby metod, aby użytkownik obiektu nigdy nie miał bezpośredniego dostępu do pól obiektu. Niektóre inne języki obiektowe, takie jak Smalltalk, wymagają obowiązkowej enkapsulacji, ale Borland Pascal ma wybór. Na przykład obiekty TEmployee i THourly są napisane w taki sposób, że absolutnie nie ma potrzeby bezpośredniego dostępu do ich wewnętrznych pól danych: rodzaj Pracownik = obiekt Nazwa, Tytuł: ciąg[25]; Oceń: Realne; procedure Init(AName, ATitle: string; ARate: Real); funkcja GetName: ciąg; funkcja GetTitle: String; funkcja GetRate: Real; funkcja GetPayAmount: Real; puszki; Czwarty = obiekt (Pracownik) Czas: liczba całkowita; procedura Init(AName, ATitle: string; ARate: Rzeczywiste, czas: liczba całkowita); funkcja GetPayAmount: Real; puszki; Znajdują się tu tylko cztery pola danych: Imię i Nazwisko, Tytuł, Oceń i Czas. Metody GetName i GetTitle wyświetlają odpowiednio nazwisko i stanowisko pracownika. Metoda GetPayAmount wykorzystuje Rate, aw przypadku działającego Tgodziny i Czas do obliczenia kwoty wpłat do działającego. Nie ma już potrzeby bezpośredniego odwoływania się do tych pól danych. Zakładając istnienie instancji AnHourly typu THourly, możemy użyć zestawu metod do manipulowania polami danych AnHourly, na przykład: z godzinowym do rozpocząć Init (Aleksandr Pietrow, operator wózka widłowego 12.95, 62); {Wyświetla nazwisko, stanowisko i kwotę płatności} Pokazać; puszki; Należy zauważyć, że dostęp do pól obiektu odbywa się tylko za pomocą metod tego obiektu. 35. Rozszerzanie obiektów Jeśli zdefiniowano typ pochodny, metody typu nadrzędnego są dziedziczone, ale w razie potrzeby można je zastąpić. Aby przesłonić metodę dziedziczoną, po prostu zadeklaruj nową metodę o tej samej nazwie co metoda dziedziczona, ale z inną treścią i (jeśli to konieczne) innym zestawem parametrów. Zdefiniujmy typ podrzędny TEmployee, który reprezentuje pracownika, który otrzymuje stawkę godzinową w następującym przykładzie: const OkresyPłatności = 26; { okresy płatności } Próg dogrywki = 80; { za okres płatności } Współczynnik nadgodzin = 1.5; { stawka godzinowa } rodzaj Czwarty = obiekt (Pracownik) Czas: liczba całkowita; procedura Init(AName, ATitle: string; ARate: Rzeczywiste, czas: liczba całkowita); funkcja GetPayAmount: Real; puszki; procedura THourly.Init(Nazwa, ATitle: ciąg; ARate: rzeczywista, czas: liczba całkowita); rozpocząć TEmployee.Init(Nazwisko, ATtytuł, ARate); Czas:= Czas; puszki; funkcja THourly.GetPayAmount: Real; było Nadgodziny: liczba całkowita; rozpocząć Nadgodziny:= Czas - Próg nadgodzin; jeśli dogrywka > 0 to GetPayAmount:= RoundPay (Próg w godzinach nadliczbowych * Stawka + RateOverTime * OvertimeFactor *Wskaźnik) więcej GetPayAmount:= RoundPay (czas * stawka) puszki; Podczas wywoływania przesłoniętej metody należy upewnić się, że pochodny typ obiektu zawiera funkcjonalność elementu nadrzędnego. Ponadto każda zmiana w metodzie rodzicielskiej automatycznie wpływa na wszystkich potomków. Ważna uwaga: Chociaż metody można zastąpić, pola danych nie mogą zostać zastąpione. Po zdefiniowaniu pola danych w hierarchii obiektów żaden typ podrzędny nie może zdefiniować pola danych o dokładnie takiej samej nazwie. 36. Kompatybilność typów obiektów Dziedziczenie modyfikuje do pewnego stopnia reguły zgodności typów Borland Pascal. Potomek dziedziczy zgodność typów wszystkich swoich przodków. Ta rozszerzona zgodność typów przybiera trzy formy: 1) między realizacjami obiektów; 2) między wskaźnikami do realizacji obiektów; 3) pomiędzy parametrami formalnymi a rzeczywistymi. Zgodność typów rozciąga się tylko od dziecka do rodzica. Na przykład TSalaried jest dzieckiem TEmployee, a TCommissioned jest dzieckiem TSalaried. Rozważ następujące opisy: było Pracownik: Pracownik; ASalary: TSalary; PCzamówione: TZamówione; TEpracownikPtr: ^TEpracownik; TSalowanyPtr: ^TSalowany; TZamówionePtr: ^TZamówione; W tych opisach obowiązują następujące operatory przypisania: Pracownik:=Wynagrodzony; ASopłacił:= Azamówiony; TRozpoczętyPtr:= ARozpoczęty; Ogólnie zasada zgodności typu jest sformułowana w następujący sposób: źródło musi być w stanie całkowicie napełnić odbiornik. Typy pochodne zawierają wszystko, co zawierają ich typy nadrzędne ze względu na właściwość dziedziczenia. Dlatego typ pochodny ma rozmiar nie mniejszy niż rozmiar rodzica. Przypisanie obiektu nadrzędnego do obiektu podrzędnego może pozostawić niektóre pola obiektu nadrzędnego niezdefiniowane, co jest niebezpieczne i dlatego nielegalne. W instrukcjach przypisania tylko pola, które są wspólne dla obu typów, zostaną skopiowane ze źródła do miejsca docelowego. W operatorze przypisania: Pracownik:= Azatrudniony; Tylko pola Name, Title i Rate z ACommissioned zostaną skopiowane do AnEmployee, ponieważ są to jedyne pola współdzielone przez TCommissioned i TEmployee. Zgodność typów działa również między wskaźnikami do typów obiektów i podlega tym samym ogólnym zasadom, co w przypadku implementacji obiektów. Wskaźnik do dziecka można przypisać do wskaźnika do rodzica. Biorąc pod uwagę poprzednie definicje, następujące przypisania wskaźników są prawidłowe: TSalariedPtr:= TZamówionePtr; TEpracownikPtr:= TSalariedPtr; PtrPpracownika:=PtrPrzPrac; Parametr formalny (wartość lub parametr zmienny) danego typu obiektu może przyjąć jako rzeczywisty parametr obiekt własnego typu lub obiekty wszystkich typów podrzędnych. Jeśli zdefiniujesz taki nagłówek procedury: procedura CalcFedTax (ofiara: TSalaried); wtedy rzeczywiste typy parametrów mogą być TSalaried lub TCommissioned, ale nie TEmployee. Ofiara może być również parametrem zmiennym. W takim przypadku obowiązują te same zasady zgodności. Parametr wartości jest wskaźnikiem do rzeczywistego obiektu przekazywanego jako parametr, a parametr zmiennej jest kopią rzeczywistego parametru. Ta kopia zawiera tylko te pola, które są częścią typu formalnego parametru wartości. Oznacza to, że rzeczywisty parametr jest konwertowany na typ parametru formalnego. 37. O asemblerze Dawno, dawno temu asembler był językiem bez wiedzy o tym, że nie można sprawić, by komputer robił cokolwiek pożytecznego. Stopniowo sytuacja się zmieniła. Pojawiły się wygodniejsze środki komunikacji z komputerem. Ale w przeciwieństwie do innych języków, asembler nie umarł, co więcej, nie mógł tego zrobić w zasadzie. Czemu? W poszukiwaniu odpowiedzi postaramy się zrozumieć, czym w ogóle jest język asemblera. W skrócie, język asemblera jest symboliczną reprezentacją języka maszynowego. Wszystkie procesy w maszynie na najniższym poziomie sprzętowym sterowane są wyłącznie poleceniami (instrukcjami) języka maszynowego. Z tego jasno wynika, że pomimo wspólnej nazwy, język asemblera dla każdego typu komputera jest inny. Dotyczy to również wyglądu programów napisanych w asemblerze oraz idei, których odzwierciedleniem jest ten język. Rzeczywiste rozwiązywanie problemów sprzętowych (a nawet bardziej sprzętowych, takich jak np. przyspieszenie programu) jest niemożliwe bez znajomości asemblera. Programista lub każdy inny użytkownik może używać dowolnych narzędzi wysokiego poziomu aż do programów do budowania wirtualnych światów i być może nawet nie podejrzewa, że komputer faktycznie wykonuje polecenia języka, w którym napisany jest jego program, ale ich przekształconą reprezentację. w postaci nudnej i nudnej sekwencji poleceń zupełnie innego języka - języka maszynowego. Teraz wyobraź sobie, że taki użytkownik ma niestandardowy problem. Na przykład jego program musi współpracować z jakimś nietypowym urządzeniem lub wykonywać inne czynności, które wymagają znajomości zasad działania sprzętu komputerowego. Bez względu na to, jak dobry jest język, w którym programista napisał swój program, nie może obejść się bez znajomości asemblera. I to nie przypadek, że prawie wszystkie kompilatory języków wysokiego poziomu zawierają środki łączenia swoich modułów z modułami w asemblerze lub obsługują dostęp do poziomu programowania asemblera. Komputer składa się z kilku fizycznych urządzeń, z których każde jest podłączone do pojedynczej jednostki zwanej jednostką systemową. 38. Model oprogramowania mikroprocesora Na dzisiejszym rynku komputerowym istnieje wiele różnych typów komputerów. W związku z tym można założyć, że konsument będzie miał pytanie - jak ocenić możliwości określonego typu (lub modelu) komputera i jego cechy odróżniające od komputerów innych typów (modeli). Rozważenie tylko schematu blokowego komputera nie wystarczy, ponieważ zasadniczo różni się on niewiele w różnych maszynach: wszystkie komputery mają pamięć RAM, procesor i urządzenia zewnętrzne. Różne są sposoby, środki i zasoby, za pomocą których komputer funkcjonuje jako pojedynczy mechanizm. Aby zebrać wszystkie koncepcje charakteryzujące komputer pod względem jego funkcjonalnych właściwości sterowanych programem, istnieje specjalny termin - architektura komputera. Po raz pierwszy pojęcie architektury komputerowej zaczęto wspominać wraz z pojawieniem się maszyn trzeciej generacji w celu ich oceny porównawczej. Rozpoczęcie nauki języka asemblera dowolnego komputera ma sens dopiero po ustaleniu, jaka część komputera jest widoczna i dostępna do programowania w tym języku. Jest to tzw. model programu komputerowego, którego częścią jest model programu mikroprocesorowego, który zawiera 32 rejestry mniej lub bardziej dostępne dla programisty. Rejestry te można podzielić na dwie duże grupy: 1) 16 rejestrów użytkowników; 2) 16 rejestrów systemowych. Programy asemblerowe bardzo intensywnie używają rejestrów. Większość rejestrów ma określony cel funkcjonalny. Oprócz rejestrów wymienionych powyżej, twórcy procesorów wprowadzają do modelu oprogramowania dodatkowe rejestry przeznaczone do optymalizacji pewnych klas obliczeń. Tak więc w rodzinie procesorów Pentium Pro (MMX) firmy Intel Corporation wprowadzono rozszerzenie MMX firmy Intel. Zawiera 8 (MM0-MM7) 64-bitowych rejestrów i umożliwia wykonywanie operacji na liczbach całkowitych na parach kilku nowych typów danych: 1) osiem spakowanych bajtów; 2) cztery spakowane słowa; 3) dwa podwójne słowa; 4) słowo poczwórne; Innymi słowy, za pomocą jednej instrukcji rozszerzającej MMX, programista może na przykład dodać do siebie dwa podwójne słowa. Fizycznie nie dodano żadnych nowych rejestrów. MM0-MM7 to mantysy (dolne 64 bity) stosu 80-bitowych rejestrów FPU (jednostka zmiennoprzecinkowa - koprocesor). Ponadto w tej chwili dostępne są następujące rozszerzenia modelu programowania - 3DNOW! od AMD; SSE, SSE2, SSE3, SSE4. Ostatnie 4 rozszerzenia są obsługiwane zarówno przez procesory AMD, jak i Intel. 39. Rejestry użytkowników Jak sama nazwa wskazuje, rejestry użytkownika są wywoływane, ponieważ programista może ich używać podczas pisania swoich programów. Rejestry te obejmują: 1) osiem rejestrów 32-bitowych, które mogą być używane przez programistów do przechowywania danych i adresów (są one również nazywane rejestrami ogólnego przeznaczenia (RON)): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ ebp/bp; ▪ esi/si; ▪ edi/di; ▪ esp/sp. 2) sześć rejestrów segmentowych: ▪ cs; ▪ ds; ▪ ss; ▪ es; ▪ fs; ▪ gs; 3) rejestry stanu i kontroli: ▪ регистр флагов eflags/flags; ▪ регистр указателя команды eip/ip. Poniższy rysunek przedstawia główne rejestry mikroprocesora: Rejestry ogólnego przeznaczenia
40. Rejestry ogólne Wszystkie rejestry z tej grupy umożliwiają dostęp do ich „dolnych” części. Tylko dolne 16- i 8-bitowe części tych rejestrów mogą być używane do samodzielnego adresowania. Górne 16 bitów tych rejestrów nie jest dostępnych jako niezależne obiekty. Wymieńmy rejestry należące do grupy rejestrów ogólnego przeznaczenia. Ponieważ te rejestry są fizycznie zlokalizowane w mikroprocesorze wewnątrz jednostki arytmetyczno-logicznej (ALU), nazywane są również rejestrami ALU: 1) eax/ax/ah/al (Rejestr akumulatorów) - bateria. Służy do przechowywania danych pośrednich. W niektórych poleceniach użycie tego rejestru jest obowiązkowe; 2) ebx/bx/bh/bl (rejestr bazowy) - rejestr bazowy. Używany do przechowywania adresu bazowego jakiegoś obiektu w pamięci; 3) ecx/cx/ch/cl (rejestr licznika) - rejestr licznika. Jest używany w poleceniach, które wykonują pewne powtarzalne czynności. Jego użycie jest często ukryte i ukryte w algorytmie odpowiedniego polecenia. Na przykład polecenie organizacji pętli, oprócz przekazania sterowania do polecenia znajdującego się pod określonym adresem, analizuje i dekrementuje wartość rejestru ecx/cx o jeden; 4) edx/dx/dh/dl (Rejestr danych) - rejestr danych. Podobnie jak rejestr eax/ax/ah/al przechowuje dane pośrednie. Niektóre polecenia wymagają jego użycia; w przypadku niektórych poleceń dzieje się to niejawnie. Następujące dwa rejestry służą do obsługi tzw. operacji łańcuchowych, czyli operacji sekwencyjnie przetwarzających łańcuchy elementów, z których każdy może mieć długość 32, 16 lub 8 bitów: 1) esi/si (rejestr indeksów źródłowych) - indeks źródłowy. Ten rejestr w operacjach łańcuchowych zawiera aktualny adres elementu w łańcuchu źródłowym; 2) edi/di (rejestr wskaźnika przeznaczenia) - indeks odbiorcy (odbiorcy). Ten rejestr w operacjach łańcuchowych zawiera aktualny adres w łańcuchu docelowym. W architekturze mikroprocesora, na poziomie sprzętu i oprogramowania, obsługiwana jest taka struktura danych jak stos. Do pracy ze stosem w systemie instrukcji mikroprocesora są specjalne polecenia, aw modelu oprogramowania mikroprocesora są do tego specjalne rejestry: 1) esp/sp (rejestr wskaźnika stosu) - rejestr wskaźnika stosu. Zawiera wskaźnik do szczytu stosu w bieżącym segmencie stosu. 2) ebp/bp (rejestr wskaźnika bazowego) - rejestr wskaźnika bazowego ramki stosu. Zaprojektowany do organizowania losowego dostępu do danych wewnątrz stosu. Użycie twardego przypinania rejestrów dla niektórych instrukcji umożliwia bardziej zwięzłe kodowanie ich reprezentacji maszynowej. Znajomość tych cech pozwoli w razie potrzeby zaoszczędzić co najmniej kilka bajtów pamięci zajmowanej przez kod programu. 41. Rejestry segmentowe W modelu oprogramowania mikroprocesorowego istnieje sześć rejestrów segmentowych: cs, ss, ds, es, gs, fs. Ich istnienie wynika ze specyfiki organizacji i wykorzystania pamięci RAM przez mikroprocesory Intela. Polega ona na tym, że sprzęt mikroprocesorowy wspiera strukturalną organizację programu w postaci trzech części, zwanych segmentami. W związku z tym taka organizacja pamięci nazywana jest segmentacją. W celu wskazania segmentów, do których program ma dostęp w określonym momencie, przeznaczone są rejestry segmentowe. W rzeczywistości (z niewielką poprawką) rejestry te zawierają adresy pamięci, od których zaczynają się odpowiednie segmenty. Logika przetwarzania instrukcji maszynowej jest skonstruowana w taki sposób, że podczas pobierania instrukcji, dostępu do danych programu lub dostępu do stosu, adresy w dobrze zdefiniowanych rejestrach segmentowych są niejawnie używane. Mikroprocesor obsługuje następujące typy segmentów. 1. Segment kodu. Zawiera polecenia programu. Aby uzyskać dostęp do tego segmentu, używany jest rejestr cs (rejestr segmentu kodu) - rejestr kodu segmentu. Zawiera adres segmentu instrukcji maszynowych, do którego mikroprocesor ma dostęp (tj. instrukcje te są ładowane do potoku mikroprocesora). 2. Segment danych. Zawiera dane przetwarzane przez program. Aby uzyskać dostęp do tego segmentu, używany jest rejestr ds (rejestr segmentu danych) - rejestr segmentu danych, który przechowuje adres segmentu danych bieżącego programu. 3. Segment stosu. Ten segment jest regionem pamięci zwanym stosem. Mikroprocesor organizuje pracę ze stosem według następującej zasady: jako pierwszy wybierany jest ostatni element zapisany w tym obszarze. Aby uzyskać dostęp do tego segmentu, używany jest rejestr ss (rejestr segmentu stosu) - rejestr segmentu stosu zawierający adres segmentu stosu. 4. Dodatkowy segment danych. W domyśle algorytmy wykonywania większości instrukcji maszynowych zakładają, że przetwarzane przez nie dane znajdują się w segmencie danych, którego adres znajduje się w rejestrze segmentowym ds. Jeśli program nie ma wystarczającej ilości jednego segmentu danych, ma możliwość wykorzystania trzech dodatkowych segmentów danych. Ale w przeciwieństwie do głównego segmentu danych, którego adres jest zawarty w rejestrze segmentu ds, podczas używania dodatkowych segmentów danych, ich adresy muszą być wyraźnie określone za pomocą specjalnych prefiksów redefiniujących segment w poleceniu. Adresy dodatkowych segmentów danych muszą być zawarte w rejestrach es, gs, fs (rejestry rozszerzonego segmentu danych). 42. Rejestry statusu i kontroli Mikroprocesor zawiera kilka rejestrów, które stale zawierają informacje o stanie zarówno samego mikroprocesora, jak i programu, którego instrukcje są aktualnie ładowane do potoku. Rejestry te obejmują: 1) flagi rejestru flag/flagi; 2) rejestr wskaźnika poleceń eip/ip. Korzystając z tych rejestrów można uzyskać informacje o wynikach wykonania polecenia oraz wpływać na stan samego mikroprocesora. Rozważmy bardziej szczegółowo cel i zawartość tych rejestrów. 1. flagi/flagi (rejestr flag) - rejestr flag. Głębokość bitowa flag/flag wynosi 32/16 bitów. Poszczególne bity tego rejestru mają określony cel funkcjonalny i nazywane są flagami. Dolna część tego rejestru jest całkowicie podobna do rejestru flag dla i8086. W zależności od sposobu ich użycia flagi rejestru flag/flag można podzielić na trzy grupy: 1) osiem flag stanu. Te flagi mogą ulec zmianie po wykonaniu instrukcji maszynowych. Flagi stanu rejestru flag odzwierciedlają specyfikę wyniku wykonania operacji arytmetycznych lub logicznych. Umożliwia to analizę stanu procesu obliczeniowego i reagowanie na niego za pomocą poleceń skoku warunkowego i wywołań podprogramów. 2) jedna flaga kontrolna. Oznaczony df (flaga katalogu). Znajduje się w bicie 10 rejestru flag i jest używany przez połączone polecenia. Wartość flagi df określa kierunek przetwarzania element po elemencie w tych operacjach: od początku ciągu do końca (df = 0) lub odwrotnie, od końca ciągu do jego początku (df = 1). Istnieją specjalne polecenia do pracy z flagą df: cld (usuń flagę df) i std (ustaw flagę df). Użycie tych poleceń pozwala dostosować flagę df zgodnie z algorytmem i zapewnić, że liczniki są automatycznie zwiększane lub zmniejszane podczas wykonywania operacji na ciągach. 3) pięć flag systemowych. Kontrolują one wejścia/wyjścia, przerwania maskowalne, debugowanie, przełączanie zadań i tryb wirtualny 8086. Nie zaleca się, aby programy użytkowe niepotrzebnie modyfikowały te flagi, ponieważ w większości przypadków spowoduje to zakończenie programu. 2. eip/ip (rejestr wskaźnika instrukcji) - rejestr wskaźnika instrukcji. Rejestr eip/ip ma szerokość 32/16 bitów i zawiera przesunięcie następnej instrukcji do wykonania względem zawartości rejestru segmentu cs w bieżącym segmencie instrukcji. Rejestr ten nie jest bezpośrednio dostępny dla programisty, ale jego wartość jest ładowana i zmieniana przez różne polecenia sterujące, które obejmują polecenia skoków warunkowych i bezwarunkowych, wywoływanie procedur i powrót z procedur. Wystąpienie przerwań modyfikuje również rejestr eip/ip. 43. Rejestry systemu mikroprocesorowego Już sama nazwa tych rejestrów sugeruje, że pełnią one w systemie określone funkcje. Korzystanie z rejestrów systemowych jest ściśle regulowane. To oni zapewniają tryb chroniony. Można je również traktować jako część architektury mikroprocesorowej, która jest celowo widoczna, aby wykwalifikowany programista systemu mógł wykonywać najbardziej niskopoziomowe operacje. Rejestry systemowe można podzielić na trzy grupy: 1) cztery rejestry kontrolne; Grupa rejestrów kontrolnych obejmuje 4 rejestry: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) cztery systemowe rejestry adresowe (zwane również rejestrami zarządzania pamięcią); Rejestry adresowe systemu obejmują następujące rejestry: ▪ регистр таблицы глобальных дескрипторов gdtr; ▪ регистр таблицы локальных дескрипторов Idtr; ▪ регистр таблицы дескрипторов прерываний idtr; ▪ 16-битовый регистр задачи tr; 3) osiem rejestrów debugowania. Obejmują one: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. Znajomość rejestrów systemowych nie jest konieczna do pisania programów w asemblerze, z uwagi na to, że służą one głównie do realizacji najbardziej niskopoziomowych operacji. Jednak obecne trendy w rozwoju oprogramowania (zwłaszcza w świetle znacznie zwiększonych możliwości optymalizacyjnych nowoczesnych kompilatorów języków wysokiego poziomu, które często generują kod o wyższej wydajności niż kod ludzki) zawężają zakres Assemblera do rozwiązywania najsłabszych problemy na poziomie, gdzie znajomość powyższych rejestrów może okazać się bardzo przydatna. 44. Rejestry kontrolne W skład grupy rejestrów kontrolnych wchodzą cztery rejestry: cr0, cr1, cr2, cr3. Rejestry te służą do ogólnej kontroli systemu. Rejestry kontrolne są dostępne tylko dla programów z poziomem uprawnień 0. Chociaż mikroprocesor ma cztery rejestry kontrolne, dostępne są tylko trzy z nich - wykluczony jest cr1, którego funkcje nie są jeszcze zdefiniowane (jest zarezerwowany do przyszłego użytku). Rejestr cr0 zawiera flagi systemowe, które kontrolują tryby pracy mikroprocesora i odzwierciedlają jego stan globalnie, niezależnie od wykonywanych zadań. Cel flag systemowych: 1) pe (Włącz ochronę), bit 0 - włącz tryb chroniony. Stan tej flagi wskazuje, w którym z dwóch trybów – rzeczywistym (pe = 0) czy chronionym (pe = 1) – mikroprocesor pracuje w określonym czasie; 2) mp (Math Present), bit 1 - obecność koprocesora. Zawsze 1; 3) ts (Task Switched), bit 3 - przełączanie zadań. Procesor automatycznie ustawia ten bit, gdy przełącza się na inne zadanie; 4) am (Alignment Mask), bit 18 - maska wyrównania. Ten bit włącza (am = 1) lub wyłącza (am = 0) kontrolę wyrównania; 5) cd (Cache Disable), bit 30 - wyłącza pamięć podręczną. Za pomocą tego bitu możesz wyłączyć (cd = 1) lub włączyć (cd = 0) korzystanie z wewnętrznej pamięci podręcznej (pamięć podręczna pierwszego poziomu); 6) pg (PaGing), bit 31 - włącz (pg = 1) lub wyłącz (pg = 0) stronicowanie. Flaga jest używana w modelu stronicowania organizacji pamięci. Rejestr cr2 jest używany w stronicowaniu pamięci RAM do zarejestrowania sytuacji, w której bieżąca instrukcja uzyskała dostęp do adresu zawartego na stronie pamięci, której aktualnie nie ma w pamięci. W takiej sytuacji w mikroprocesorze występuje wyjątek numer 14, a liniowy 32-bitowy adres instrukcji, która spowodowała ten wyjątek, jest zapisywany w rejestrze cr2. Na podstawie tych informacji program obsługi wyjątków 14 określa żądaną stronę, zamienia ją w pamięci i wznawia normalne działanie programu; Rejestr cr3 jest również używany do pamięci stronicowania. Jest to tak zwany rejestr katalogów stron pierwszego poziomu. Zawiera 20-bitowy fizyczny adres bazowy katalogu stron bieżącego zadania. Katalog ten zawiera 1024 32-bitowe deskryptory, z których każdy zawiera adres tablicy stron drugiego poziomu. Z kolei każda z tablic stron drugiego poziomu zawiera 1024 32-bitowych deskryptorów, które adresują ramki stron w pamięci. Rozmiar ramki strony to 4 KB. 45. Rejestry adresów systemowych Rejestry te są również nazywane rejestrami zarządzania pamięcią. Przeznaczone są do ochrony programów i danych w trybie wielozadaniowym mikroprocesora. Podczas pracy w trybie chronionym mikroprocesorem przestrzeń adresowa dzieli się na: 1) globalny - wspólny dla wszystkich zadań; 2) lokalna – odrębna dla każdego zadania. To rozdzielenie wyjaśnia obecność następujących rejestrów systemowych w architekturze mikroprocesora: 1) rejestr globalnej tablicy deskryptorów gdtr (Global Descriptor Table Register), mający rozmiar 48 bitów i zawierający 32-bitowy (bity 16-47) adres bazowy globalnej tablicy deskryptorów GDT oraz 16-bitowy (bity 0-15) wartość graniczna, czyli rozmiar w bajtach tablicy GDT; 2) rejestr tablicy lokalnych deskryptorów ldtr (Local Descriptor Table Register), o rozmiarze 16 bitów i zawierający tzw. selektor deskryptorów lokalnej tablicy deskryptorów LDT. Ten selektor jest wskaźnikiem do GDT, który opisuje segment zawierający lokalną tablicę deskryptorów LDT; 3) rejestr tablicy deskryptorów przerwań idtr (Interrupt Descriptor Table Register), mający rozmiar 48 bitów i zawierający 32-bitowy (bity 16-47) adres bazowy tablicy deskryptorów przerwań IDT oraz 16-bitowy (bity 0-15) wartość graniczna, czyli rozmiar w bajtach tablicy IDT; 4) 16-bitowy rejestr zadań tr (Task Register), który podobnie jak rejestr ldtr zawiera selektor, czyli wskaźnik do deskryptora w tablicy GDT. Ten deskryptor opisuje aktualny status segmentu zadań (TSS). Segment ten tworzony jest dla każdego zadania w systemie, ma ściśle uregulowaną strukturę i zawiera kontekst (stan aktualny) zadania. Głównym celem segmentów TSS jest przechowywanie aktualnego stanu zadania w momencie przejścia do innego zadania. 46. Rejestry debugowania Jest to bardzo ciekawa grupa rejestrów przeznaczona do debugowania sprzętowego. Narzędzia do debugowania sprzętu po raz pierwszy pojawiły się w mikroprocesorze i486. Sprzętowo mikroprocesor zawiera osiem rejestrów debugowania, ale tylko sześć z nich jest faktycznie używanych. Rejestry dr0, dr1, dr2, dr3 mają szerokość 32 bitów i służą do ustawiania adresów liniowych czterech punktów przerwania. Mechanizm zastosowany w tym przypadku jest następujący: dowolny adres wygenerowany przez bieżący program jest porównywany z adresami w rejestrach dr0... dr3 i w przypadku dopasowania generowany jest wyjątek debugowania o numerze 1. Rejestr dr6 nazywany jest rejestrem statusu debugowania. Bity w tym rejestrze są ustawione zgodnie z przyczynami, które spowodowały wystąpienie ostatniego wyjątku numer 1. Wymieniamy te bity i ich przeznaczenie: 1) b0 - jeżeli ten bit jest ustawiony na 1, to ostatni wyjątek (przerwanie) wystąpił w wyniku osiągnięcia punktu kontrolnego zdefiniowanego w rejestrze dr0; 2) b1 - podobnie jak b0, ale dla punktu kontrolnego w rejestrze dr1; 3) b2 - podobnie jak b0, ale dla punktu kontrolnego w rejestrze dr2; 4) b3 - podobnie jak b0, ale dla punktu kontrolnego w rejestrze dr3; 5) bd (bit 13) - służy do ochrony rejestrów debugowania; 6) bs (bit 14) - ustawiany na 1 jeśli wyjątek 1 był spowodowany stanem flagi tf=1 w rejestrze flag; 7) bt (бит 15) устанавливается в 1, если исключение 1 было вызвано переключением на задачу с установленным битом ловушки в TSS t = 1. Все остальные биты в этом регистре заполняются нулями. Обработчик исключения 1 по содержимому dr6 должен определить причину, по которой произошло исключение, и выполнить необходимые действия. Rejestr dr7 nazywany jest rejestrem kontrolnym debugowania. Zawiera pola dla każdego z czterech rejestrów punktów przerwania debugowania, które pozwalają określić następujące warunki, w których powinno zostać wygenerowane przerwanie: 1) lokalizacja rejestracji punktu kontrolnego - tylko w bieżącym zadaniu lub w dowolnym zadaniu. Bity te zajmują dolne 8 bitów rejestru dr7 (2 bity na każdy punkt przerwania (właściwie punkt przerwania) ustawiony odpowiednio przez rejestry dr0, drl, dr2, dr3). Pierwszy bit każdej pary to tak zwana rozdzielczość lokalna; ustawienie go mówi punktowi przerwania, aby zadziałał, jeśli znajduje się w przestrzeni adresowej bieżącego zadania. Drugi bit w każdej parze określa zezwolenie globalne, które wskazuje, że dany punkt przerwania jest ważny w przestrzeniach adresowych wszystkich zadań w systemie; 2) rodzaj dostępu, przez który zainicjowane jest przerwanie: tylko podczas pobierania polecenia, podczas zapisu lub podczas zapisu / odczytu danych. Bity określające ten charakter wystąpienia przerwania znajdują się w górnej części tego rejestru. Większość rejestrów systemowych jest dostępna programowo. 47. Struktura programu w asemblerze Program w języku asemblerowym jest zbiorem bloków pamięci zwanych segmentami pamięci. Program może składać się z jednego lub więcej takich segmentów bloków. Każdy segment zawiera zbiór zdań językowych, z których każdy zajmuje oddzielny wiersz kodu programu. Oświadczenia montażowe są czterech typów. Polecenia lub instrukcje, które są symbolicznym odpowiednikiem instrukcji maszynowych. Podczas procesu translacji instrukcje asemblera są konwertowane na odpowiednie polecenia zestawu instrukcji mikroprocesora. Jedna instrukcja asemblera z reguły odpowiada jednej instrukcji mikroprocesora, co ogólnie rzecz biorąc jest typowe dla języków niskiego poziomu. Oto przykład instrukcji, która zwiększa liczbę binarną zapisaną w rejestrze eax o jeden: wliczając w to ▪ макрокоманды - оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями. Przykładem makra jest następujące makro końca programu: wyjdź z makra movax, 4c00h int 21h koniec ▪ директивы, являющиеся указанием транслятору ассемблера на выполнение некоторых действий. Dyrektywy nie mają odpowiedników w reprezentacji maszynowej; Jako przykład, oto dyrektywa TITLE, która ustawia tytuł pliku z listą: %TITLE "Lista 1" ▪ строки комментариев, содержащие любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором. Пример: ; ta linia jest komentarzem 48. Składnia zespołu Zdania tworzące program mogą być konstrukcją składniową odpowiadającą poleceniu, makro, dyrektywie lub komentarzowi. Aby tłumacz asemblera mógł je rozpoznać, muszą być uformowane zgodnie z pewnymi regułami składniowymi. W tym celu najlepiej jest użyć formalnego opisu składni języka, podobnie jak zasad gramatyki. Najczęstszymi sposobami opisu języka programowania w ten sposób są diagramy składni i rozszerzone formularze Backusa-Naura. Podczas pracy z diagramami składni zwracaj uwagę na kierunek przechodzenia wskazany przez strzałki. Diagramy składni odzwierciedlają logikę tłumacza podczas analizowania zdań wejściowych programu. Prawidłowe znaki: 1) wszystkie litery łacińskie: A - Z, a - z; 2) liczby od 0 do 9; 3) znaki? @, $, &; 4) separatory. Żetony są następujące. 1. Identyfikatory - ciągi prawidłowych znaków używane do oznaczenia kodów operacji, nazw zmiennych i nazw etykiet. Identyfikator nie może zaczynać się od cyfry. 2. Łańcuchy znaków - ciągi znaków ujęte w pojedyncze lub podwójne cudzysłowy. 3. Liczby całkowite. Możliwe typy instrukcji asemblera. 1. Operatory arytmetyczne. Obejmują one: 1) jednoargumentowe „+” i „-”; 2) binarne „+” i „-”; 3) mnożenie „*”; 4) dzielenie liczb całkowitych „/”; 5) получения остатка от деления "mod". 2. Operatory przesunięcia przesuwają wyrażenie o określoną liczbę bitów. 3. Operatory porównania (zwróć „prawda” lub „fałsz”) są przeznaczone do tworzenia wyrażeń logicznych. 4. Operatory logiczne wykonują operacje bitowe na wyrażeniach. 5. Operator indeksu [XNUMX]. 6. Operator redefinicji typu ptr służy do przedefiniowania lub zakwalifikowania typu etykiety lub zmiennej zdefiniowanej przez wyrażenie. 7. Operator redefinicji segmentu ":" (dwukropek) powoduje obliczenie adresu fizycznego względem określonego składnika segmentu. 8. Operator nazewnictwa typu struktury "." (kropka) powoduje również, że kompilator wykonuje pewne obliczenia, jeśli występuje w wyrażeniu. 9. Operator uzyskiwania składowej segmentu adresu wyrażenia seg zwraca fizyczny adres segmentu dla wyrażenia, którym może być etykieta, zmienna, nazwa segmentu, nazwa grupy lub jakaś nazwa symboliczna. 10. Operator do uzyskania przesunięcia wyrażenia offset pozwala uzyskać wartość przesunięcia wyrażenia w bajtach względem początku segmentu, w którym zdefiniowane jest wyrażenie. 49. Dyrektywy segmentacyjne Segmentacja jest częścią bardziej ogólnego mechanizmu związanego z koncepcją programowania modułowego. Polega ona na ujednoliceniu konstrukcji modułów obiektowych tworzonych przez kompilator, w tym pochodzących z różnych języków programowania. Pozwala to na łączenie programów napisanych w różnych językach. Operandy w dyrektywie SEGMENT przeznaczone są do implementacji różnych opcji takiej unii. Rozważ je bardziej szczegółowo. 1. Atrybut wyrównania segmentu (typ wyrównania) mówi linkerowi, aby upewnił się, że początek segmentu jest umieszczony na określonej granicy: 1) BYTE - wyrównanie nie jest wykonywane; 2) WORD - segment zaczyna się od adresu będącego wielokrotnością dwóch, tzn. ostatni (najmniej znaczący) bit adresu fizycznego to 0 (wyrównany do granicy słowa); 3) DWORD - segment zaczyna się od adresu będącego wielokrotnością czterech; 4) PARA - segment zaczyna się od adresu będącego wielokrotnością 16; 5) PAGE - segment rozpoczyna się pod adresem będącym wielokrotnością 256; 6) MEMPAGE - segment rozpoczyna się od adresu będącego wielokrotnością 4 KB. 2. Atrybut łączenia segmentów (typ kombinatoryczny) mówi linkerowi, jak połączyć segmenty różnych modułów, które mają tę samą nazwę: 1) PRYWATNY - segment nie będzie łączony z innymi segmentami o tej samej nazwie poza tym modułem; 2) PUBLIC - wymusza na linkerze połączenie wszystkich segmentów o tej samej nazwie; 3) WSPÓLNY - posiada wszystkie segmenty o tej samej nazwie pod tym samym adresem; 4) AT xxxx – lokalizuje segment pod bezwzględnym adresem paragrafu; 5) STACK - definicja segmentu stosu. 3. Atrybut klasy segmentu (typ klasy) to łańcuch w cudzysłowie, który pomaga konsolidatorowi określić odpowiednią kolejność segmentów podczas asemblacji programu z wielu segmentów modułów. 4. Atrybut rozmiaru segmentu: 1) USE16 - oznacza to, że segment umożliwia adresowanie 16-bitowe; 2) USE32 - segment będzie 32-bitowy. Musi być jakiś sposób na zrekompensowanie niemożliwości bezpośrednio kontrolować rozmieszczenie i kombinację segmentów. Aby to zrobić, zaczęli używać dyrektywy do określenia modelu pamięci MODEL. Ta dyrektywa wiąże segmenty, które w przypadku stosowania uproszczonych dyrektyw segmentacji mają predefiniowane nazwy, z rejestrami segmentowymi (chociaż nadal trzeba jawnie zainicjować ds.). Obowiązkowym parametrem dyrektywy MODEL jest model pamięci. Ten parametr definiuje model segmentacji pamięci dla modułu. Zakłada się, że moduł programu może zawierać tylko pewne typy segmentów, które są zdefiniowane przez dyrektywy uproszczonego opisu segmentów, o których wspominaliśmy wcześniej. 50. Struktura instrukcji maszyny Polecenie maszynowe jest zakodowanym zgodnie z pewnymi regułami sygnałem dla mikroprocesora, aby wykonać jakąś operację lub czynność. Każde polecenie zawiera elementy, które definiują: 1) co robić? 2) obiekty, na których coś trzeba zrobić (te elementy nazywane są operandami); 3) jak to zrobić? Maksymalna długość instrukcji maszynowej to 15 bajtów. 1. Przedrostki. Opcjonalne elementy instrukcji maszynowych, z których każdy ma 1 bajt lub może być pominięty. W pamięci komendy poprzedzają prefiksy. Celem prefiksów jest modyfikacja operacji wykonywanej przez polecenie. Aplikacja może używać następujących typów przedrostków: 1) przedrostek zastępujący segment; 2) prefiks długości bitu adresu określa długość adresu w bitach (32-bitowy lub 16-bitowy); 3) prefiks szerokości bitu operandu jest podobny do prefiksu szerokości bitu adresu, ale wskazuje długość bitu operandu (32- lub 16-bitową), z którą działa polecenie; 4) Prefiks powtarzania jest używany z poleceniami połączonymi. 2. Kod operacji. Wymagany element opisujący operację wykonywaną przez polecenie. 3. Tryb adresowania bajt modr/m. Wartość tego bajtu określa używaną formę adresu operandu. Operandy mogą znajdować się w pamięci w jednym lub dwóch rejestrach. Jeśli operand znajduje się w pamięci, to bajt modr/m określa składowe (rejestry offsetowe, bazowe i indeksowe) służy do obliczania jego efektywnego adresu. Bajt modr/m składa się z trzech pól: 1) pole mod określa liczbę bajtów zajmowanych w instrukcji przez adres argumentu; 2) pole reg/cop określa albo rejestr znajdujący się w poleceniu w miejsce pierwszego operandu, albo możliwe rozszerzenie opcode; 3) pole r/m jest używane w połączeniu z polem mod i określa albo rejestr znajdujący się w poleceniu w miejscu pierwszego argumentu (jeśli mod = 11), albo rejestry bazowy i indeksowy używane do obliczenia adresu efektywnego (wraz z polem przesunięcia w poleceniu). 4. Skala bajtów - indeks - podstawa (bajt sib). Służy do rozszerzenia możliwości adresowania operandów. Bajt sib składa się z trzech pól: 1) skala pól ss. To pole zawiera współczynnik skali dla indeksu składnika indeksowego, który zajmuje kolejne 3 bity bajtu sib; 2) pola indeksowe. Używany do przechowywania numeru rejestru indeksu używanego do obliczania efektywnego adresu operandu; 3) pola bazowe. Służy do przechowywania numeru rejestru podstawowego, który jest również używany do obliczania efektywnego adresu operandu. 5. Pole przesunięcia w poleceniu. 8-, 16- lub 32-bitowa liczba całkowita ze znakiem reprezentująca, w całości lub w części (z zastrzeżeniem powyższych rozważań), wartość efektywnego adresu operandu. 6. Pole operandu bezpośredniego. Opcjonalne pole reprezentujące 8-, 16- lub 32-bitowy operand natychmiastowy. Obecność tego pola ma oczywiście odzwierciedlenie w wartości bajtu modr/m. 51. Metody określania argumentów instrukcji Operand jest ustawiany niejawnie na poziomie oprogramowania układowego W takim przypadku instrukcja wyraźnie nie zawiera argumentów. Algorytm wykonania polecenia wykorzystuje niektóre domyślne obiekty (rejestry, flagi w flagach itp.). Operand jest określony w samej instrukcji (operand natychmiastowy) Operand znajduje się w kodzie instrukcji, to znaczy jest jego częścią. Do przechowywania takiego argumentu w instrukcji przydzielane jest pole o długości do 32 bitów. Operand bezpośredni może być tylko drugim (źródłowym) operandem. Operand przeznaczenia może znajdować się w pamięci lub w rejestrze. Operand znajduje się w jednym z rejestrów.Operandy rejestru są określone przez nazwy rejestrów. Rejestry mogą być używane: 1) 32-bitowe rejestry EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) 16-bitowe rejestry AX, BX, CX, DX, SI, DI, SP, BP; 3) 8-bitowe rejestry AH, AL, BH, BL, CH, CL, DH, DL; 4) rejestry segmentowe CS, DS, SS, ES, FS, GS. Na przykład polecenie add ax,bx dodaje zawartość rejestrów ax i bx i zapisuje wynik do bx. Polecenie dec si zmniejsza zawartość si o 1. Operand jest w pamięci Jest to najbardziej złożony i jednocześnie najbardziej elastyczny sposób określania operandów. Pozwala na realizację dwóch głównych typów adresowania: bezpośredniego i pośredniego. Z kolei adresowanie pośrednie ma następujące odmiany: 1) pośrednie adresowanie bazowe; inna jego nazwa to adresowanie pośrednie w rejestrze; 2) pośrednie adresowanie bazowe z offsetem; 3) pośrednie adresowanie indeksu z przesunięciem; 4) pośrednie adresowanie indeksu bazowego; 5) pośrednie adresowanie indeksu bazowego z przesunięciem. Operand to port I/O Oprócz przestrzeni adresowej RAM mikroprocesor utrzymuje przestrzeń adresową I/O, która jest używana do uzyskiwania dostępu do urządzeń I/O. Przestrzeń adresowa we/wy wynosi 64 KB. Adresy są przydzielane dla dowolnego urządzenia komputerowego w tej przestrzeni. Określona wartość adresu w tej przestrzeni nazywana jest portem we/wy. Fizycznie port I / O odpowiada rejestrowi sprzętowemu (nie mylić z rejestrem mikroprocesora), do którego dostęp uzyskuje się za pomocą specjalnych instrukcji asemblera. Operand jest na stosie Instrukcje mogą w ogóle nie mieć operandów, mogą mieć jeden lub dwa operandy. Większość instrukcji wymaga dwóch operandów, z których jeden jest operandem źródłowym, a drugim operandem docelowym. Ważne jest, aby jeden operand mógł znajdować się w rejestrze lub pamięci, a drugi operand musi znajdować się w rejestrze lub bezpośrednio w instrukcji. Operand bezpośredni może być tylko operandem źródłowym. W dwuargumentowej instrukcji maszynowej możliwe są następujące kombinacje argumentów: 1) rejestr - rejestr; 2) rejestr - pamięć; 3) pamięć - rejestr; 4) operand natychmiastowy - rejestr; 5) operand natychmiastowy - pamięć. 52. Metody adresowania Adresowanie bezpośrednie Jest to najprostsza forma adresowania operandu w pamięci, ponieważ adres efektywny jest zawarty w samej instrukcji i do jego utworzenia nie są używane żadne dodatkowe źródła ani rejestry. Adres efektywny jest pobierany bezpośrednio z pola offsetu instrukcji maszynowej, które może mieć 8, 16, 32 bity. Ta wartość jednoznacznie identyfikuje bajt, słowo lub podwójne słowo znajdujące się w segmencie danych. Adresowanie bezpośrednie może być dwojakiego rodzaju. Względne adresowanie bezpośrednie Używany w instrukcjach skoku warunkowego w celu wskazania względnego adresu skoku. Względność takiego przejścia polega na tym, że pole przesunięcia instrukcji maszynowej zawiera wartość 8-, 16- lub 32-bitową, która w wyniku działania instrukcji zostanie dodana do treści rejestr wskaźnika instrukcji ip/eip. W wyniku tego dodania uzyskuje się adres, do którego dokonywane jest przejście. Bezwzględne adresowanie bezpośrednie W tym przypadku adres efektywny jest częścią instrukcji maszynowej, ale adres ten jest tworzony tylko z wartości pola przesunięcia w instrukcji. Aby utworzyć fizyczny adres operandu w pamięci, mikroprocesor dodaje to pole z wartością rejestru segmentowego przesuniętą o 4 bity. Kilka form tego adresowania może być użytych w instrukcji asemblera. Pośrednie adresowanie podstawowe (rejestrowe) Przy takim adresowaniu efektywny adres operandu może znajdować się w dowolnym rejestrze ogólnego przeznaczenia, z wyjątkiem sp / esp i bp / ebp (są to rejestry specyficzne do pracy z segmentem stosu). Syntaktycznie w poleceniu ten tryb adresowania jest wyrażony przez umieszczenie nazwy rejestru w nawiasach kwadratowych []. Pośrednie adresowanie bazowe (rejestrowe) z przesunięciem Ten typ adresowania jest dodatkiem do poprzedniego i jest przeznaczony do dostępu do danych ze znanym przesunięciem względem jakiegoś adresu bazowego. Ten rodzaj adresowania jest wygodny w użyciu w celu uzyskania dostępu do elementów struktur danych, gdy przesunięcie elementów jest znane z góry na etapie tworzenia programu, a adres bazowy (początkowy) struktury musi być obliczany dynamicznie, co etap realizacji programu. Pośrednie adresowanie indeksu z przesunięciem Ten rodzaj adresowania jest bardzo podobny do pośredniego adresowania bazowego z przesunięciem. Tutaj również jeden z rejestrów ogólnego przeznaczenia jest używany do utworzenia adresu efektywnego. Ale adresowanie indeksów ma jedną interesującą cechę, która jest bardzo wygodna podczas pracy z tablicami. Wiąże się to z możliwością tzw. skalowania zawartości rejestru indeksowego. Pośrednie adresowanie indeksu bazowego W przypadku tego typu adresowania adres efektywny jest tworzony jako suma zawartości dwóch rejestrów ogólnego przeznaczenia: bazowego i indeksowego. Rejestry te mogą być dowolnymi rejestrami ogólnego przeznaczenia i często stosuje się skalowanie zawartości rejestru indeksowego. Pośrednie adresowanie indeksu bazowego z przesunięciem Ten rodzaj adresowania jest uzupełnieniem adresowania pośredniego indeksowanego. Adres efektywny jest tworzony jako suma trzech składowych: zawartości rejestru bazowego, zawartości rejestru indeksowego i wartości pola przesunięcia w instrukcji. 53. Polecenia przesyłania danych Ogólne polecenia przesyłania danych Ta grupa obejmuje następujące polecenia: 1) mov jest głównym poleceniem przesyłania danych; 2) xchg - używany do dwukierunkowego przesyłania danych. Polecenia wejścia/wyjścia portu Zasadniczo zarządzanie urządzeniami bezpośrednio przez porty jest łatwe: 1) w akumulatorze numer portu - wejście do akumulatora z portu wraz z numerem portu; 2) port wyjściowy, akumulator - wyprowadza zawartość akumulatora do portu o numerze portu. Polecenia konwersji danych Do tej grupy można przypisać wiele instrukcji mikroprocesorowych, ale większość z nich ma pewne cechy, które wymagają ich przypisania do innych grup funkcyjnych. Polecenia stosu Ta grupa to zestaw wyspecjalizowanych poleceń skoncentrowanych na organizowaniu elastycznej i wydajnej pracy ze stosem. Stos to obszar pamięci specjalnie przeznaczony do tymczasowego przechowywania danych programu. Stos ma trzy rejestry: 1) ss - rejestr segmentów stosu; 2) sp/esp - rejestr wskaźnika stosu; 3) bp/ebp - rejestr wskaźnika bazowego ramki stosu. Aby zorganizować pracę ze stosem, istnieją specjalne polecenia do pisania i czytania. 1. push source - zapisanie wartości źródłowej na górę stosu. 2. przypisanie pop - zapisanie wartości ze szczytu stosu do lokalizacji określonej przez operand docelowy. Wartość jest więc „usuwana” ze szczytu stosu. 3. pusha - grupowe polecenie zapisu na stos. 4. pushaw jest prawie synonimem polecenia pusha. Atrybutem bitness może być use16 lub use32. R 5. pushad - wykonywany podobnie do polecenia pusha, ale są pewne osobliwości. Następujące trzy polecenia wykonują odwrotność powyższych poleceń: 1) papa; 2) popawy; 3) pop. Grupa instrukcji opisanych poniżej umożliwia zapisanie rejestru flag na stosie i zapisanie słowa lub podwójnego słowa na stos. 1. pushf - zapisuje rejestr flag na stosie. 2. pushfw - zapisuje na stosie rejestr flag wielkości słowa. Zawsze działa jak pushf z atrybutem use16. 3. pushfd - zapisanie rejestru flag lub flag flag na stosie w zależności od atrybutu szerokości bitowej segmentu (tj. tak samo jak pushf). Podobnie, następujące trzy polecenia wykonują odwrotność operacji omówionych powyżej: 1) popf; 2) popfw; 3) popfd. 54. Polecenia arytmetyczne Takie polecenia działają z dwoma typami: 1) liczb binarnych całkowitych, czyli liczb zakodowanych w systemie liczb binarnych. Liczby dziesiętne to specjalny rodzaj reprezentacji informacji liczbowych, który opiera się na zasadzie kodowania każdej cyfry dziesiętnej liczby przez grupę czterech bitów. Mikroprocesor wykonuje dodawanie operandów zgodnie z zasadami dodawania liczb binarnych. W zestawie instrukcji mikroprocesora znajdują się trzy binarne instrukcje dodawania: 1) inc operand - zwiększ wartość operandu; 2) dodaj operand1, operand2 - dodawanie; 3) adc operand1, operand2 - dodanie, uwzględniające flagę przeniesienia por. Odejmowanie liczb binarnych bez znaku Jeśli odjemna jest większa niż odjemna, to różnica jest dodatnia. Jeśli odjemna jest mniejsza niż odjęta, pojawia się problem: wynik jest mniejszy niż 0, a to już jest liczba ze znakiem. Po odjęciu liczb bez znaku należy przeanalizować stan flagi CF. Jeśli jest ustawiony na 1, to najbardziej znaczący bit został zapożyczony, a wynik jest w kodzie dopełniającym do dwóch. Odejmowanie liczb binarnych ze znakiem Ale w przypadku odejmowania metodą dodawania liczb ze znakiem w dodatkowym kodzie konieczne jest przedstawienie obu operandów - zarówno odjemnika, jak i odjemnika. Wynik należy również traktować jako wartość dopełnienia do dwóch. Ale tutaj pojawiają się trudności. Przede wszystkim są one związane z faktem, że najbardziej znaczący bit operandu jest uważany za bit znaku. Zgodnie z treścią flagi przepełnienia. Ustawienie go na 1 wskazuje, że wynik jest poza zakresem liczb ze znakiem (tj. najbardziej znaczący bit się zmienił) dla operandu o tym rozmiarze, a programista musi podjąć działania, aby poprawić wynik. Zasada odejmowania liczb z zakresem reprezentacji przekraczającym standardowe siatki bitowe argumentów jest taka sama, jak przy dodawaniu, tj. stosowana jest flaga przeniesienia cf. Wystarczy wyobrazić sobie proces odejmowania w kolumnie i poprawnie połączyć instrukcje mikroprocesora z instrukcją sbb. Polecenie mnożenia liczb bez znaku to mnożnik_1 Polecenie mnożenia liczb ze znakiem to [imul operand_1, operand_2, operand_3] Polecenie div divisor służy do dzielenia liczb bez znaku. Polecenie idiv divisor służy do dzielenia liczb ze znakiem. 55. Polecenia logiczne Zgodnie z teorią na instrukcjach (na bitach) można wykonać następujące operacje logiczne. 1. Negacja (logiczne NIE) - operacja logiczna na jednym operandzie, której wynikiem jest odwrotność wartości oryginalnego operandu. 2. Dodawanie logiczne (logiczne LUB) - operacja logiczna na dwóch operandach, której wynikiem jest „prawda” (1), jeśli jeden lub oba operandy są prawdziwe (1) i „fałsz” (0), jeśli oba operandy są fałszywe (0). 3. Mnożenie logiczne (logiczne AND) - operacja logiczna na dwóch operandach, której wynik jest prawdziwy (1) tylko wtedy, gdy oba operandy są prawdziwe (1). We wszystkich innych przypadkach wartość operacji to „fałsz” (0). 4. Logiczne wykluczające dodawanie (logiczne wykluczające OR) - operacja logiczna na dwóch operandach, której wynikiem jest „prawda” (1), jeśli tylko jeden z dwóch operandów jest prawdziwy (1), a fałszywy (0), jeśli oba operandy są albo fałszywe (0), albo prawdziwe (1). 4. Logiczne wykluczające dodawanie (logiczne wykluczające OR) - operacja logiczna na dwóch operandach, której wynikiem jest „prawda” (1), jeśli tylko jeden z dwóch operandów jest prawdziwy (1), a fałszywy (0), jeśli oba operandy są albo fałszywe (0), albo prawdziwe (1). Poniższy zestaw poleceń wspierających pracę z danymi logicznymi: 1) i operand_1, operand_2 - operacja mnożenia logicznego; 2) lub operand_1, operand_2 - operacja dodawania logicznego; 3) xor operand_1, operand_2 - operacja logicznego dodawania wykluczającego; 4) test operand_1, operand_2 - operacja "testowa" (przez mnożenie logiczne) 5) nieoperand - operacja logicznej negacji. a) aby ustawić pewne cyfry (bity) na 1, używa się polecenia lub operandu_1, operandu_2; b) aby zresetować pewne cyfry (bity) do 0, używa się polecenia i operandu_1, operandu_2; c) zastosowano polecenie xor operand_1, operand_2: ▪ для выяснения того, какие биты в операнд_1 и операнд_2 различаются; ▪ для инвертирования состояния заданных бит в операнд_1. Polecenie testowe operand_1, operand_2 (sprawdzenie operandu_1) służy do sprawdzania statusu określonych bitów. Wynikiem polecenia jest ustawienie wartości flagi zerowej zf: 1) jeżeli zf = 0, to w wyniku mnożenia logicznego uzyskano wynik zerowy, tj. jeden jednostkowy bit maski, który nie odpowiadał odpowiadającemu jednostkowemu bitowi argumentu 1; 2) если zf = 1, то в результате логического умножения получился ненулевой результат, т. е. хотя бы один единичный бит маски совпал с соответствующим единичным битом операнд1. Все команды сдвига перемещают биты в поле операнда влево или вправо в зависимости от кода операции. Все команды сдвига имеют одинаковую структуру - коп операнд, счетчик сдвигов. 56. Polecenia transferu sterowania Którą instrukcję programu należy wykonać następnie, mikroprocesor dowiaduje się z zawartości cs: (e) pary rejestrów ip: 1) cs - rejestr segmentu kodu, który zawiera adres fizyczny bieżącego segmentu kodu; 2) eip/ip - rejestr wskaźnika instrukcji, zawiera wartość przesunięcia w pamięci następnej instrukcji do wykonania. Bezwarunkowe skoki To, co należy zmodyfikować, zależy od: 1) o rodzaju argumentu w bezwarunkowej instrukcji oddziałowej (bliski lub daleki); 2) od określenia modyfikatora przed adresem przejścia; w tym przypadku sam adres skoku może znajdować się albo bezpośrednio w instrukcji (skok bezpośredni) albo w rejestrze pamięci (skok pośredni). Wartości modyfikatora: 1) near ptr - bezpośrednie przejście do etykiety; 2) far ptr - bezpośrednie przejście do etykiety w innym segmencie kodu; 3) słowo ptr - pośrednie przejście do etykiety; 4) dword ptr - pośrednie przejście do etykiety w innym segmencie kodu. jmp instrukcja skoku bezwarunkowego jmp [modyfikator] jump_address Procedura lub podprogram jest podstawową jednostką funkcjonalną rozkładu jakiegoś zadania. Procedura to grupa poleceń. Skoki warunkowe Mikroprocesor posiada 18 instrukcji skoku warunkowego. Te polecenia pozwalają sprawdzić: 1) отношение между операндами со знаком ("больше - меньше"); 2) relacja między niepodpisanymi operandami ("выше - ниже"); 3) состояния арифметических флагов ZF, SF, CF, OF, PF (но не AF). Instrukcje skoku warunkowego mają tę samą składnię: etykieta skoku jcc Polecenie cmp Compare ma ciekawy sposób działania. Jest to dokładnie to samo co polecenie odejmowania - sub operand_1, operand_2. Polecenie cmp, podobnie jak polecenie sub, odejmuje operandy i ustawia flagi. Jedyne, czego nie robi, to zapisanie wyniku odejmowania w miejscu pierwszego operandu. Składnia polecenia cmp — cmp operand_1, operand_2 (porównaj) — porównuje dwa operandy i ustawia flagi na podstawie wyników porównania. Organizacja cykli Możesz zorganizować cykliczne wykonywanie określonej sekcji programu, na przykład za pomocą warunkowego przesyłania poleceń sterujących lub bezwarunkowego polecenia skoku jmp: 1) etykieta przejścia pętli (Loop) - powtórz pętlę. Polecenie pozwala organizować pętle podobne do pętli for w językach wysokiego poziomu z automatycznym zmniejszaniem licznika pętli; 2) etykieta skoku pętli/pętli Polecenia loope i loopz są bezwzględnymi synonimami; 3) etykieta skoku loopne/loopnz Polecenia loopne i loopnz są również bezwzględnymi synonimami. Polecenia loope/loopz i loopne/loopnz działają odwrotnie. Autor: Tsvetkova A.V.
▪ Kontrola i weryfikacja. Kołyska ▪ Teoria rządu i praw. Notatki do wykładów ▪ Literatura rosyjska XIX wieku w skrócie. Kołyska
Otwarto najwyższe obserwatorium astronomiczne na świecie
04.05.2024 Sterowanie obiektami za pomocą prądów powietrza
04.05.2024 Psy rasowe chorują nie częściej niż psy rasowe
03.05.2024
▪ Wytrzymały smartfon Oukitel WP21 ▪ Transmisja danych z mózgu do komputera przez żyły ▪ Laser wielkości cząsteczki wirusa ▪ Folia antybakteryjna do powierzchni domowych
▪ sekcja strony Aforyzmy znanych osób. Wybór artykułu ▪ artykuł Który kraj zabrania pracy zbyt szczupłym modelkom? Szczegółowa odpowiedź ▪ artykuł Klej przewodzący prąd elektryczny. Wskazówki dotyczące szynki ▪ Artykuł o projektowaniu głośników. Encyklopedia elektroniki radiowej i elektrotechniki
Strona główna | biblioteka | Artykuły | Mapa stony | Recenzje witryn
www.diagram.com.ua |


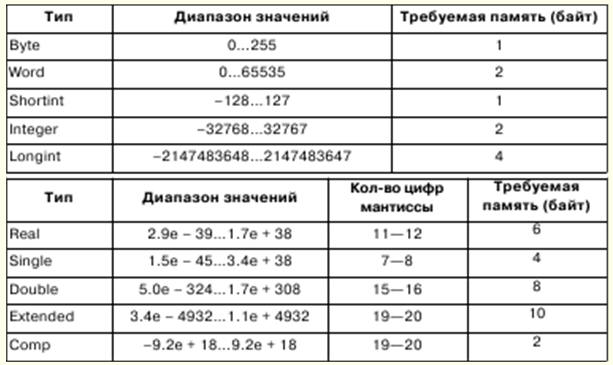

 Zobacz inne artykuły Sekcja
Zobacz inne artykuły Sekcja 